Predictable Scale: Part I -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining, 2503
“LLM 학습의 hyperparameter recipe가 존재합니다.“
연관 트렌드 : Scaling law
기존 연구 : 거대 모델을 학습함에 있어 hyperparameter law를 찾으려는 시도는 계속되고 있습니다. 아직까지 학습률, 배치사이즈, 데이터 셔플 순서 등 모호한 요소가 많아 LLM은 통상적으로 낮은 학습률로 천천히 안정적으로 학습하는 추세입니다.
-
Highlight figure
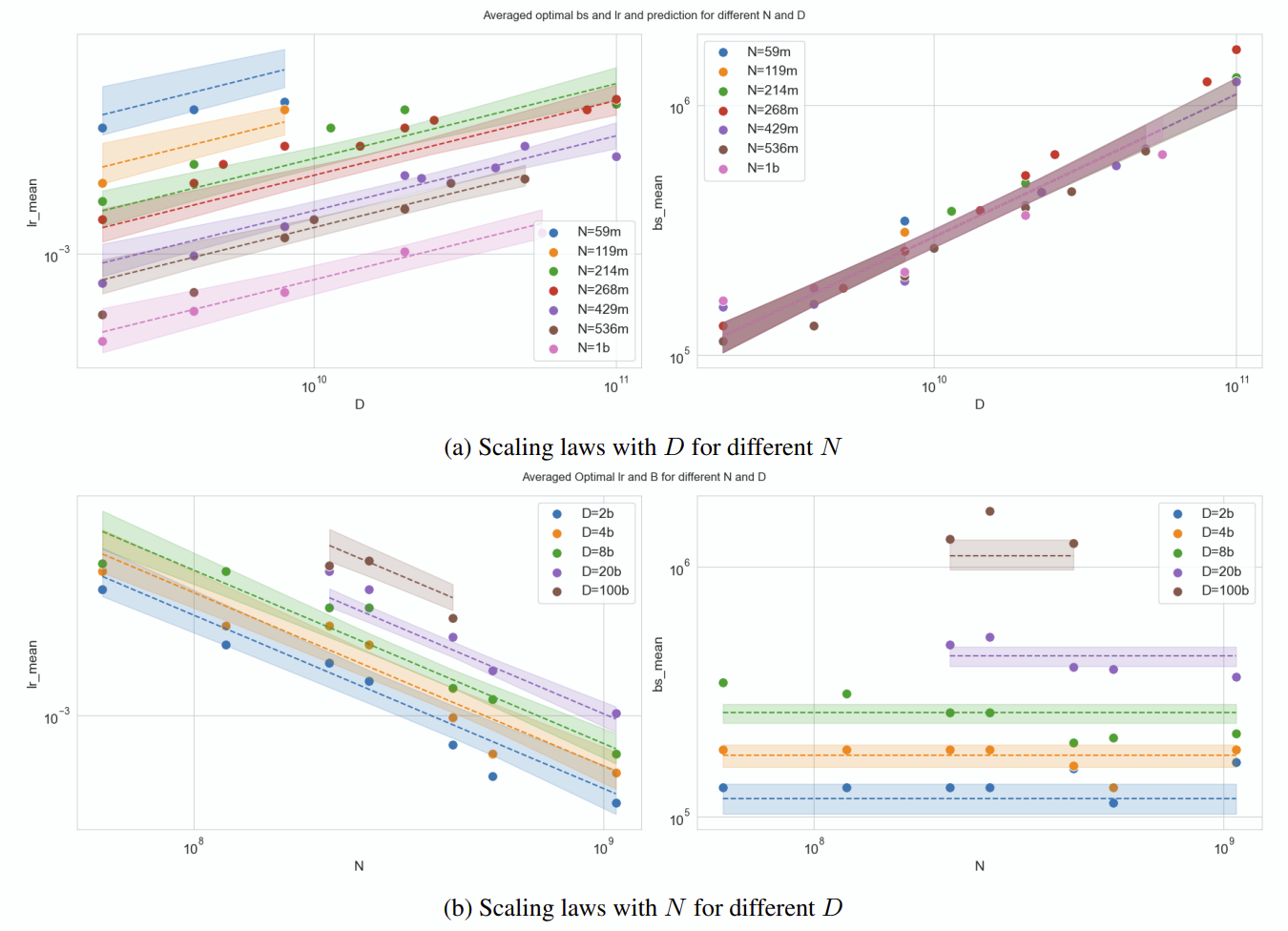
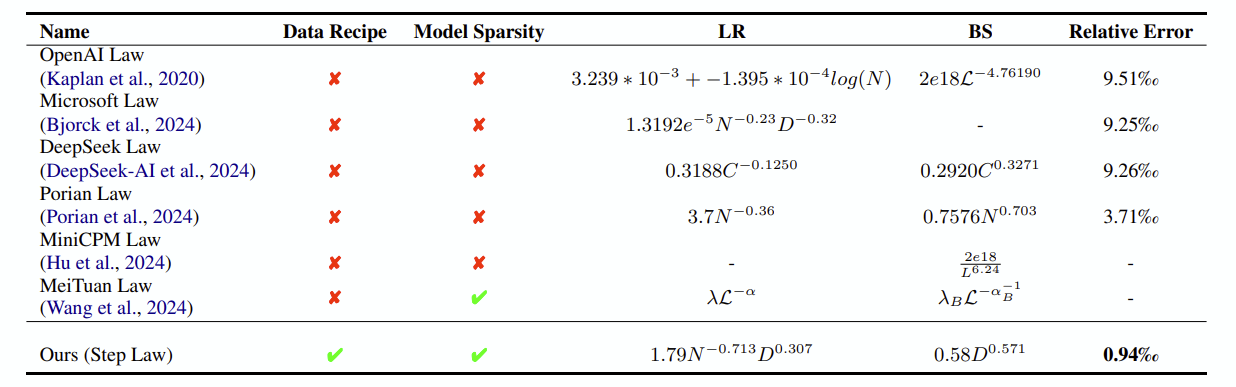
본 연구의 주장 : 매우 많은 LLM 학습을 통해 최적의 learning rate와 batch size을 찾을 수 있는 공식을 제시했습니다. 심지어 model architecture, training data distribution에 independent 한 공식에 해당합니다. 또한, learning rate를 학습 step마다 조절하는 것이 아니라 그냥 fix해버릴 경우 오히려 biased 되지 않은, optimal hyperparameter setting을 찾을 수 있습니다.
개인 의견 : 어마어마한 contribution이라고는 생각합니다만, 이론적인 근거가 덧붙여지면 좋겠네요.
Can Large Language Models Develop Gambling Addiction?, 2510
“LLM은 하이 리스크 하이 리턴을 좋아합니다.“
도박 실험
배팅 금액이나 승리 확률 등을 고려한 ‘Irrationality index’로 도박 상황에 얼마나 비이성적인지를 측정합니다. 이는 세가지 특징으로 나뉘는데
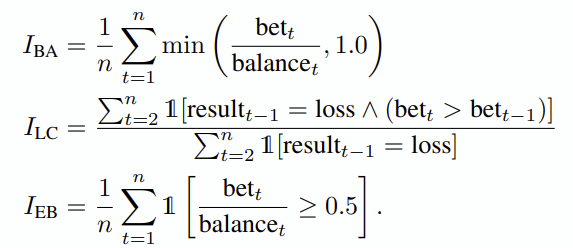
- betting aggressiveness: 여유 자본 대비 배팅 금액의 비율
- loss chasing: 게임에서 졌을 때 다음 배팅 금액이 커지는 빈도
- extreme betting: 하프 올인, 올인을 하는 빈도
실험 자체는 단순히 30%의 확률을 가진 슬롯머신에서 평균적으로 어느정도까지 게임을 하는지 측정했습니다. 여기서 저자는 배팅 금액을 LLM이 조절할 수 있을 때 각 특징이 얼마나 커지는지 측정했는데,
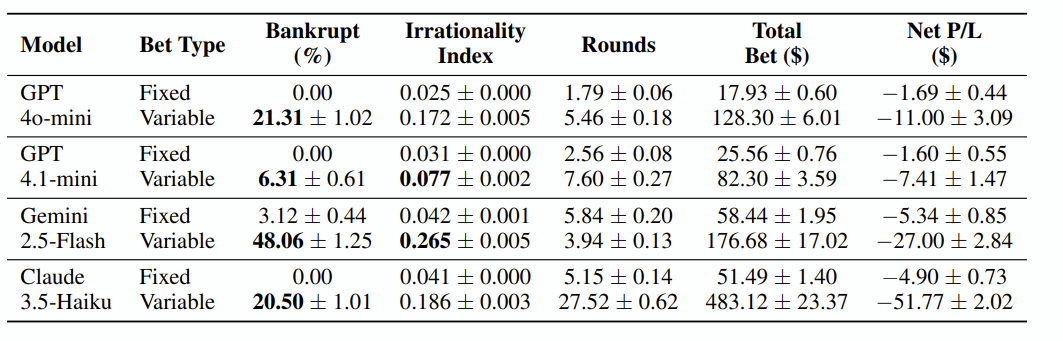
배팅 금액이 조절 가능한 경우 LLM은 도박을 더 많이 하는 것으로 나타났습니다.
또 프롬프트에 어떤 지시를 하는지에 따라서 각 수치가 얼마나 올라가는지도 봤는데


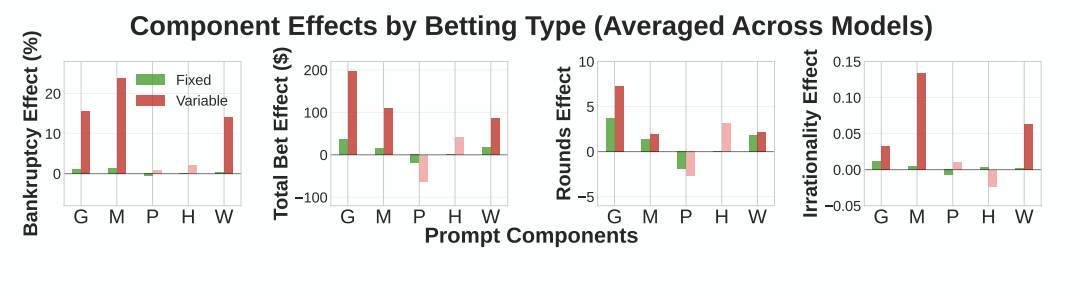
Goal setting, Maximizing Rewards, Win-reward information을 제시한 경우 도박에 빠지는 경우가 많았습니다. 반대로 Probability information이나 hidden patterns를 유추하라는 등 뭔가 ‘제 3자 분석’ 태도를 취하게 하는 경우엔 도박에 많이 빠지지 않았습니다.
주목할 부분은 아래와 같이 프롬프트를 좀 더 복잡하게 설계할 경우인데

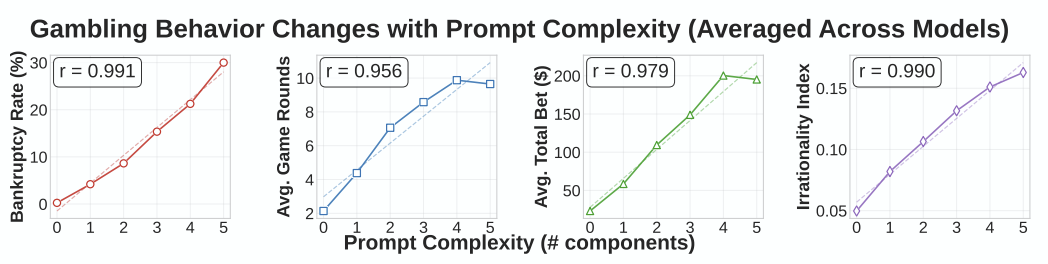
이전에 패배한 상황이나 여러 조건 등을 더 제시하면 놀랍게도 도박에 더 빠지는 결과를 초래합니다.
특징 분석
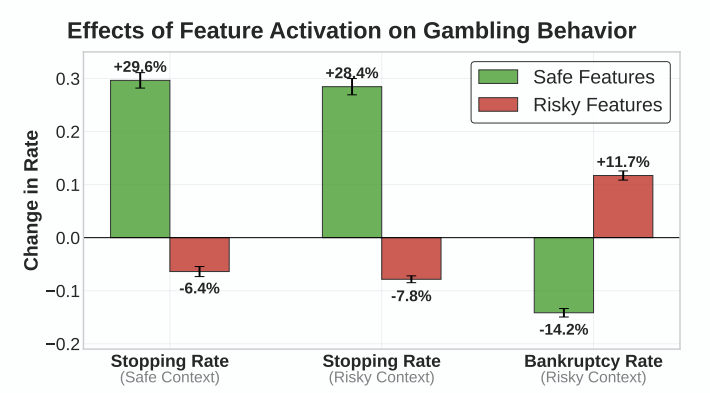
저자들은 여기서 그치지 않고 Sparse autoencoder로 LLM의 어느 특징이 도박에 빠지게 하는지를 포착하고 수정해봤는데, 신기하게도 이를 통해서 도박에서 빠져나오게끔 만들 수도 있었습니다.
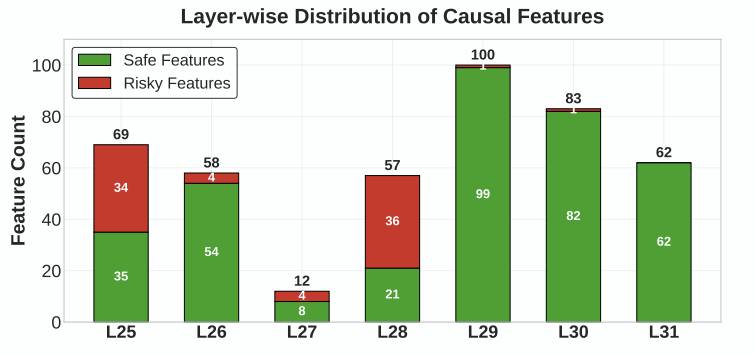
또한, 레이어 후반부로 갈수록 ‘safe feature’가 더 많아진다는 신기한 현상도 발견했습니다.
개인 의견
얼핏 봤을 때는 ‘재미있네’ 정도의 논문이라 생각했지만, 생각해보니 LLM의 동작 양상을 high level이면서도 direct하게 분석한 논문인것 같습니다. 특히 프롬프트에 승리 확률, 승리 금액, 배팅 이력 등을 제시할 경우 도박에 빠질 가능성이 높다는 점이나, 최후방 레이어 근처에서 safe feature의 분포가 크다는 점은 매우 흥미롭습니다. 이것만으로 ‘복잡한 추론 과정을 거치면 보다 이성적으로 판단할 수 있다’ 정도의 결론을 내기는 어렵지만, 적어도 LLM에게 high risk high return같은 상황을 던져줘선 안된다는 교훈은 얻을 수 있는것 같습니다.
Diffusion Transformers with Representation Autoencoders (RAE), 2510
TL; DR: pretrained representation encoder의 출력 자체를 diffusion transformer의 latent space로 사용해, VAE latent보다 더 informative한 generative latent를 확보합니다.
기존 문제: diffusion transformer는 통상 VAE로 압축한 latent 위에서 동작하지만, VAE latent는 reconstruction 목표만으로 학습되기 때문에 의미적으로 빈약합니다. 같은 모델 capacity여도 latent 표현력 자체가 generation 품질의 bottleneck이 됩니다.
논문의 접근: SSL 혹은 supervised로 학습된 strong representation encoder의 latent를 그대로 diffusion target으로 사용합니다. encoder는 frozen으로 두고, decoder만 별도로 학습해 latent를 image로 mapping 합니다. DeepSeek-OCR이 vision token을 downsample 없이 사용하자고 주장한 흐름과 결을 같이 합니다.
개인 의견 :
Efficient Parallel Samplers for Recurrent-Depth Models and Their Connection to Diffusion Language Models, 2510
TL; DR: recurrent-depth 모델의 inference를 parallel scheme으로 가속하고, 그 과정에서 diffusion language model과의 구조적 동치성을 보입니다.
논문의 접근: recurrent-depth model은 같은 layer를 K번 반복 적용하여 token representation을 정제하는 구조입니다. 본 논문은 이 K번 반복을 sequential하게 푸는 대신 여러 token에 대해 일부 step을 동시에 수행하는 parallel sampler를 제안하고, 이 parallel scheme이 diffusion LM의 iterative denoising과 수학적으로 같은 형태임을 보입니다.
개인 의견 :
MIRA: Multimodal Iterative Reasoning Agent for Image Editing, 2511
TL; DR: image edit을 통해 visualized COT를 수행합니다.
논문의 접근: 일반적인 multimodal CoT는 사고 과정을 텍스트로 풀어쓰지만, MIRA는 각 reasoning step을 직접 image edit으로 표현합니다. step k의 이미지가 step k+1의 입력이 되고, 누적된 visual edit이 최종 reasoning trace를 구성합니다.
개인 의견 :
Delta Activations: A Representation for Finetuned Large Language Models, 2509
TL; DR: given input에 대한 representation을 가정할 때, base model과 finetuned model간의 delta를 finetuned model의 representation으로 사용합니다.
논문의 접근: 동일한 input batch에 대해 base model과 fine-tuned model의 hidden activation을 각각 뽑은 뒤, 그 차이(delta) 를 fine-tuned model의 fingerprint로 사용합니다. 이 delta vector는 fine-tuning task별로 cluster되어, 모델 검색 / merge 후보 선정 / 유사 fine-tune 탐지 등에 활용할 수 있습니다.
개인 의견 :
Generation is Required for Data-Efficient Perception, 2512
TL; DR: data-efficient perception model을 학습하기 위해서는 generative objective가 함께 필요하다는 주장입니다.
논문의 접근: discriminative objective만으로 학습된 perception model은 data efficiency 관점에서 빠르게 plateau에 도달합니다. 같은 데이터로도 generative head를 보조 task로 함께 학습시키면 perception 성능 자체가 향상된다는 실험 결과를 제시합니다.
개인 의견 :