Backgrounds
- Neural ODE (NeurIPS 2018) https://arxiv.org/pdf/1806.07366
-
기존 문제
gradient-based learning 방법론이나 모델이 복잡해짐에 따라, monte carlo와 같은 고전적인 approximation은 수학적 이론과 실제 구현된 내용간의 괴리를 점점 증가시켜 왔습니다. 특히 ELBO와 같은 방법은 가상의 확률분포함수를 가정하는 등 수식 유도 과정 안에서도 몇가지 assumption을 포함하기 때문에, 최종적으로 모델이 학습해야 하는 loss function은 이론적으로 매끄럽지 않게 유도되기도 합니다.
그나마 이를 미분방정식으로 해결할 수 있다는 단서는 있었지만, 초기조건에 의해 값이 결정되는 특성상 기존의 backprop으로 parameter를 update할 수 없다는 장벽이 있습니다.
-
논문이 이끌어낸 직관
기존의 신경망 레이어 계산 방법을 다음과 같이 일반화한다면, 다음과 같이 t는 discrete space에 존재합니다.
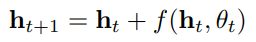
t를 continuous space로 놓고, dt로 변환한다면 다음과 같이 편미분 형태로 문제를 전환할 수 있습니다.
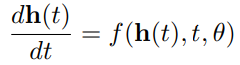
그리고 reverse ODE를 만들어, 초기조건을 역으로 풀어내는 방법으로 Loss를 계산합니다.
미분방정식(ODE)을 적용하면 continuous timestep을 사용할 수 있으므로, 이론과 현실을 더 매끄럽게 연결할 수 있습니다.
-
구체적인 방법
given 초기 조건 t_0에서, h(t_1)은
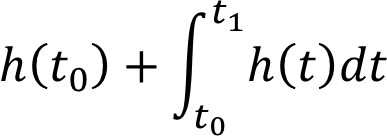
이 일체의 과정을 ODESolve 라는 함수로 정의하여, 논문에서는 다음과 같이 전반적인 loss 계산을 표현합니다.
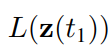
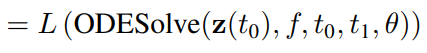
문제는 일반적인 backprop의 경우 최종 loss를 줄이는 gradient를 계산하기 위해, gradient를 누적하여 초기 상태까지 업데이트 해야하지만, 반대로 미분방정식에서는 초기조건에 의해 2번째부터 마지막까지의 값이 결정됩니다.
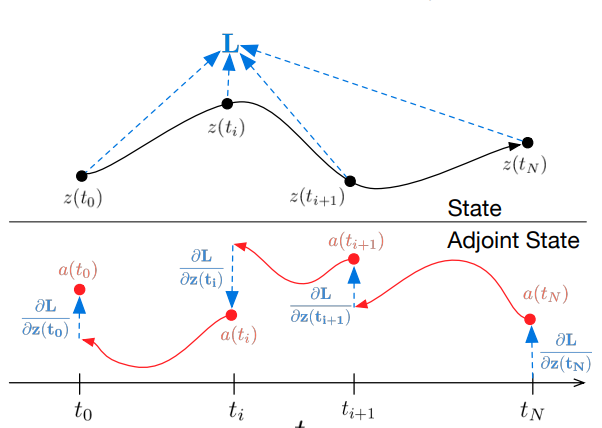
일단은 이 문제를 해결하기 위해 다음과 같이 ‘adjoint’ 를 정의합니다.
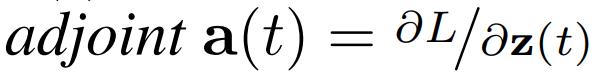
이를 통해 Loss를 감소시키기 위해 z(t)가 어떻게 변화해야 할지(gradient)를 계산할 수 있습니다.
그런데 이걸 t에 대한 편미분으로 변환하면 다음과 같이 정의됩니다.
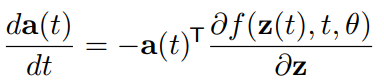
이 ODE 형태는 반대로 제일 마지막 시점이 초기조건이 되므로, 마지막 시점에서 처음 시점으로 돌아가며 매 t 시점마다 발생한 da(t)/dt 를 계산할 수 있습니다.
즉, a(t)를 통해 Loss를 감소시키기 위한 z(t)의 gradient를 approximate할 수 있으므로, z(t)의 초기조건 문제를 해결함과 동시에 forward & reverse 계산 및 t 시점 크기만큼의 메모리만으로 신경망 학습 방법을 구현할 수 있습니다.
-
활용방안 및 향후 연구(개인적 의견)
RL이 대표적인 활용예시로 볼 수 있는데, 실시간 정보에 따라 다른 전략을 취해야 하는 게임 (예를 들어 스타크래프트나 롤) 의 경우 static, fixed time delta 등을 적용한 거대한 모델보다는, DE가 훨씬 유리하고 심지어 학습속도도 빠릅니다. ODE를 활용한 diffusion은 이미지가 continuous value로 구성된다는 점에 착안해 나온 연구입니다. 다만 NLP/LLM에서는, 언어는 discrete하다는 특성 떄문에, 다소 실험적이거나 지엽적 접근 정도만이 적용되었습니다.
-
Methodologies
Legendre Memory Units: Continuous-Time Representation in Recurrent Neural Networks (NeurIPS 2019)
기존 문제 : LSTM은 RNN에 비해 개선된 모델로, 매 timestep마다 memory cell이라는 보조장치를 활용하는데, timestep 자체가 continuous하지 않으므로 활용 여지에 제한이 있었습니다.
Efficiently Modeling Long Sequences with Structured State Spaces (ICLR 2022)
기존 문제 : 딥러닝 모델은 필연적으로 long-range dependencies 문제를 가지게 됩니다. Recurrent model의 경우 gradient vanishment가 발생하고, transformer model의 경우 input length에 따라 quadratic computation이 발생합니다. HiPPO처럼 ODE 기반 long-term memory를 제안한 연구가 있었지만, 학습 시 ODE solver의 computational cost가 커서 large-scale로 확장하기 어려웠습니다.
논문이 이끌어낸 직관 :
-
Highlight figure
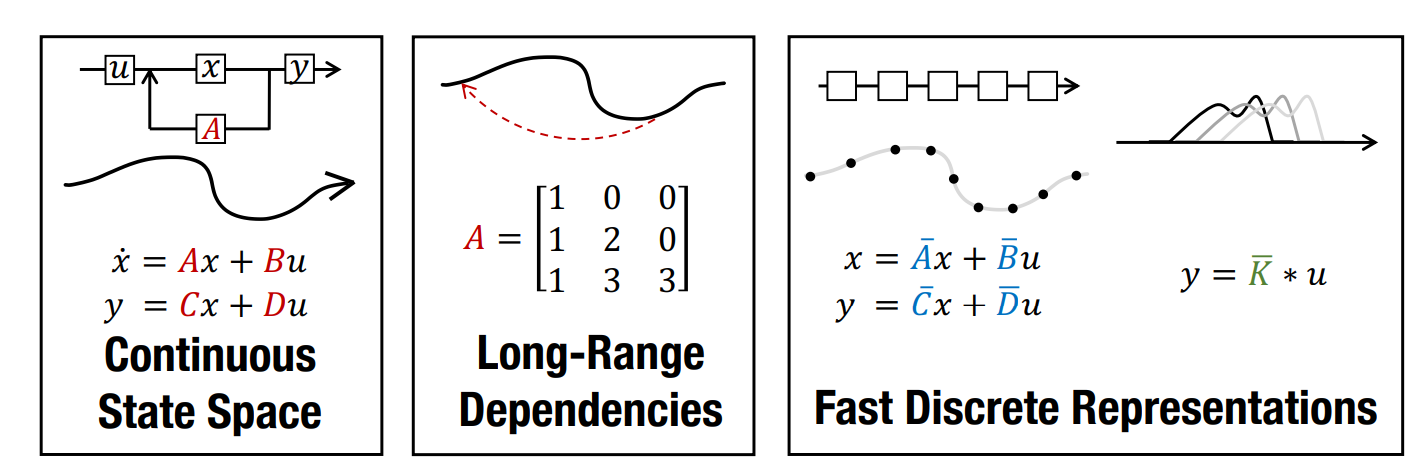
Transformer architecture은 language, vision, 심지어는 protein structure까지 예측할 만큼, 딥러닝 모델로써는 굉장히 범용성이 높은 모델입니다. 그런데 이 말을 반대로 하자면, inductive bias가 거의 없는 구조이기 때문에 특정 작업에 특화하기에는 어느정도 계산량(fine-tuning)이 필요한 구조입니다. 특히 입력 길이에 따라 quadratic하게 계산량이 올라가기 때문에, 이를 customize하거나 대체하려는 시도는 계속해서 있어왔습니다.
관련 연구 : State-space model, HiPPO, Linear State Space Layer (LSSL).
S4의 핵심 아이디어는 ODE를 그대로 푸는 대신, state matrix A를 normal-plus-low-rank 형태로 제약하여 convolution kernel을 closed-form으로 표현 가능하게 만드는 것입니다. 이렇게 하면 sequence 전체에 걸친 SSM의 output을 FFT 한 번으로 계산할 수 있어, recurrent 구조 그대로 학습은 parallel하게 진행할 수 있습니다.
추론 시에는 동일한 모델을 recurrent form으로 재해석하여 token 단위 streaming inference도 가능합니다. 즉 학습은 transformer만큼 parallel, 추론은 RNN만큼 efficient한 hybrid 동작이 핵심 contribution입니다.
Long Range Arena benchmark (https://arxiv.org/abs/2011.04006) 의 Path-X (16k length) task에서, 기존 transformer 변형들이 chance level (50%) 에 머무르던 것을 처음으로 96% 이상으로 끌어올린 연구입니다.
활용방안 및 향후 연구(개인적 의견) :
Applications
HiPPO: Recurrent Memory with Optimal Polynomial Projections (ICLR 2020)
기존 문제 : 딥러닝 모델은 필연적으로 long-range dependencies 문제를 가지게 됩니다. Long-range dependencies는 어떤 previous time step의 state에 가중치를 둘지, 매 time step마다 어떤 함수를 적용할지 등 접근해볼만한 아이디어는 많지만 이론적으로 설명하기 매우 어렵습니다. 그나마 neural ODE(Ordinary differential equation) 등 논문이 나오면서 ODE를 통한 long-range dependencies를 timestep에 따라 dynamic하게 처리하는 방법이 제안된 바 있지만, ODE 자체가 생소한 개념이다보니 (당시에는) 딥러닝에 실제 활용된 케이스는 많이 없었습니다.
논문이 이끌어낸 직관 : 과거 정보 전체를 polynomial basis로 projection하여 유한 차원 vector에 압축할 수 있다면, long-term memory를 ODE 형태의 update rule로 정형화할 수 있습니다.
-
Highlight figure
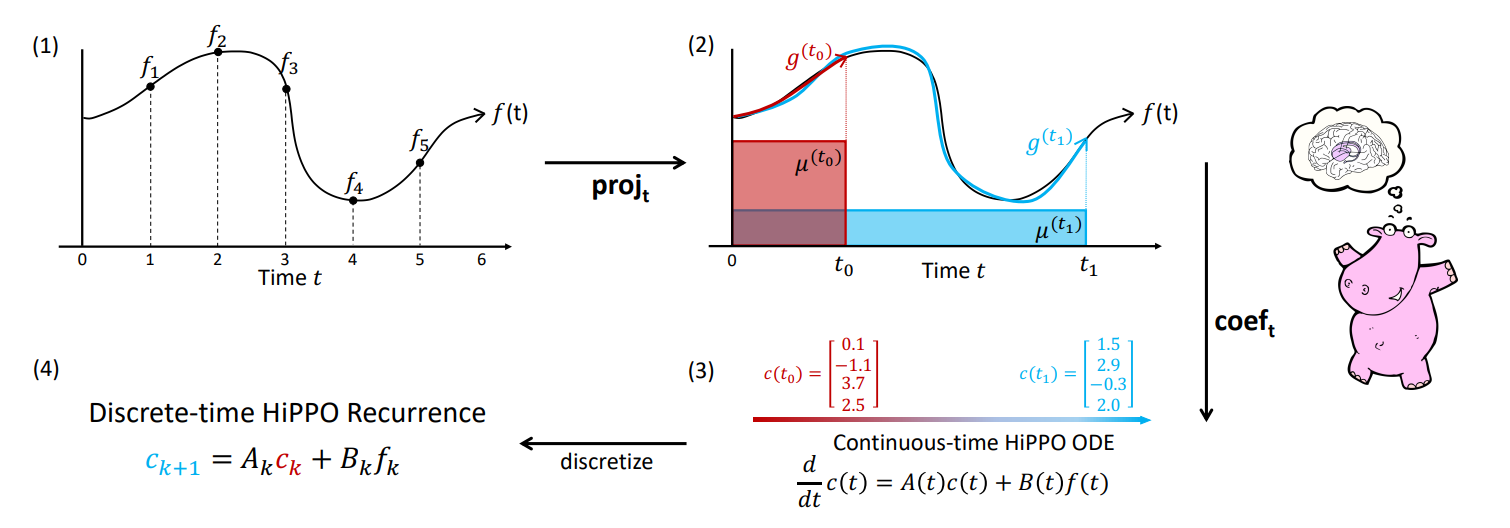
ODE 수식을 행렬식으로 전환하고, 행렬에 d차원의 계수를 d개만큼 저장하여, 특정 timestep t일 때 어느 함수에 가중치를 두어 계산할 지 결정합니다. 이를 통해 d by d 차원 행렬은 memory로서 기능합니다.
Long Range Arena benchmark (https://arxiv.org/abs/2011.04006) 로 평가한 결과 기존 방법 대비 성능이 향상되었습니다.
활용방안 및 향후 연구(개인적 의견) : 결국 time-series analysis나 long-term memory는 ODE나 S(Stochastic) DE를 통해 hypothesis를 세워야 합니다. 아무리 sparse attention, vector DB 등을 사용해도 이는 근본적인 해결책이 될 수 없습니다. 다만 본 논문에선 long-term 메모리를 Euler’s method처럼 구현하는 바람에, timestep-invariance를 구현했지만 paralellism이나 계산량에 있어서는 여전히 transformer 구조보다 어려운 점이 많습니다.
-
상세 구현
Basic notation is as follows:
t : timestep
f_t : timestep t에 따라 변하는 임의의 function
mu( <f,g> ) : probability function for given inner product <f,g>
- inner product는 선형변환을 의미합니다.
N : input data dimension
c(t) : cell state, given n*n dimension A 중 어느 row (n-dimensional function) 에 비중을 둘 지 계산하여 어느 index의 메모리에 가중치를 둘 지 결정.
여기서 다음과 같은 제안 방법이 제시됩니다.
Proj : f_t 를 Polynomial function g로 ******approximate. trained via
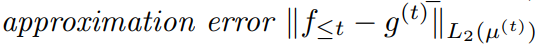
Coef : ***mu()***가 function g를 적절한 비중으로 조절하여, coefficients c(t) 로 변환.
t에 따라 ***c(t)***가 변하기 때문에, ***c(t)***를 구하기 위해서는 ODE를 풀어야 합니다.
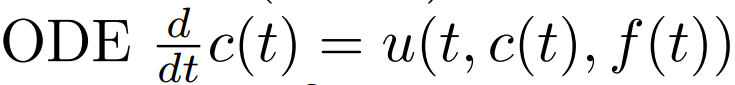
하지만 discrete time case를 가정한다면, partial derivative대신 discrete delta t를 사용할 수 있습니다. 즉 다음과 같이 변환할 수 있습니다.
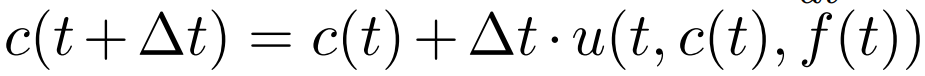
행렬을 통해 나타낸 다음 ODE 수식도,
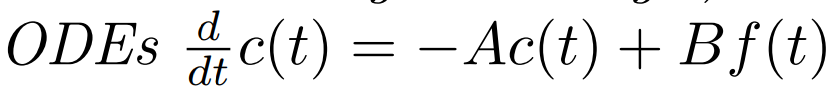
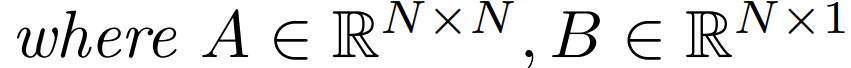
다음과 같이 변환할 수 있습니다.
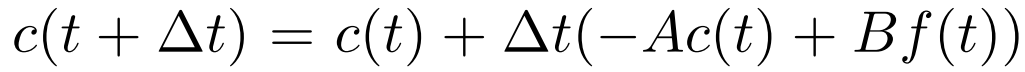
Mamba: Linear-Time Sequence Modeling with Selective State Spaces (2023)
기존 문제 : S4까지의 SSM은 모두 LTI(linear time-invariant) system이었기 때문에, 모든 토큰에 대해 동일한 state transition이 적용되었습니다. 그래서 selective copying이나 induction head처럼 content에 따라 어떤 정보를 기억하고 어떤 정보를 무시할지 결정해야 하는 task에서 transformer에 한참 못 미치는 성능을 보였습니다.
논문이 이끌어낸 직관 : state space의 B, C, Δ parameter를 input의 함수로 만들면, 각 토큰마다 서로 다른 state dynamics가 적용됩니다. 즉 LTI 가정을 깨고 input-dependent selectivity를 도입하면, attention처럼 content-aware한 정보 선별이 가능해집니다.
구체적인 방법 : B, C, Δ를 모두 input x_t의 linear projection으로 정의합니다. 다만 이렇게 만들면 더 이상 convolution kernel을 closed-form으로 쓸 수 없어서 S4의 FFT 기반 학습을 그대로 쓸 수 없습니다. 논문은 이 문제를 hardware-aware parallel scan으로 해결합니다. parallel scan을 SRAM에 올린 채로 한 번에 처리하여, FlashAttention 식의 메모리 efficiency를 SSM에서도 달성합니다.
활용방안 및 향후 연구(개인적 의견) :