Introduction
본 보고서는 실제 딥러닝 업계에 큰 영향을 준, 오래된 논문들을 선택한 것도 있습니다만, 읽고 이해하는 과정에서 혁신적인 문제해결 전략을 이해할 수 있기 때문에, 공부 목적으로도 좋다고 생각하여 정리하게 되었습니다.
Key Interpretations
Neural Tangent Kernel:
Convergence and Generalization in Neural Networks (NeurIPS 2018)
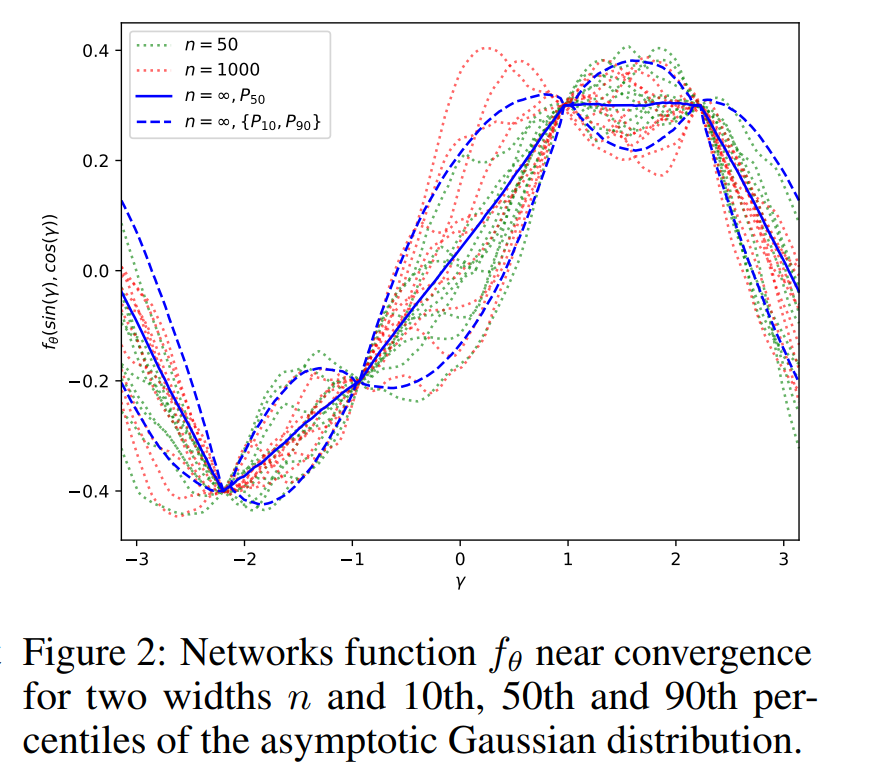
(Radford Neal, 1997) 에서 nonparametric model이 학습 시 training datapoint들에 대한 gaussian process로 증명한 바 있지만, 본 논문은 이를 확장하여 신경망에서의 학습 양상을 kernel mapping으로 해석하였고, 이는 곧 representation space의 추상화 등 매우 범용성있는 추상화 근거로 작용했습니다.
Fourier Features Let Networks Learn
High Frequency Functions in Low Dimensional Domains (NeurIPS 2020)
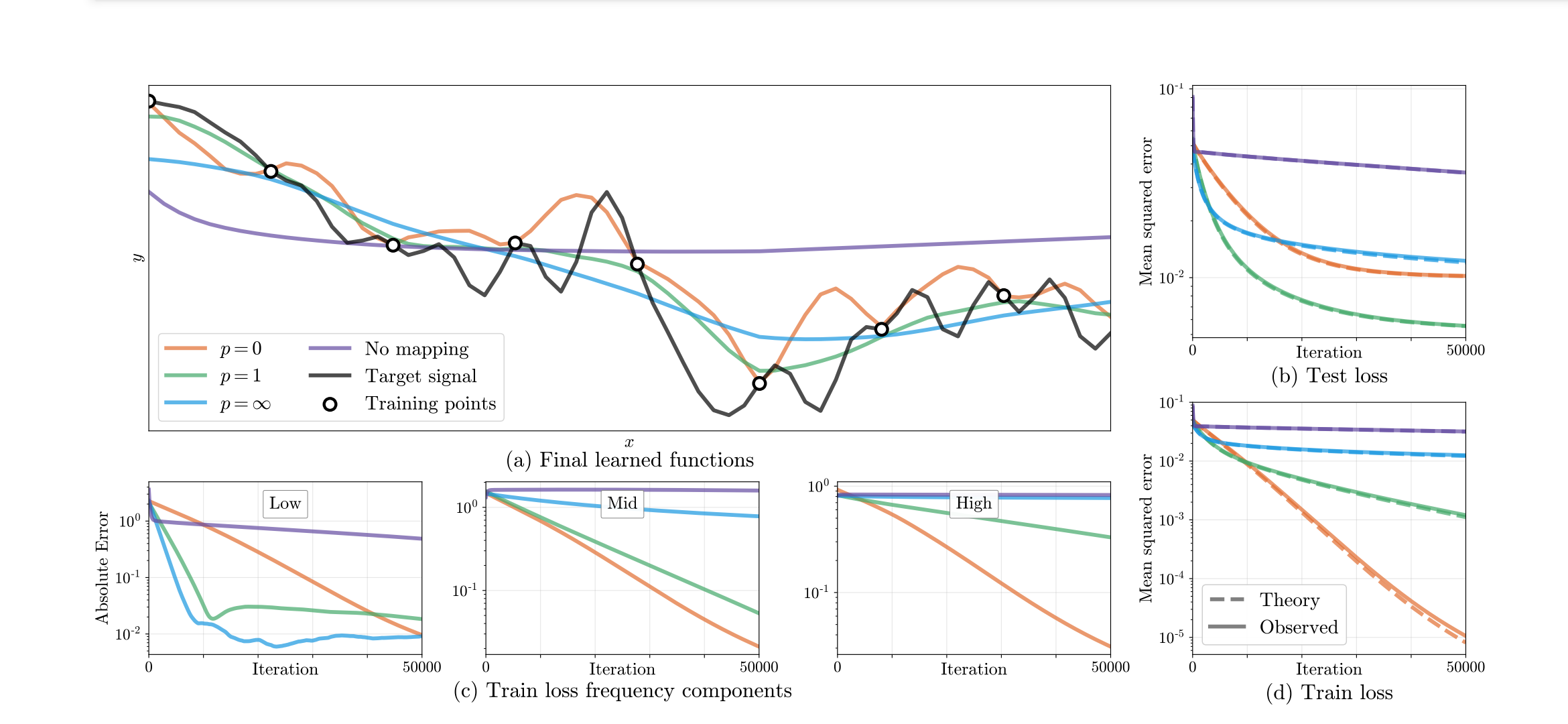
neural tangent kernel, 그러니까 입력에 대해 tangent kernel로 매핑하여 신경망의 학습 양상을 분석함으로써, high frequency를 자유자재로 다룰 수 있는 fourier feature의 특징을 시각화한 논문입니다. 그야말로 예술입니다.
Benign Overfitting in Linear Regression (PNAS 2019)*
사전지식 benign overfitting이란 노이즈를 포함한 그 어떠한 데이터에도 train loss를 0으로 만드는 현상을 의미. rank란 span of weight matrix 가 만들어내는 dimension으로, rank는 모델의 복잡도와 proportional.
논문 의의
SGD를 통해 학습된 모델의 경우, train dataset size n보다 weight matrix dimension이 크다면, weight matrix는 proper rank를 자연스럽게 가짐. 이로서 train loss를 0으로 유지하면서도, 일정 수준의 일반화 능력을 가지게 됨. 심지어 노이즈에 해당하는 데이터는 low variance feature로 매핑해버림으로서 노이즈에 대처하게 됨. dimension space는 infinite할 때 오히려 일반화하지 못하도록 학습됨. 즉, dimension space가 finite 하다는 성질(신경망을 학습하는 경우)이 일종의 규제장치가 되어 일반화 능력과 benign overfitting이 동시에 일어날 수 있도록 함.
논문에서 나온 정리 An ideal rank of squared covariance sigma, is >= than an ideal rank of covariance sigma. finite dimension space forces weight vector to contain low rank(or low variance), which ‘memorizes’ noisy data.
개인 의견 근래 신경망의 파라미터 자체가 워낙 거대하다 보니, 학습할 데이터는 신경망의 파라미터보다 작은 경우가 생긴다. 하지만 이 신경망의 파라미터 수가 무한한 상황과 유한한 상황은 천지차이이며, 유한한 상황에서는 가중치 공분산을 업데이트 하는 데 ‘제약’이 걸리게 되어 오히려 noisy data를 더 잘 처리하고 interpolation for prediction을 더 잘 수행하게 된다.
근데 이렇게 너무 엄밀하게 접근하면… 이게 어떤 데이터의 학습양상을 설명해주기는 하지만 직관적인 이해를 위해서는 ‘uniform convergence cannot explain …’ 논문이 더 좋은 선택이고, rank나 risk 등을 너무 일반적으로 정리하려다보니 수식 자체도 난해하고 유도한 내용도 뭔가 임팩트있지는 않은 느낌이 든다.
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks (NeurIPS 2023)
신경망이 어떻게 알고리즘을 학습하는지, 그리고 나머지 연산과 같은 매우 단순한 문제를 어떻게, 또 어떤 알고리즘으로 학습하는지 분석해낸 정말 놀라운 논문입니다.
2503, Anthropic, Circuit Tracing: Revealing Computational Graphs in Language Models
Groundbreaking Structures
A Neural Probabilistic Language Model
(NeurIPS 2000)
당시에도 단어에 대한 distributed embedding or representation 개념이 제안되어, 컴퓨터에서 NLP를 어느정도 수행할 수 있게 됨. 하지만 자연어 특유의 복잡성과 객관적인 기준을 찾기 어렵다는 문제 등으로 여전히 사람이 직접 feature나 ontology를 설계해야 했음. 하지만 language modeling task에 probability distribution을 예측하는 것으로 uncertainty를 정량화하고, neural weight를 update함으로써 task를 달성하도록 objective function을 설정하자 자연스럽게 distributed representation이 형성되었음. word2vec 개념의 시초인 셈.
Neural ODE (NeurIPS 2018)
Set Transformer (ICML 2019)
A Neural Corpus Indexer for Document Retrieval
(NeurIPS 2022)
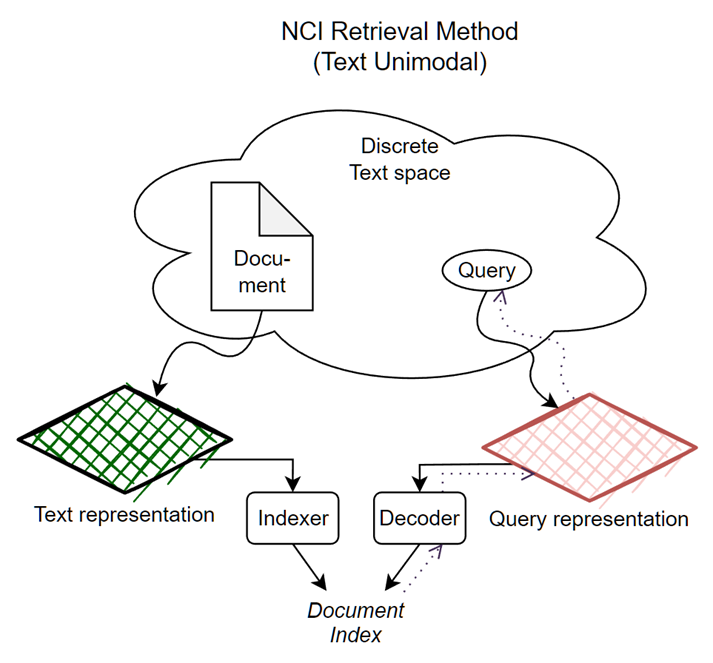
Question answering, Retrieval task는 필연적으로 거대한 DB 관리, 쿼리 해석, Ranking, Personalization 등 수많은 sub-task를 동반해야 하고, representation space를 효율적으로 사용하지 못한다는 문제가 있었으나, query input에 대한 autoregressive “document index” generation task로 전환하여 혁신적으로 검색 성능을 향상시킴.
Highlight figure
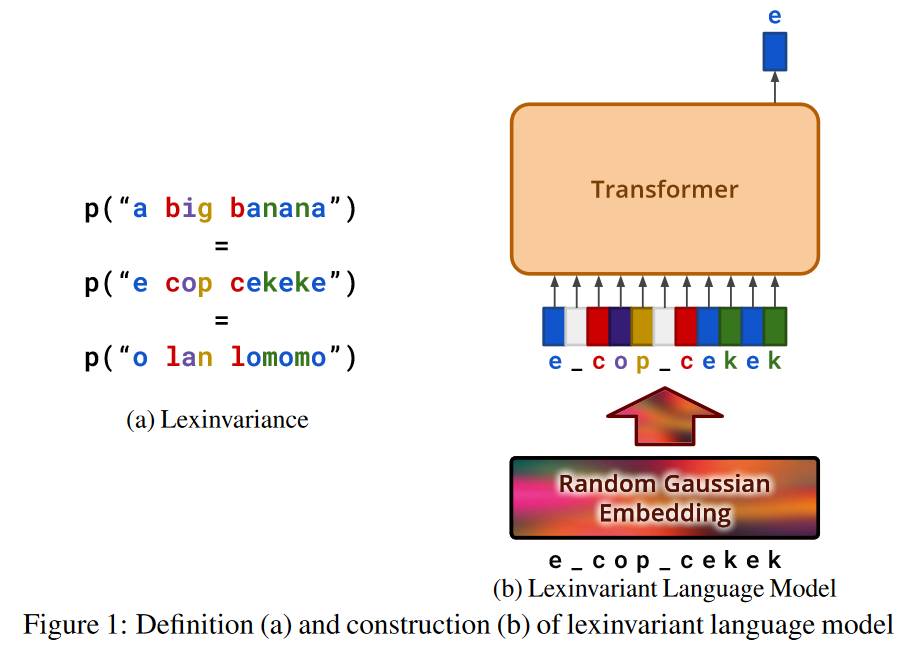
Lexinvariant Language Models
(NeurIPS 2023)
사람의 뛰어난 In-context learning 능력은 LLM에게도 중요한 것으로 사료되나, 아직까지 사람의 뇌 구조 등 In-context learning 능력이 어디서 오는지 애초에 알 수 없기 때문에, ICL 성능이 높은 LLM의 동작을 역으로 분석하려는 연구가 계속되고 있음. 특히 language modeling은 In-context learning을 nominal하게 수행하는 task가 아님에도 어떻게 LLM이 In-context learning을 잘 하는지는 미스테리에 가까움. 본 논문은 역으로 language modeling과 In-context learning을 전부 잘 해야 수행할 수 있는 Decipher task를 제안하고, 이것의 기반은 Lexinvariance에서 기원했음을 설명함.
Highlight figure
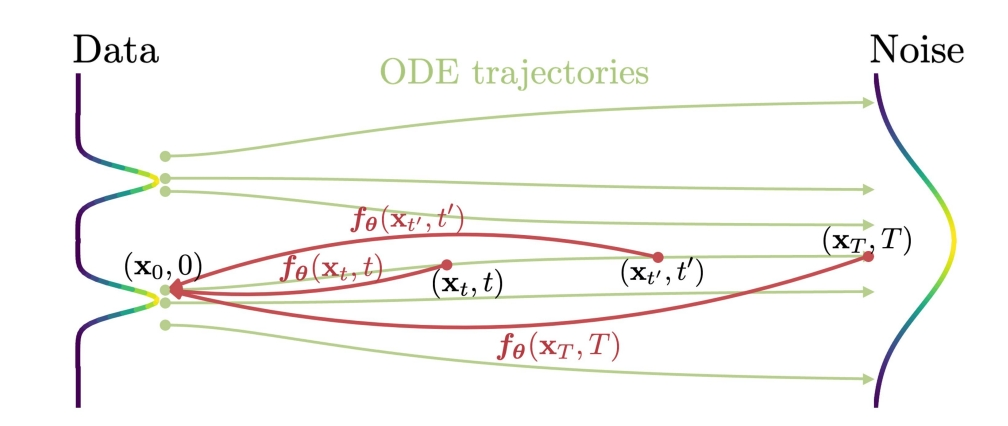
Consistency Models (ICML 2023)
Highlight figure

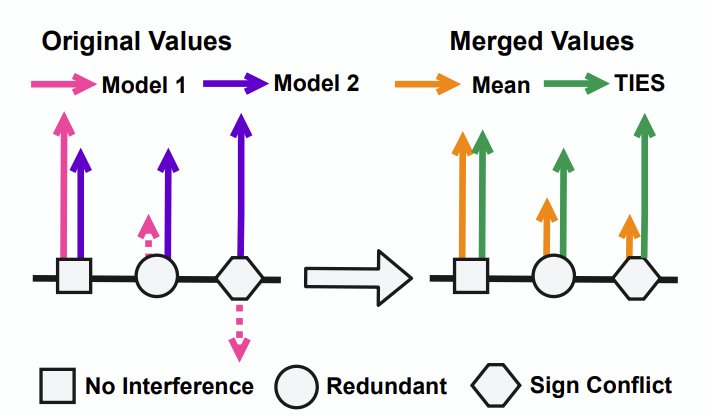
TIES-MERGING: Resolving Interference When
Merging Models (NeurIPS 2023)
Highlight figure
✨Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, 2502
“기존의 텍스트를 나열하는 추론과정 대신, 메타학습, 즉 학습하는 방법을 학습함으로서 추론 과정을 학습할 수 있습니다.“
연관 트렌드 : test-time compute, reasoning
기존 문제 : 언어는 추론 결과에 대한 표현 혹은 산출물이므로, 언어만을 통해서 학습하면 인과관계를 이해하지 못하거나 자신이 출력한 결과와 사용자의 지시문을 혼동하는 등 여러 문제가 발생합니다. o1는 이런 패러다임을 깨고 CoT를 내재화하여 자체적인 추론과정을 만들도록 했지만, 이 역시 결국 언어로 표현된다는 한계점이 있습니다.
논문이 제시한 직관 : 추론 과정을 일종의 gradient descent로 가정한다면, 랜덤하게 주어진 지점을 특정 loss function에 대한 minimum으로 옮기는 과정이라 볼 수 있습니다. 이 때 입력에 따라 변하는 것은 오로지 랜덤 지점, 즉 ‘주어진 초기화 지점’ 이므로, 추론 과정은 ‘주어진 문제를 어떻게 해결할 것인가’ 를 고민하는 것으로 해석할 수 있습니다.
구현 상세 : Recurrent block과 Sandwich format을 사용합니다.
-
Recurrent block
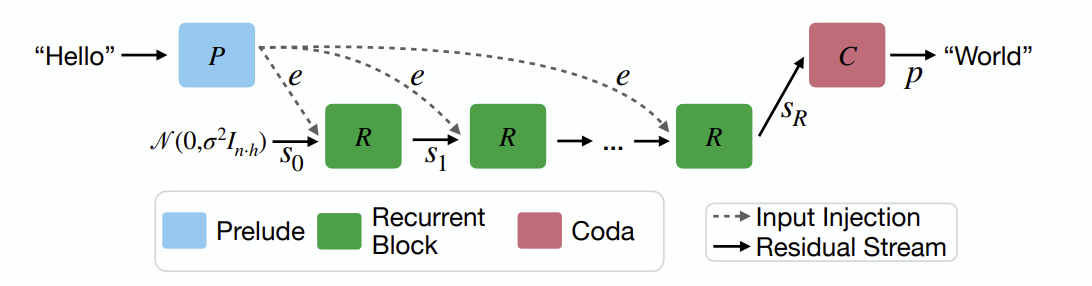
-
s_0부터 s_i까지의 reasoning step을 계산하는 블록입니다. gradient descent를 구현하기 위하여 랜덤 벡터와 decoder의 last representation을 block의 input으로 입력시키고, 점진적으로 다른 공간에 놓인 representation으로 매핑하여 LM head를 통해 다음 토큰을 예측합니다.
-
Sandwich format : layernorm을 여러번 사용한 것으로, 아래 그림과 같습니다.
분석 결과 : 이 구조는 다음과 같은 특성을 갖습니다.
- Path independence : 기존의 MCTS와 같은 RL 탐색 구조는 tree라던가 어떤 사람이 생각하는 bias에 묶여있는 형태였습니다. 그러므로 탐색하는 path의 방향이나 갈래가 항상 정해진 상태였습니다. 하지만 본 모델은 gradient descent를 시뮬레이션 한 것이므로, path independent한 특성을 지닙니다.
- meta-measure for inference : 마치 gradient descent처럼 minimum으로 수렴하는 지점이 생긴다면, early-stopping처럼 학습을 중단하고 바로 모델을 사용할 수도 있을 것입니다. 본 모델도 동일하게 작동 가능함을 확인했습니다.
- warm-start of inference : 비슷한 질문이나 특정 의도에 맞춰 대답해야 할 경우, 완전한 노이즈 상태 (s0)보다는 어느정도 추론된 상태 (sn)을 쓸 수 있습니다.
개인 의견 : simulation learning에 이어 또다른 혁신이네요. 그야말로 “AI가 AI를 학습함” 인데다 제약조건도 거의 없는 수준입니다. 뭔가 더 할말이 없네요 너무 대단해서;;
Revealing Robust Limitations
Jailbroken: How Does LLM Safety Training Fail?
(NeurIPS 2023)
Humanly certifying superhuman classifiers
(ICLR 2022)
Motivations for Rethinking
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
(NeurIPS 2017)
A Closer Look at Memorization in Deep Networks
(ICML 2017)
Uniform convergence may be unable to explain generalization in deep learning
(NeurIPS 2019)
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time (ICML 2022)
tl;dr
각기 다른 lr hyperparameter로 학습된 모델들의 가중치를 평균내면 InD OOD 성능 모두 좋아짐
motivation
hyperparameter의 존재 자체가 딥러닝이 애매한 학문 분야라는 것을 뜻합니다. 탄탄한 이론을 기반으로 했으면 하지만 학습률이나 optimizer가 theory-deriven ideal optimization method가 없어요… 하지만 딥러닝이란 하드웨어 제약이 성능에 제일 큰 영향을 끼치기 때문에 이런걸 연구하려는 사람도 없었…다고 생각했는데,
buildup
도대체 무슨 원리인지는 모르겠지만 다양한 learning rate로 fine-tune 한 모델들의 가중치를 average하면 보통 최적의 test-error minima에 도착함. 이게뭐지?
-
Auxiliary figures
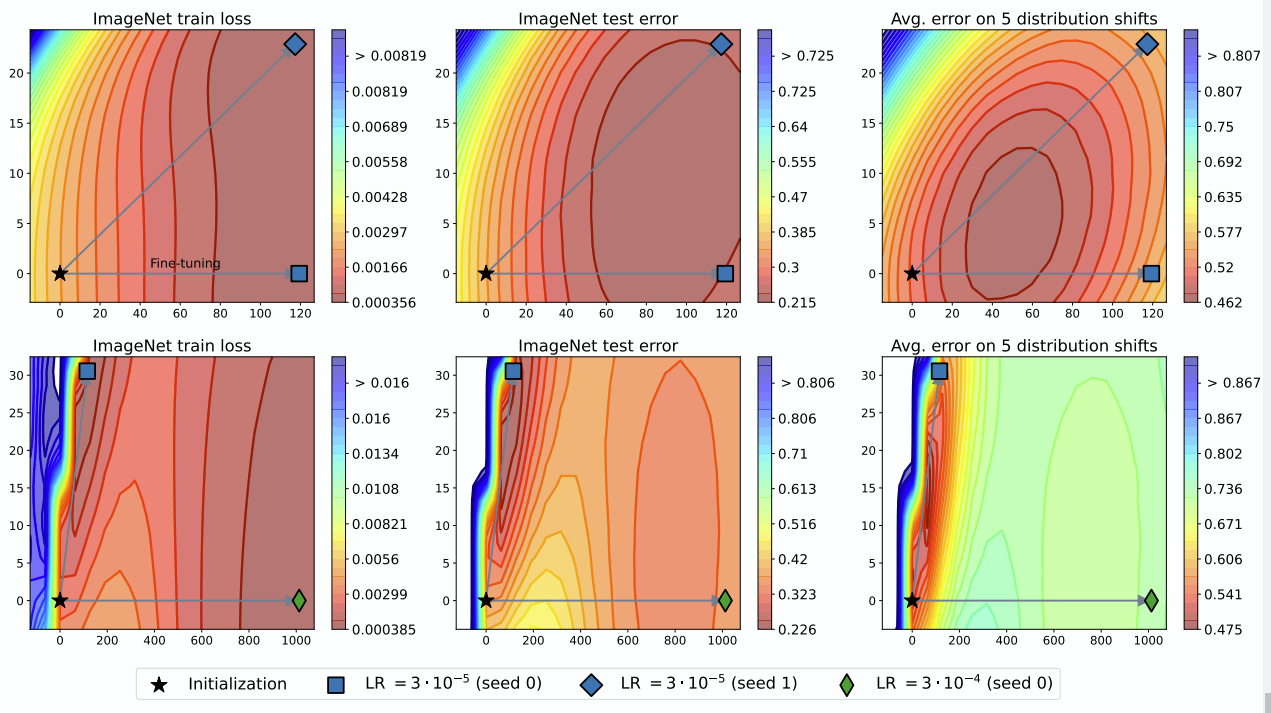
proposal
이 분석 결과를 토대로 그냥 학습된 모델 파라미터를 평균내버리는 방법을 제안함. 심지어 greedy하게 평균낼 모델 가중치를 선택하는 방법이 uniform하게 하는것보다 더 좋음.

Analyses & experiments
별다른 분석이랄것도 없고 그냥 우연히 assumption에 대해 실험이 기가막히게 걸린건지 뭔지 이해가 안가네요
opinion
황당하네요
*. PNAS의 경우 딥러닝 페이퍼 퀄리티가 보장되는 몇 안되는 저널에 해당합니다.
Provably Optimal Algorithms for Generalized Linear Contextual Bandits (ICML 2017)
tl;dr
각기 다른 lr hyperparameter로 학습된 모델들의 가중치를 평균내면 InD OOD 성능 모두 좋아짐
motivation
hyperparameter의 존재 자체가 딥러닝이 애매한 학문 분야라는 것을 뜻합니다. 탄탄한 이론을 기반으로 했으면 하지만 학습률이나 optimizer가 theory-deriven ideal optimization method가 없어요… 하지만 딥러닝이란 하드웨어 제약이 성능에 제일 큰 영향을 끼치기 때문에 이런걸 연구하려는 사람도 없었…다고 생각했는데,
buildup
K개의 bandit이 있다고 가정
X_t : t 시점에서 bandit을 골랐다는 정보. ‘bandit을 고르다’ 는 action에도 해당하므로, a_t로도 표기됨.
Y_t : t 시점에서 고른 bandit이 출력하는 reward, Y_t = μ(X_t θ*) + ε_t
θ : bandit의 return을 관장하는 파라미터. Unknown.
m() : normalizer로서, m(Xθ) = ∑x_t * θ. 즉, m(Xθ) > YXθ 인 경우
일반화된 P(Y | X)는,
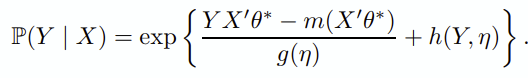
log-likelihood를 활용한 MLE를 해보면,

도대체 무슨 원리인지는 모르겠지만 다양한 learning rate로 fine-tune 한 모델들의 가중치를 average하면 보통 최적의 test-error minima에 도착함. 이게뭐지?
-
Auxiliary figures
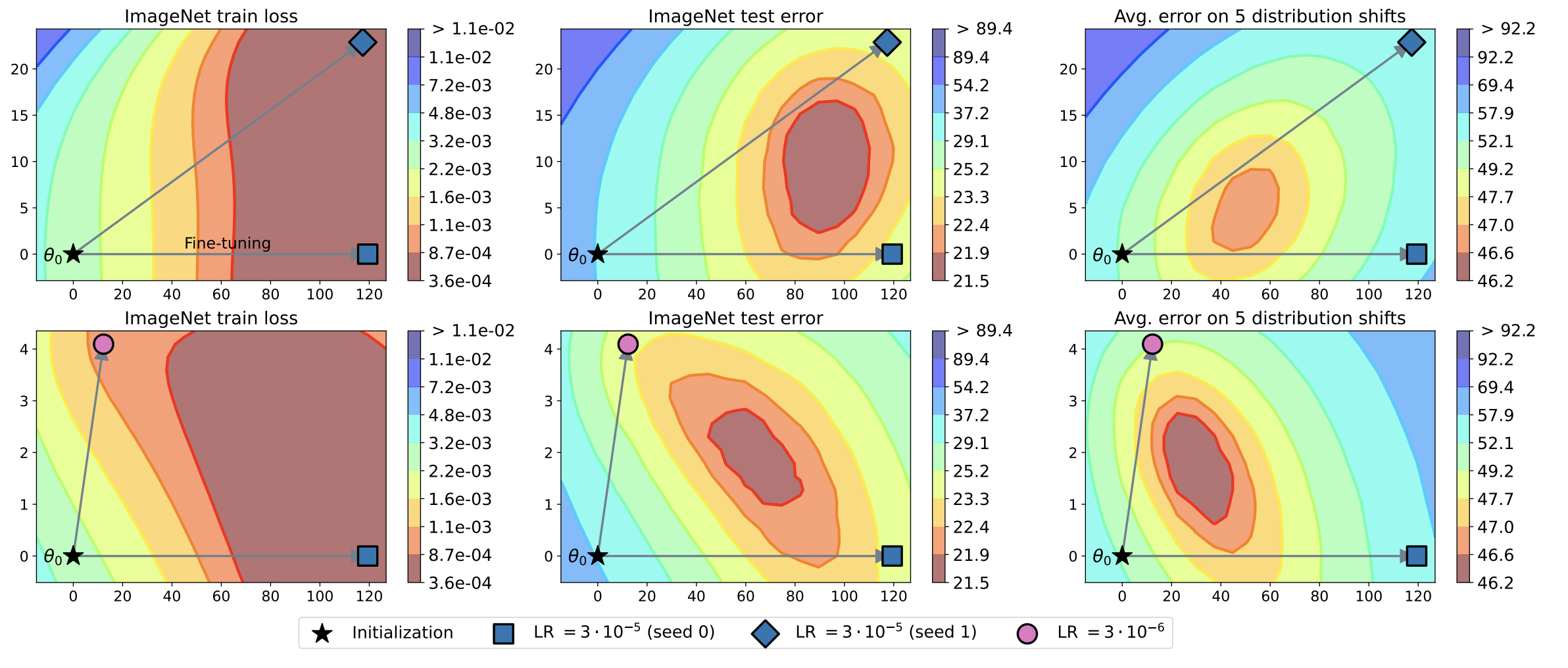
proposal
이 분석 결과를 토대로 그냥 학습된 모델 파라미터를 평균내버리는 방법을 제안함. 심지어 greedy하게 평균낼 모델 가중치를 선택하는 방법이 uniform하게 하는것보다 더 좋음.
Analyses & experiments
별다른 분석이랄것도 없고 그냥 우연히 assumption에 대해 실험이 기가막히게 걸린건지 뭔지 이해가 안가네요
opinion
황당하네요
Provably Optimal Algorithms for Generalized Linear Contextual Bandits