Similarity of Neural Network Representations Revisited
tl;dr
학습 데이터셋이 주어졌을 때 데이터간의 상관관계 및 representation magnitude 에 대해 invariant(isotropic invariance) 한 “RBF” “kernel mapped via training” vector 를 활용하는 것이 좋은 similarity metric임.
motivation
representation을 평가하는 데 있어서 다양한 측면을 고려할 수 있지만, 제일 나이브하고 고전적이면서도 지금도 무난한 metric이라고 여겨지는 것이 cosine similarity입니다. 때문에 similarity metric for representations 에 새로이 도전하는 연구는 매우 중요합니다.
buildup
representation x를 좀 더 sparse하거나 큰 dim으로 매핑하는 함수 f: x → y 를 가정, where x in R^p_1. 이 때 representation이 다음 세가지 연산에 대해 invariance해야 함을 가정.
- invertible linear transformation
- 역행렬을 가질 수 있는 행렬이라면 무조건 가능.
- orthogonal transformation
- 간섭불가한 변환이므로 충분한 rank만 주어진다면 가능.
- isotropic scaling
- feature의 magnitude가 크든 작든 상관없어야함.
이를 정리하면 direction이 곧 similarity metric에 지배적인 영향을 미쳐야 한다고 말하는듯
proposal
기존의 kernel 기반 similarity metric이었던 HSIC의 경우 K_ij = k(x_i, x_j) 를 이용함으로서, 데이터를 학습했을때의 representation을 가정하여 similarity를 만들었으나, 데이터 수에 대해 영향을 받음. 즉, 거꾸로 데이터 수나 분포에 영향을 받지 않기 위해서는 데이터들의 통계량이 known distribution으로부터 draw 되어야함. 그러므로 kernel 매핑한 값 분포가 gaussian으로 수렴할 것이라는 전제가 깔린 rbf 커널을 활용할 것을 제안.
-
Highlight figures
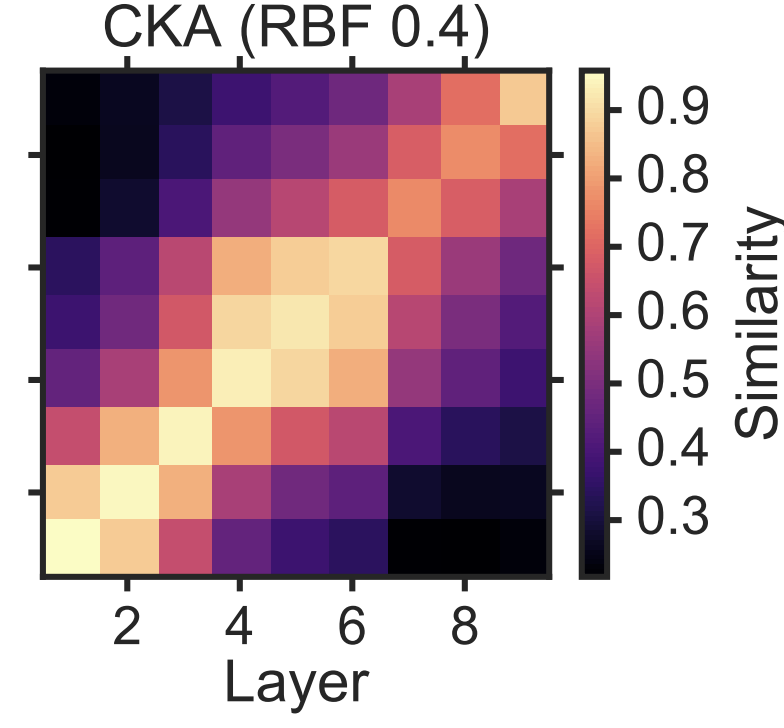
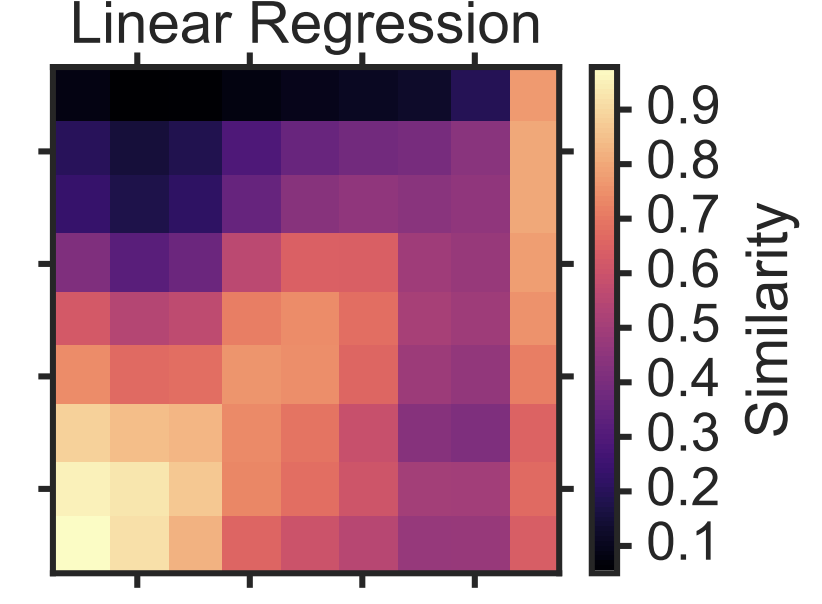
주어진 학습 데이터에 대해 학습한 이미지 분류 모델 10개를 각 similarity metric으로 layer-wise 하게 비교
Analyses & experiments
주어진 데이터셋에 대해 학습한 모델들을 여러 metric으로 비교하고, metric의 평균점수를 레이어별로 비교. 데이터에 대해 점점 추상적인 정보를 학습할테니 레이어별 feature-mapping function(or kernel)의 weight는 비슷할 것이란 가정을 두면, 동일한 레벨의 레이어들은 ‘similar’ 할 것. rbf 커널을 활용한 centralized analyses 는 해당 가정에 제일 align하는 결과를 가짐.
opinion
이 경우도 상당히 general하고 low-level에서 분석하려는 연구지만, 모델 파라미터가 큰 경우 low-level 접근 및 추론 양상이 달라진다는 연구가 있기도 하고… 요즘은 너무 high 레벨이면서(특히 언어모델은 datapoint dimension에서 접근하는 연구들이 너무너무많아요…) 실제 성능도 개선시킨 방법론들이 쏟아져나와서, 간만에 읽는 재미는 있었지만 어디에 쓸 수 있을지는 애매한 연구인듯 합니다.
Model soup
tl;dr
각기 다른 lr hyperparameter로 학습된 모델들의 가중치를 평균내면 InD OOD 성능 모두 좋아짐
motivation
hyperparameter의 존재 자체가 딥러닝이 애매한 학문 분야라는 것을 뜻합니다. 탄탄한 이론을 기반으로 했으면 하지만 학습률이나 optimizer가 theory-deriven ideal optimization method가 없어요… 하지만 딥러닝이란 하드웨어 제약이 성능에 제일 큰 영향을 끼치기 때문에 이런걸 연구하려는 사람도 없었…다고 생각했는데,
buildup
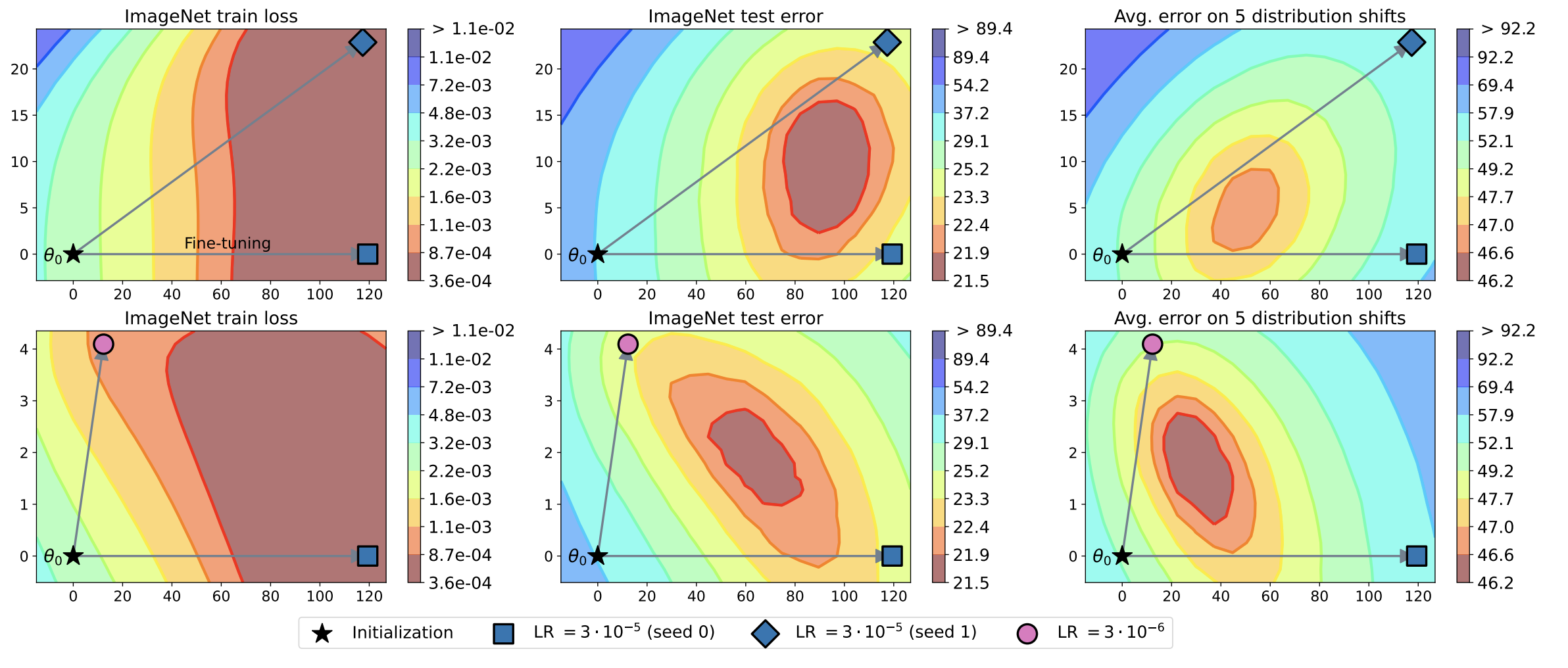
도대체 무슨 원리인지는 모르겠지만 다양한 learning rate로 fine-tune 한 모델들의 가중치를 average하면 보통 최적의 test-error minima에 도착함. 이게뭐지?
-
Auxiliary figures
proposal
이 분석 결과를 토대로 그냥 학습된 모델 파라미터를 평균내버리는 방법을 제안함. 심지어 greedy하게 평균낼 모델 가중치를 선택하는 방법이 uniform하게 하는것보다 더 좋음.

Analyses & experiments
별다른 분석이랄것도 없고 그냥 우연히 assumption에 대해 실험이 기가막히게 걸린건지 뭔지 이해가 안가네요
opinion
황당하네요
Are Words the Quanta of Human Language? Extending the Domain of Quantum Cognition
- Abstract : In previous research, we showed that ‘texts that tell a story’ exhibit a statistical structure that is not Maxwell–Boltzmann but Bose–Einstein. Our explanation is that this is due to the presence of ‘indistinguishability’ in human language as a result of the same words in different parts of the story being indistinguishable from one another, in much the same way that ’indistinguishability’ occurs in quantum mechanics, also there leading to the presence of Bose–Einstein rather than Maxwell–Boltzmann as a statistical structure. In the current article, we set out to provide an explanation for this Bose–Einstein statistics in human language. We show that it is the presence of ‘meaning’ in ‘texts that tell a story’ that gives rise to the lack of independence characteristic of Bose–Einstein, and provides conclusive evidence that ‘words can be considered the quanta of human language’, structurally similar to how ‘photons are the quanta of electromagnetic radiation’. Using several studies on entanglement from our Brussels research group, we also show, by introducing the von Neumann entropy for human language, that it is also the presence of ‘meaning’ in texts that makes the entropy of a total text smaller relative to the entropy of the words composing it. We explain how the new insights in this article fit in with the research domain called ‘quantum cognition’, where quantum probability models and quantum vector spaces are used in human cognition, and are also relevant to the use of quantum structures in information retrieval and natural language processing, and how they introduce ‘quantization’ and ‘Bose–Einstein statistics’ as relevant quantum effects there. Inspired by the conceptuality interpretation of quantum mechanics, and relying on the new insights, we put forward hypotheses about the nature of physical reality. In doing so, we note how this new type of decrease in entropy, and its explanation, may be important for the development of quantum thermodynamics. We likewise note how it can also give rise to an original explanatory picture of the nature of physical reality on the surface of planet Earth, in which human culture emerges as a reinforcing continuation of life.