New(240805) : 각 페이퍼 설명에는 필요 시 트렌드 배경을 먼저 소개하고, 논문의 문제정의 evidence를 빌드업 으로 표기합니다.
Evolution of Heuristics: Towards Efficient Automatic Algorithm Design Using Large Language Model
기존 문제 : 딥러닝은 하루가 멀다하고 엄청나게 빠르게 발전이 이루어지고 있지만, 실제로 딥러닝을 적용할 수 있는 분야는 한정되어 있고, 특히 딥러닝 모델이 수학적 추론능력이 매우 부족하다는 것이 부각된 이후로는 딥러닝에 대한 기대? 가 상당히 줄어들었습니다. 하이퍼파라미터 서치 등 대부분의 작업은 여전히 사람이 노가다하는 방법(greedy, heuristic) 으로 이루어지고 있습니다.
-
Highlight Figure
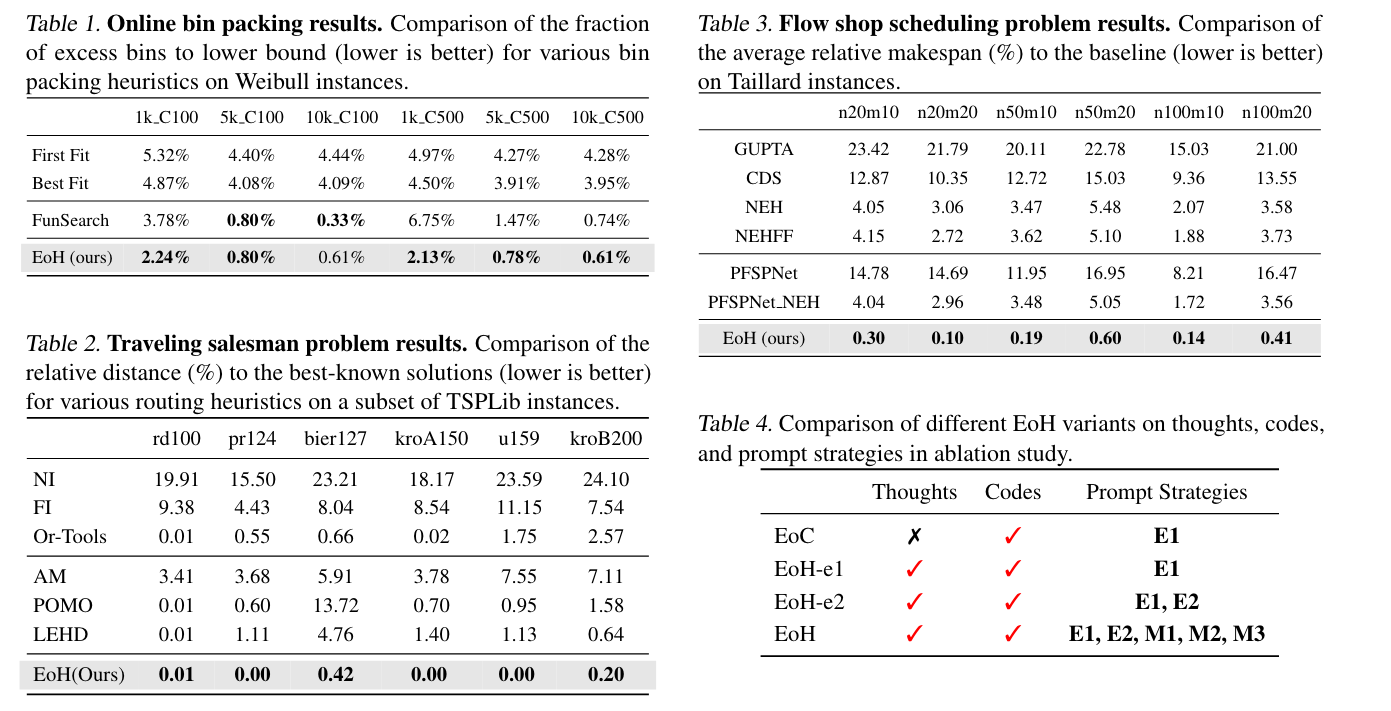
논문이 이끌어낸 직관 : LLM은 다양한 시도와 이를 코드로 표현할 수 있습니다. 따라서, 진화 알고리즘을 활용하여 여러 그럴듯한 발상을 만들어내게 하면, heuristic search를 대신해줄 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : LLM agents 라는 개념에서 충분히 떠올릴 수 있는 식상한? 발상이지만, 진화 알고리즘을 사용하여 발상을 만들어내는 과정이나, heuristic이란 단어로 다양한 알고리즘을 일반화하여 그 어떤 학문분야에도 적용할 수 있다는 점이 강점이라고 생각합니다. 특히 NP 문제인 TSP 문제를 효율적으로 풀어내는 알고리즘을 20 iteration 안에 제안했다는 점은 조금 무섭게 다가왔습니다.
상세 방법 : Evolution을 담당하는 2 agents, Modification & Evaluation 을 담당하는 3 agents, 총 5개의 LLM agents를 구성하여, 진화 알고리즘을 종합적으로 컨트롤합니다.
Does Label Smoothing Help Deep Partial Label Learning?
트렌드 배경 : 정교한 레이블링은 필연적으로 높은 비용을 발생시키므로, 이를 회피하기 위해 직접적으로 정답 레이블을 하나 고르는 대신 정답 레이블이 담겨있는 set을 고를 수 있습니다. 이 분야를 PLL(Partial Label Learning), 혹은 conformal prediction 이라고 하는데, 주로 레이블 noise를 가정하고 prediction uncertainty를 반영한다던가, model calibration을 set 단위로 수행하여 데이터의 특성을 좀 더 쉽게 분석하는 등 여러 재밌는 application으로 발전할 수 있는 분야입니다.
또한, label smoothing이란 one-hot encoding 형태의 레이블을 수정하여 오답에도 작은 소수 단위 값을 할당하는 일종의 confidence regularizer라고 할 수 있습니다. 실제 fine-tuning 단계에서 성능을 직접적으로 향상시키는 효과가 있고, 그 외에도 model calibration부터 시작해 다양한 dynamics를 지닙니다.
기존 문제 : 하지만 이론과는 달리 현실 데이터로 추론된 set은 uniform over support가 아니라 어떤 relationship을 가지는 element끼리 뭉치는 현상을 가져, Ideal scenario인 uniform noise를 가정하는 것이 아닌, 의도치 않은 relationship에 overfit되는 문제를 초래합니다. 또한 label smoothing의 경우에도 smoothing의 factor가 어느정도여야 하는지 아직 확실한 증거는 밝혀지지 않았으므로, empirical하게 찾아야 하는 하이퍼파라미터로 남겨져 있습니다.
-
Highlight Figure


논문이 이끌어낸 직관 : PLL은 uniform label noise 가정이 실세계의 데이터로 연결되지 않는다는 허점을, 반대로 label smoothing은 uniform label noise를 강제로 걸어야 한다는 약점을 서로 합쳐 상호보완된 느낌입니다. 본문에서는 PLL의 risk bound 개념을 도입하여, induce된 expected-empirical risk bound gap을 좁히는 데 필요한 parameter for assuming uniform uncertainty 를 거꾸로 ideal smoothing factor로써 사용했습니다. 그 결과 PLL에 필요한 ideal smoothing factor는 데이터의 특성과 주어진 amounts of class, class subset만으로 곧바로 도출해낼 수 있게 되었습니다.
활용방안 및 향후 연구(개인적 의견) : Kaggle같이 소수점 둘째자리 약간 올리려고 경쟁하는 대회에서는 label smoothing factor 찾는 데 쓰던 시간을 ensemble 만드는 데 더 투자할 수 있게 되었습니다.
…
사실 BERT-style LLM (Encoder only)은 model calibration이 애초에 잘 되어있다고 알려져 있기 때문에, downstream task에 적용할법 하지만 LLM이 뭐든 해주는 현상황에서는 딱히… 적용할 쓰임새가 있을지 모르겠네요. 이론적인 전개 과정은 좋았습니다.
Learning Useful Representations of Recurrent Neural Network Weight Matrices
트렌드 배경 : RNN의 장점은 단일 가중치로 time series data를 처리할 수 있다는 점이지만, 가중치를 학습하거나 추론하는 과정에 심각한 비효율성이 있기 때문에 transformer로 거의 대체되었습니다. 물론 transformer도 context 길이에 대해 exponential 하게 computation이 증가하는 문제가 있어 대안이 계속해서 제기되는 상황입니다. 이를테면 state space models(SSM) 계열 모델이 있는데, 이는 differential equation이 discreteness를 continuous하게 이어주는 역할을 할 수 있다는 assumption을 기반으로 합니다. 하지만 최근 연구에서 SSM 계열 모델의 성능이 transformer보다 낮다고 지적한 바 있습니다. 그래서 이를 아예 우회하기 위해 RNN의 representation을 mimic한다는 아이디어가 trend로 발전하게 됩니다.
기존 문제 : n개의 task i에 대해 데이터 로 학습된 RNN 의 representation z 를 가정할 때, RNN model set D는 로 표현할 수 있습니다. 이 때 로 supervised learning을 수행하는 식으로 learning representations of weight matrices 를 수행할 수 있습니다. 하지만 weight를 직접적으로 학습할 경우 모델 성능이 task의 difficulty에 크게 의존하는 문제가 있습니다. 또한 weight representation learning의 경우 permutation invariance, generalizability 등 까다로운 조건을 만족해야 하므로, 획기적인 방법은 실세계와 동떨어진 어떤 Ideal condition from theoretical induction 에 approximation 하는 형태로만 남아있었습니다.
-
Highlight Figure
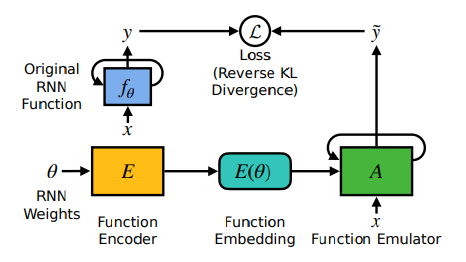
논문이 이끌어낸 직관 : RNN model set에 loss function이 직접적으로 접근하는 대신, function emulator A가 만들어낸 결과를 토대로 function embedding을 학습하여, timestep t에서의 RNN 의 동작 을 토대로 RNN weight of 를 예측하는 모델 를 학습합니다. 이를 통해 동작 패턴이 어떤 RNN에 의해 만들어지는지, 해당 RNN은 어떤 task로 학습되었는지 추론할 수 있고, RNN simulator 로써도 훌륭한 기능을 하는 모델을 학습할 수 있습니다.
-
상세 방법
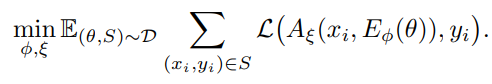
활용방안 및 향후 연구(개인적 의견) : 이 논문은 정말 어마어마한 가능성을 열어준 것과 같습니다. 본 논문의 모델은 task representation으로 연결될 수 있는데, 단순히 classification이 아니라 encoding으로 representation을 만들어낼 수 있기 때문에 파라미터 사이즈 대비 훨씬 많은 RNN function을 재현할 수 있습니다. 그럴 경우 SSM 계열 모델에 매우 큰 기여를 할 수 있게 됩니다.
그뿐만 아니라 time-series, meta learning 등 시도해볼만한 접근이나 활용가능한 분야가 너무 많아서 나열하기 어려울 정도입니다. consistency models처럼 수식을 DE로 유도한다면 그때야말로 특이점에 가까워질 수 있다고 생각합니다.
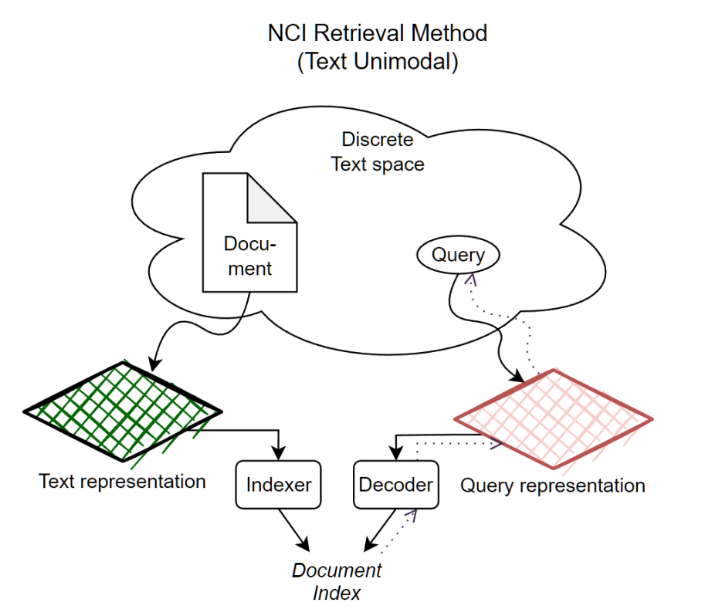
Bottleneck-Minimal Indexing for Generative Document Retrieval
트렌드 배경 : 생성형 검색 시스템은 검색 시스템의 체계를 완전히 뒤바꿀 정도의 혁신적인 구조를 갖고 있습니다. 기존 구조는 문서에서 중요한 단어를 추출해서 질의문과 매칭시키는 등 문서 정보나 질의문 정보 어느 한쪽을 반드시 변조시켜야 했었던 반면, 생성형 검색 시스템은 둘을 아예 다른 representation space상에 매핑하여, 문서 임베딩을 클러스터링 한 뒤 질의문에 대해 문서 클러스터 id를 출력하는 방식으로 작동합니다. 이 방법은 기존 검색 시스템의 성능을 2배 (정확도 30%에서 진짜로 60%로 오른 정도)가량 향상시킨 것으로 사료됩니다.
-
세미나 당시 사용한 그림자료
기존 문제 : 생성형 검색 시스템 GDR은 문서의 임베딩을 어떻게 만들어야 시스템의 성능이 향상되는지에 대한 연구가 아직 많이 없습니다. 나이브하게 문서 자체를 sentence, document representation 으로 만들어도 되겠지만, 이것이 GDR의 쿼리가 인덱싱하는 데 있어 최적이라는 evidence는 아직 이론적으로나 analytic하게나 없는 상태입니다.
빌드업 : document X에 대한 index T를 document representation 기반으로 하든 랜덤으로 생성하도록 하든 검색 성능이 크게 저하되지는 않습니다. 즉, 검색 문제에 있어서 document에 대한 representation은 반드시 document에 의존해서 학습하지 않아도 됩니다. 이를테면 STS나 NLI와 같은 task로 학습된 sentence representation 기반으로 clustering 하지 않아도 된다는 것입니다.
-
Highlight Figure
질의문 Q, 문서 X에 대한 인덱스 T가 있을 때, loss function은 다음과 같습니다.
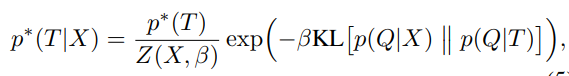
논문이 이끌어낸 직관 : document X에 대한 index T는 결국 정보를 압축, 손실시키는 과정이라는 점에서, Q로 X를 직접 계산하여 검색하는 방법 P(Q|X), Q로 T를 계산하여 검색하는 방법 P(Q|T) 을 최대한 가까워지도록 학습하면( KL(P(Q|X) || P(Q|T)) ), 검색에 있어 X를 T로 변환하는 최적의 방법을 학습할 수 있게 됩니다.
상세 방법 : x를 검색하기 위한 쿼리 데이터 Q_x가 있을 때, Q_x를 BERT에 입력하여 평균값을 취하고, 이를 인덱스 T로 놓습니다. 그러면 T는 X에 대해 어느정도의 정보도 보존하면서 인덱스라는 구조도 유지할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 처음에 빌드업까지는 참 좋았는데 실제 구현 방법에서 다양한 아쉬움이 남습니다. 물론 실용성 면에서는, document representation을 학습해야 한다는 과정을 빼버리니 한걸음 나아간 느낌이 듭니다만, 만약 그렇다면 BERT(Q_x) 를 그대로 T로 사용하기 전에 아예 PCA로 한번 더 압축해보면 어떻게 될지 궁금한데 이 부분에 대해서는 제대로된 실험이 없었던것 같습니다.
How do Large Language Models Navigate Conflicts between Honesty and Helpfulness?
트렌드 배경 : LLM이 toxic output을 denial하도록 훈련되는 한편 이를 억제하기 위해 gradient ascent로 unlearning을 수행하게 되면, 의도치 않은 추론 능력이 상실되는 것으로 알려져 있습니다(출처달기)
기존 문제 : helpfulness와 harmlessness는 명백한 tradeoff가 있음이 알려져있습니다. 따라서 abstract metric을 최대한 Low-level(확률모델, 가중치 등) 에서 접근해야 하는데, 이에 대해 직접적으로 output result와 연결되는 metric을 만드는 것은 현재로서는 불가능에 가깝습니다.
빌드업 : 본 논문에서는 w가 실세계, u가 발화라고 한다면, P(u|w)는 실세계의 사람을 확률모델로 해석하였습니다. 또한 honesty를 where du: v^T → {0,1} 라는 함수로 거짓인지 진실인지를 판별하고, helpfulness를 reward via reinforcement learning, a \in A ( policy(a | u, A) * R(a, w) ) 으로 측정하였습니다. 수식으로 표현하자니 다소 난해해 보이지만, 실상은 사람이 직접 action(given utterance)에 대한 helpfulness를 레이블링했다고 가정할 수 있습니다. 사람(레이블러 혹은 reward model) 은 저마다 처한 환경, 즉 실세계 w가 다르기 때문에 helpfulness와 honesty를 제각기 다르게 판단하거나, 아니면 helpfulness를 위해 honesty를 저버리는 등 유도리 있는 판단을 수행할 수도 있습니다.
-
Highlight Figure
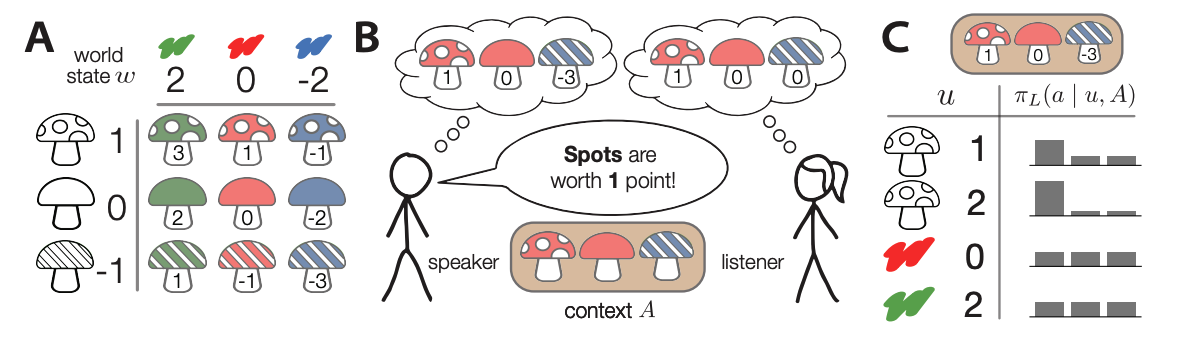
논문이 이끌어낸 직관 : LLM은 CoT를 통해 거짓말이 때로는 helpful한 답변이 될 수 있음을 이해하며 실제로 행동합니다.
상세 방법 : 서로 다른 환경에 놓인 출제자와 도전자를 가정할 때, LLM에게 도전자에게 제일 도움이 되는 u~U 하나를 제시하도록 했습니다. 그 결과 RLHF로 학습된 모델은 진실이면서도 helpful인 u를 제시하도록 학습되는 반면, CoT는 모델이 혼자 진실/거짓 여부와 상관없이 helpful인 u를 제시하도록 스스로 유도했습니다.
활용방안 및 향후 연구(개인적 의견) : AGI라는 용어가 나올 만큼 LLM이 크게 발전해오고 있는데, 이제는 LLM을 거의 사람 레벨로 간주하며 사람들도 서로 어려워하는 난제에 대해 어떻게 반응하는지가 현 연구 트렌드인것 같습니다. AI의 발전 속도가 새삼 엄청나게 빠르다는 것이 체감됩니다.
-
https://arxiv.org/abs/2403.03103
요약 : deep model들을 섞은 앙상블은 모델들의 순서나 결합 방법에 영향을 받지 않는, 결국에는 train data로 가능한 augmentation을 전부 만들어 냈을 때, 이에 generalize 할 수 있는 이상적인 모델 f 로 수렴하며, 이를 equivariance라 한다. 이는 어떠한 입력에도 동일하게 적용된다.
상세설명 : 기존 연구에서는 딥앙상블의 출력은 ~N(mu, var) 에 수렴하는 것으로 알려졌는데(2019년 연구) 본 논문에서는 딥앙상블이 Monte carlo approximation이라고 해석했다.
여기서는 specific timestep t 로 주어진 가중치 w를 학습하는 모델 bar-f_t(x) (where w~p for weight-initialize) 를 상정했을 때, data augmentation을 사용하면 ensemble group g를 permutation-invariant group으로 놓을 수 있고, 이런 특성으로 shift-invariance, aka equivariance로 유도할 수 있다.
개인의견 : 이런 연구는 앙상블을 억지로 하려는 뻘짓을 막아줄것 같긴 하지만, 결국 full augmentation이라고 하는, NLP에서는 적용하기 너무 어려운 제약을 가진다. 그래서 실용적으로 쓰이지는 않지 않을까?
- 별첨 신경망의 작동 양상은 neural tangent kernel로 anaylze할 수 있는듯
-
How Private are DP-SGD Implementations?
문제 배경
모델 학습에는 큰 비용이 발생하기 때문에, 어떻게 해서든 모델을 배포하는 와중에도 가중치를 유출시키지 않으려는 노력이 계속되고 있습니다. 하지만 추론 결과에 대한 loss gradient를 확인할 수 있다면 가중치값을 어느정도 유추하거나, 직접적으로 소형 모델 증류에 사용될 수 있습니다. 때문에 gradient에 noise를 섞는 Differentially Private SGD 방법이 지속 사용되고 있었습니다.
Why DP-SGD?
DP-SGD는 gradient에 랜덤 노이즈를 삽입하기 때문에, 데이터로부터 어떻게 배치를 샘플링하는지 등을 알아내야 원래 모델의 gradient를 얻을 수 있습니다. 하지만 수없이 많은 데이터에서 어떤 데이터가 랜덤 배치로 사용되었는지 직접 알아내기는 매우 어렵습니다.
Metric (ABLQ)
데이터셋으로부터 랜덤하게 구성된 T개의 배치에 대해 gradient를 계산할 때, T가 얼마나 커야 원본 배치를 재현할 수 있는지 계산합니다. T가 크면 클수록 원본 배치를 재현하기 어려우므로 ‘privacy analysis’라고 부릅니다.
Metric proposal
학습 데이터셋 X와 매우 비슷한 X’를 가정합니다 (데이터 row 하나만 다르거나 동일) 그리고 특정 매커니즘 M으로 X’를 알아낼 수 있을 확률을 통해 privacy 정도를 계산합니다.

여기서는 SGD의 privacy를
deep model들을 섞은 앙상블은 모델들의 순서나 결합 방법에 영향을 받지 않는, 결국에는 train data로 가능한 augmentation을 전부 만들어 냈을 때, 이에 generalize 할 수 있는 이상적인 모델 f 로 수렴하며, 이를 equivariance라 한다. 이는 어떠한 입력에도 동일하게 적용된다.
상세설명 : 기존 연구에서는 딥앙상블의 출력은 ~N(mu, var) 에 수렴하는 것으로 알려졌는데(2019년 연구) 본 논문에서는 딥앙상블이 Monte carlo approximation이라고 해석했다.
여기서는 specific timestep t 로 주어진 가중치 w를 학습하는 모델 bar-f_t(x) (where w~p for weight-initialize) 를 상정했을 때, data augmentation을 사용하면 ensemble group g를 permutation-invariant group으로 놓을 수 있고, 이런 특성으로 shift-invariance, aka equivariance로 유도할 수 있다.
개인의견 : 이런 연구는 앙상블을 억지로 하려는 뻘짓을 막아줄것 같긴 하지만, 결국 full augmentation이라고 하는, NLP에서는 적용하기 너무 어려운 제약을 가진다. 그래서 실용적으로 쓰이지는 않지 않을까?
- 별첨 신경망의 작동 양상은 neural tangent kernel로 anaylze할 수 있는듯
-
The Platonic Representation Hypothesis
배경: representation learning은 참 좋지만 같은 방법과 같은 데이터를 적용해도 시드값이나 데이터 순서가 다르면 서로 다른 형태를 학습하게 된다는 문제가 있습니다. 결과적으로 우후죽순 open pretrained model이 쏟아지더라도, 그의 결과물을 공유하지 representation을 공유할수는 없다는 문제가 있습니다.
The Platonic Representation Hypothesis: 어떤 하나의 개념을 다루는 데이터의 경우, 그 어떤 형태로 표현되더라도 결국 하나의 통계적 모델로 표현되는 것으로 수렴한다.
실험 내용: 본 논문은 아주 단순하지만 fundamental한 접근을 제시하는데,

이와 같이 representation, kernel(metric), kernel alignment metric을 제시합니다. 그러니까, representation이 수렴하는것이 아니라, representation간의 상관관계가 수렴한다는 것을 주장하려고 한 것 같습니다. 이걸 입증하기 위해서는 representation의 similarity를 측정하는 도구가 서로 비슷한지 확인하는게 중요하다고 주장합니다. 비록 representation이 일치하지는 않더라도 transport하거나 adapter를 학습시키는데에는 편리하겠죠?
이를 위해 model stitching이라는 방법을 소개하는데, 모델 f와 g가 layer n, m으로 구성돼있을 때, 이를 합친 모델 F를 과 같이 구성하고, 이 모델의 성능을 측정하는 것입니다. 실험 결과는 아래와 같습니다.
- 모델 크기와 성능이 높을수록 alignment는 증가합니다.
- CLIP처럼 직접적으로 caption과 image를 일치시키는 경우, pretrain 과정에서는 alignment가 증가하지만 fine-tune 한 뒤에는 오히려 감소합니다. 아마도 fine-tune을 하면 representation을 욱여넣느라 오히려 fine-tuned 모델간의 alignment가 감소하나보네요.
제안 해석: 본 논문에서 제시하는 해석은 다음과 같습니다.
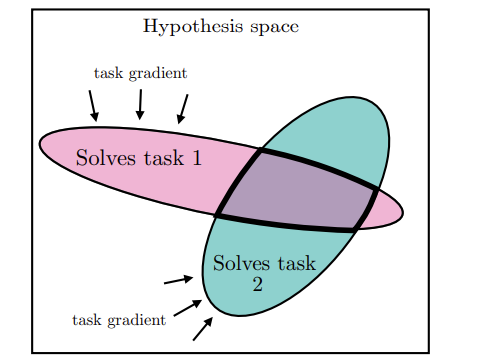
task generality: 여러 task에 대해 loss를 감소시킬 수 있는 ‘모델’ 은 한정되어 있다.
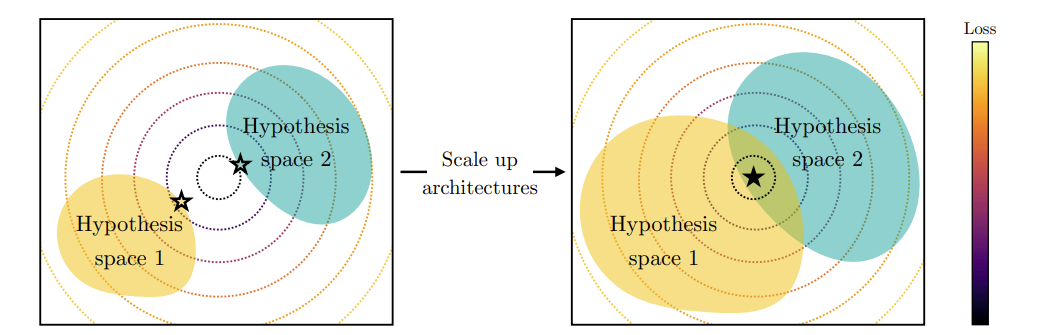
model capacity: 모델이 커지면 커질수록 특정 최적점을 공유할 가능성이 커진다.
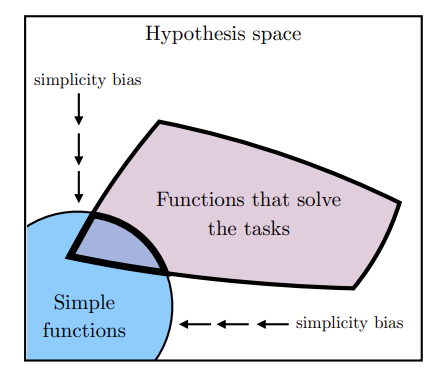
simplicity bias: 모델이 학습을 통해 task를 푸는 방법과 간단한 함수 그룹간의 교집합을 찾는다면, 간단한 함수 그룹을 공유하는 모델들은 alignment가 높아진다.
개인 의견: 이 논문은 그야말로 representation learning의 신지평을 연 것과 같네요. 왜 이런 논문을 이제서야 읽게 되었을까요? 개인적으로 diffusion model의 geometric harmony를 주장한 논문을 봤을 때도 느꼈지만, 점점 멀티모달 모델이나 연합학습 모델이 현실화되어가지 않나 싶습니다. 특히, MoE 구조를 집중적으로 연구해서 프론티어급으로 공개하는 딥시크의 행보는 이런 연구배경을 기초로 하지 않나 싶습니다.
not done yet
GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo
트렌드 배경 : LLM은 기본적으로 p(sentence) 를 계산하는 과정인데, token 단위(timestep) 로 보자면 매 timestep t마다 생성한 토큰에 의해 t+1 시점의 P(token_t+1 | token_[1:t] ) 가 계속 달라지므로, 아래와 같이 수식을 전개하여 phi 부분을 RLHF로 사람들이 직접 평가하도록 했습니다.
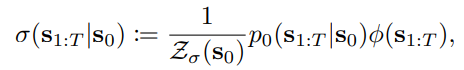
좌측 시그마는 continuous probability function입니다.
기존 문제 : n개의 task i에 대해 데이터 로 학습된 RNN 의 representation z 를 가정할 때, RNN model set D는 로 표현할 수 있습니다. 이 때 로 supervised learning을 수행하는 식으로 learning representations of weight matrices 를 수행할 수 있습니다. 하지만 weight를 직접적으로 학습할 경우 모델 성능이 task의 difficulty에 크게 의존하는 문제가 있습니다. 또한 weight representation learning의 경우 permutation invariance, generalizability 등 까다로운 조건을 만족해야 하므로, 획기적인 방법은 실세계와 동떨어진 어떤 Ideal condition from theoretical induction 에 approximation 하는 형태로만 남아있었습니다.
-
Highlight Figure
논문이 이끌어낸 직관 : RNN model set에 loss function이 직접적으로 접근하는 대신, function emulator A가 만들어낸 결과를 토대로 function embedding을 학습하여, timestep t에서의 RNN 의 동작 을 토대로 RNN weight of 를 예측하는 모델 를 학습합니다. 이를 통해 동작 패턴이 어떤 RNN에 의해 만들어지는지, 해당 RNN은 어떤 task로 학습되었는지 추론할 수 있고, RNN simulator 로써도 훌륭한 기능을 하는 모델을 학습할 수 있습니다.
-
상세 방법
활용방안 및 향후 연구(개인적 의견) : 이 논문은 정말 어마어마한 가능성을 열어준 것과 같습니다. 본 논문의 모델은 task representation으로 연결될 수 있는데, 단순히 classification이 아니라 encoding으로 representation을 만들어낼 수 있기 때문에 파라미터 사이즈 대비 훨씬 많은 RNN function을 재현할 수 있습니다. 그럴 경우 SSM 계열 모델에 매우 큰 기여를 할 수 있게 됩니다.
그뿐만 아니라 time-series, meta learning 등 시도해볼만한 접근이나 활용가능한 분야가 너무 많아서 나열하기 어려울 정도입니다. consistency models처럼 수식을 DE로 유도한다면 그때야말로 특이점에 가까워질 수 있다고 생각합니다.
-
Improving Transformers with Dynamically Composable Multi-Head Attention
트렌드 배경 : RNN의 장점은 단일 가중치로 time series data를 처리할 수 있다는 점이지만, 가중치를 학습하거나 추론하는 과정에 심각한 비효율성이 있기 때문에 transformer로 거의 대체되었습니다. 물론 transformer도 context 길이에 대해 exponential 하게 computation이 증가하는 문제가 있어 대안이 계속해서 제기되는 상황입니다. 이를테면 state space models(SSM) 계열 모델이 있는데, 이는 differential equation이 discreteness를 continuous하게 이어주는 역할을 할 수 있다는 assumption을 기반으로 합니다. 하지만 최근 연구에서 SSM 계열 모델의 성능이 transformer보다 낮다고 지적한 바 있습니다. 그래서 이를 아예 우회하기 위해 RNN의 representation을 mimic한다는 아이디어가 trend로 발전하게 됩니다.
기존 문제 : n개의 task i에 대해 데이터 로 학습된 RNN 의 representation z 를 가정할 때, RNN model set D는 로 표현할 수 있습니다. 이 때 로 supervised learning을 수행하는 식으로 learning representations of weight matrices 를 수행할 수 있습니다. 하지만 weight를 직접적으로 학습할 경우 모델 성능이 task의 difficulty에 크게 의존하는 문제가 있습니다. 또한 weight representation learning의 경우 permutation invariance, generalizability 등 까다로운 조건을 만족해야 하므로, 획기적인 방법은 실세계와 동떨어진 어떤 Ideal condition from theoretical induction 에 approximation 하는 형태로만 남아있었습니다.
-
Highlight Figure
논문이 이끌어낸 직관 : RNN model set에 loss function이 직접적으로 접근하는 대신, function emulator A가 만들어낸 결과를 토대로 function embedding을 학습하여, timestep t에서의 RNN 의 동작 을 토대로 RNN weight of 를 예측하는 모델 를 학습합니다. 이를 통해 동작 패턴이 어떤 RNN에 의해 만들어지는지, 해당 RNN은 어떤 task로 학습되었는지 추론할 수 있고, RNN simulator 로써도 훌륭한 기능을 하는 모델을 학습할 수 있습니다.
-
상세 방법
활용방안 및 향후 연구(개인적 의견) : 이 논문은 정말 어마어마한 가능성을 열어준 것과 같습니다. 본 논문의 모델은 task representation으로 연결될 수 있는데, 단순히 classification이 아니라 encoding으로 representation을 만들어낼 수 있기 때문에 파라미터 사이즈 대비 훨씬 많은 RNN function을 재현할 수 있습니다. 그럴 경우 SSM 계열 모델에 매우 큰 기여를 할 수 있게 됩니다.
그뿐만 아니라 time-series, meta learning 등 시도해볼만한 접근이나 활용가능한 분야가 너무 많아서 나열하기 어려울 정도입니다. consistency models처럼 수식을 DE로 유도한다면 그때야말로 특이점에 가까워질 수 있다고 생각합니다.
-
Doubly Robust Causal Effect Estimation under Networked Interference via Targeted Learning
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling
How Private are DP-SGD Implementations?