Reports about Recent Advances in DL © 2025 by Seunghyun Ji is proprietary licensed.
목차
- 들어가기 전
- New interpretations
- Consolidated Metrics
- New Methods
- Observation-driven Approaches
- Misc
0. 들어가기 전
올해의 best paradigms : Representation Interpretation
diffusion, attention 등 meta analysis를 가능케 하는 도구들이 본격적으로 사용되기 시작하면서, representation을 해석하는 실용적인 연구들이 다수 등장했습니다.
올해 새로 보인 용어 :
1. New Interpretations
Emergence in non-neural models: grokking modular arithmetic via average gradient outer product
TL; DR: SVM-like model 또한 grokking 현상을 재현할 수 있고, 이를 train time에 관측 가능한 metric을 제시했습니다.
기존 문제: ‘왜 accuracy는 이미 높은데 validation loss가 계속 감소할까?’ 라는 의문에서 시작해서, 최근에 grokking이라고 하는, 학습을 거듭할수록 더 정교하고 수학적인 알고리즘을 학습한다는 현상이 발견되었습니다. 하지만 LLM이 언제 어떻게 grokking을 하는지는 밝혀지지 않았고, 이걸 포착하는 연구들조차 특정 LLM 구조에 의존하고 있습니다.
실험 내용: 본 연구에서는 아래 두가지 metric를 제시합니다.
-
Circulant deviation: feature matrix의 diagonal element들이 서로 동일한지 확인합니다. 이를테면, 아래와 같은 matrix는 deviation이 0에 해당합니다. 논문에서는 이 때 matrix가 ‘circulant’ 하다고 말합니다.
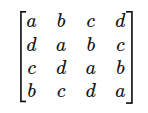
-
AGOP alignment: 데이터 x \in R^n\timesd 로 학습한 신경망 f에 대해, 다음 수식을 계산합니다.
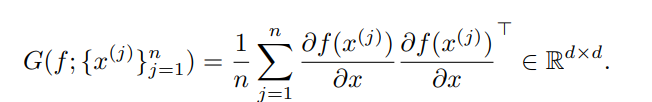
그러니까, 학습한 데이터에 대해 몽땅 자코비안을 계산해서 curvature을 계산한다는겁니다.
그리고 이걸 일반적인 kernel method를 수행하며 학습하는 이른바 ‘recursive feature machine’ 의 매 iteration마다 계산하여, kernel method만으로 modular arithmetic 연산을 어느정도까지 general하게 학습할 수 있는지 관측합니다.
왜?
왜 이런 도구들을 제시했냐 하면, grokking 현상은 feature들이 circulant하지 않아도 발생할 수 있기 때문입니다.
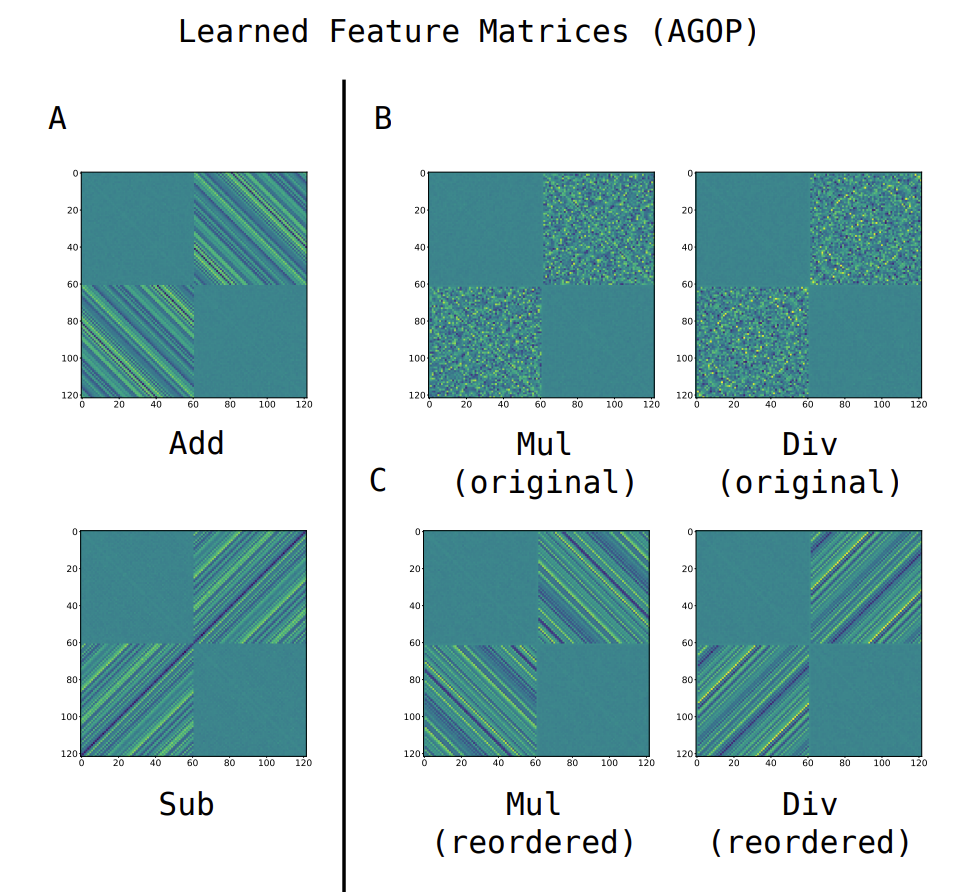
그림 B가 multiplication과 division을 general하게 학습한 모델이라 할 때, feature은 굉장히 복잡하고 circulant하지 않아 보입니다. 하지만 이를 결과에 영향을 미치지 않게 정렬하면 circulant하다는 사실을 알 수 있습니다. AGOP는 feature간의 상관관계를 몽땅 관측하므로 B가 되든 C가 되든 명시적으로 visualize되지 않은 feature에서의 grokking 진행 과정을 명시해줄 수 있습니다.
실험 결과
기존 train loss or test loss만으로는 관측할 수 없었던 신경망 혹은 논문에서 제시한 모델 (RFM)이 numeric operation에 generalize하는 양상을 관측할 수 있었습니다. 특히 grokking 현상처럼 loss가 0에 수렴함에도 feature가 계속해서 변하는 현상까지도 볼 수 있었습니다.
개인 의견
grokking 현상을 제한적인 환경에서 관측할 수 있게 했다는 점은 좋은데, 다른 LLM 등으로 활용하거나 일반화하기는 어려운 metric을 제시해서… 특히 AGOP alignment는 신경망에서 계산하기 너무너무 어려운 metric같네요. 물론 반대로 단순한 SVM-like model로도 충분히 사칙연산을 완벽히 학습하는 모델을 만들 수 있다고 보인 데 의의도 있습니다.
Blink of an eye: a simple theory for feature localization in generative models
TL; DR: critical transition은 step 수가 아니라 delta에 의해 결정됩니다.
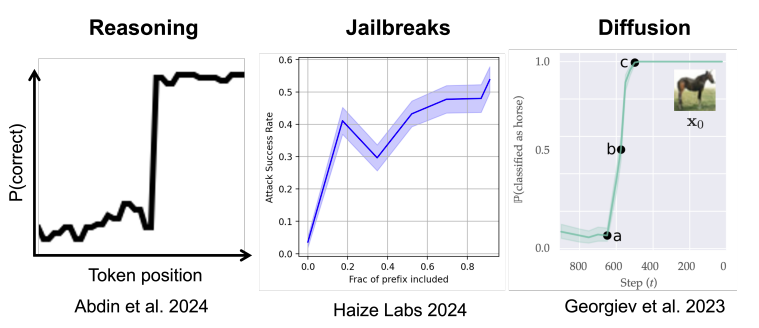
기존 문제: 모델이 추론 도중에 갑자기 출력 결과 확률을 확 뒤바꾸는 현상이 있습니다. 어쩌면 logit으로 스케일링하거나 representation이 특정 task에 대해 수렴해가는 과정일지 모르겠지만, 여태까지는 distribution에 강하게 의존하는 해석만이 있었기 때문에, 일반화하거나 실세계에 적용하기 어렵다는 문제가 있었습니다. 또 diffusion에서는 잘 설명되지만 autoregressive generation에는 아직 해석이 없다는 점도 있었습니다.
-
Applies beyond diffusion to autoregressive models; makes few distributional assumptions; provides quantitative improvements. ICML
-
Empirically, critical windows align with failures on math/reasoning benchmarks. ICML
Weaknesses / caveats. Theory–behavior link is correlational in LLMs; mapping windows to actionable training controls remains open. ICML
Sanity Checking Causal Representation Learning on a Simple Real-World System
TL; DR: Real world causality는 생성된 데이터만으론 학습하기 어렵습니다.
기존 논쟁:
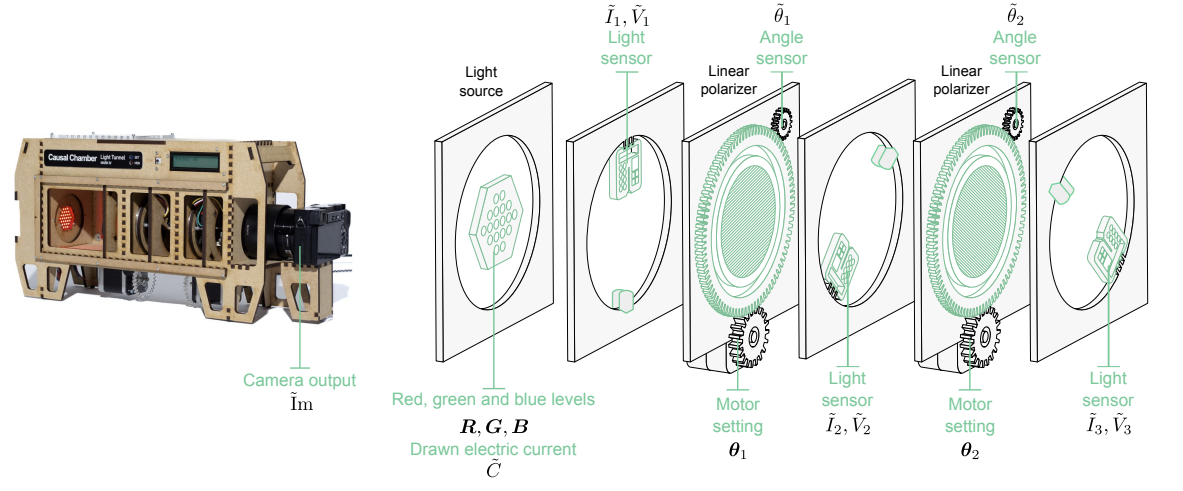
실험 세팅: 아예 그냥 위와 같이 생성된 빛에 대한 representation을 학습할 수 있는지 실험적으로 검증하고자 했습니다. 누가봐도 자명한 parameter가 있으므로, CRL 이론에 따라 충분한 데이터가 주어진다면 representation을 학습하며 parameter를 이해할 수 있으리라 생각됩니다. 다만 빛과 카메라의 특성상 노출 시간을 약간만 늘리거나 빛 소스의 frequency를 조금만 바꾸더라도 꽤 다양한 결과가 나오게 되어, noisy한 데이터를 다양하게 생성할 수 있습니다.
실험에 사용된 CRL 이론은 아래와 같습니다.
- Contrastive CRL: causality를 관측한 상태에서, counterfactual observation case를 생성하여 이들을 충분히 학습하면 causality를 이해할 수 있을 것이란 이론입니다.
Key points.
-
Benchmarks a minimal real-world system designed to be “easy” for CRL; observes systematic failures; highlights role of violated mixing assumptions. ICML+1
Weaknesses / caveats. One domain (optics); results depend on method selection/hyperparams; doesn’t prove all CRL is doomed—shows current gaps. ICML
Probabilistic Modelling is Sufficient for Causal Inference
TL;DR. Argues any causal query can be handled within standard probabilistic modelling by writing a joint over observed and “intervened” worlds—recasting causal tools as conveniences, not necessities. (Position paper; oral.) ICML
Key points.
-
Demonstrates worked examples; reframes do-calculus-style machinery as emerging from generic probabilistic inference. ICML
Weaknesses / caveats. “Write P(everything)” can be intractable; identifiability depends on assumptions you still must state; causal notation often clarifies assumptions succinctly. ICML
2. Consolidated Metrics
Layer by Layer: Uncovering Hidden Representations in Language Models
TL; DR: LLM representation의 성능을 측정할 수 있는 통일된 metric을 제안합니다.
기존 문제: LLM 레이어 중간을 보면 분명 task를 잘 해결하는 representation을 만들기는 하는데, 이걸 해석하기가 너무 어려웠습니다. 해석 전 단계로는 representation의 성능을 측정하는 방법이 있겠으나, 이 또한 여러 이론들이 산재해 있었습니다.
survey: 그간 나온 논문들을 종합해보자면, high-quality representation은 아래 세 요소를 충족할 것이라 추측됩니다.
- representation으로 압축되더라도 기존의 의미를 잘 보존
- semantics in input의 smooth한 변화에 따라 마찬가지로 smooth하게 representation이 변화
- augmentation invariance 혹은 task-based metric
여기에 대해 각각의 metric이 산재했으나, 논문에서는 gram matrix 하나만 사용하면 된다고 했는데,
- diversity: collapse되지 않고 다양한 feature를 사용. rank 측정.
- geometric smoothness: input 변화에 따른 embedding space에서의 smooth한 변화. curvature 측정.
- augmentation invariance: robustness의 일종, representation의 clustering 사용.
그래서 논문에서는 여러 산재된 방법들을 gram matrix 하나를 사용하는 metric으로 통일시킵니다.
실험 결과:
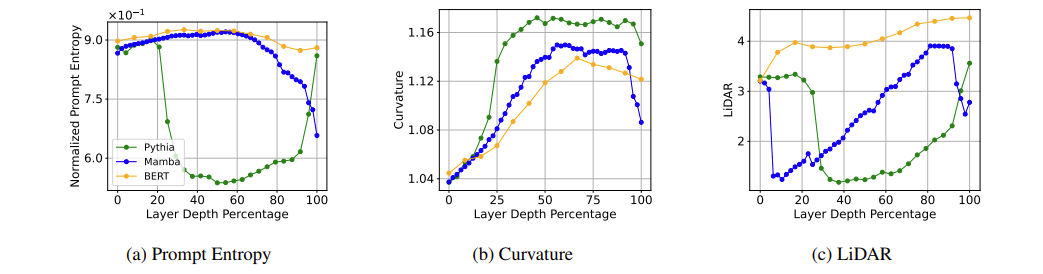
논문에서는 세 방법이 모두 gram matrix 기반으로 작동하므로, 서로 비슷한 상관관계를 보일 것이라 예측했고, 실험 결과 그게 통한 것 같습니다. 이를 기반으로 SSM, encoder, decoder 모델들의 intermediate layer represenation을 관측해봤는데, 여러 기존 연구들에서 발견할 수 있었던 LLM의 성질을 동일하게, 제안된 하나의 metric으로 예측할 수 있다는 것을 보였습니다.
개인 의견:
일종의 survey 논문 느낌은 있지만, 하나의 metric을 제안하고 다양한 현상을 설명해줬다는 데 큰 의의가 있다고 생각합니다. 특히 cot finetuning처럼 overfitting을 유도하는듯한 방법은, 사실 input은 다양하지 않아도 representation의 entropy를 높게 유지시키며 학습하는 방법이기 때문에 성능이 높아진다고 해석할 수 있게 해줬습니다. 또한, vit가 intermediate layer 에서 LLM과 유사한 behavior을 가지기 때문에, vit를 학습할 때도 intermediate layer를 분석하는 작업이 동반돼야 한다고 주장했습니다.
개인적으로 꽤 재미있었던 플롯이 있었는데,
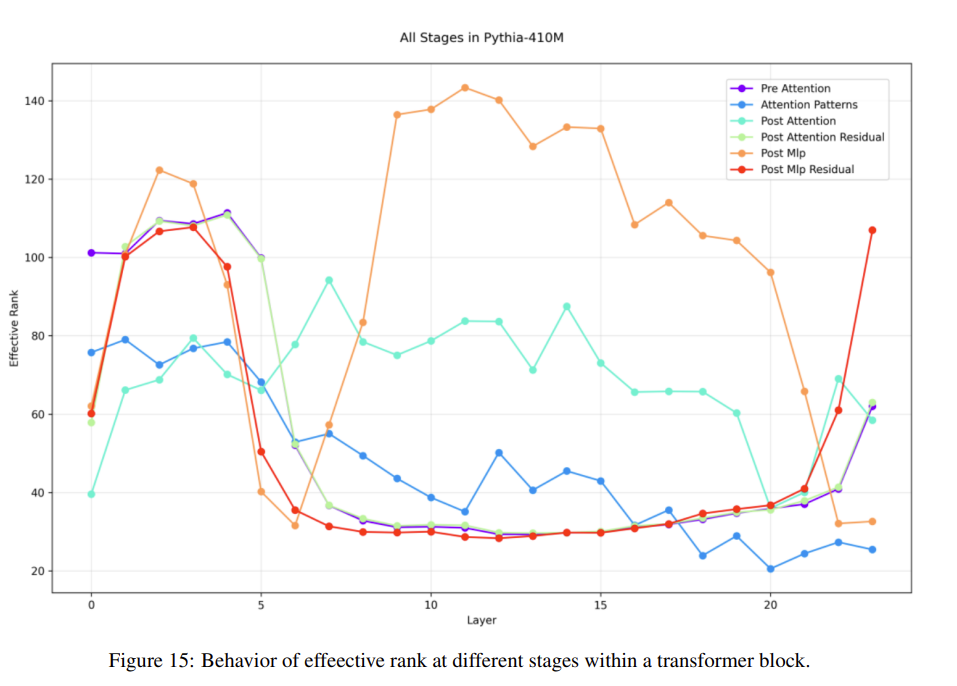
effective rank between post MLP와 post MLP residual의 차이를 통해 residual network의 역할을 추측해볼 수 있는데, 해당 layer에서 만들어낸, 불필요한 representation space 활용을 확 줄여주는게 아닌가 싶습니다.
Understanding Model Ensemble in Transferable Adversarial Attack
기존 문제: LLM API들이 공통적으로 비슷하게 틀리는 adversarial example이 종종 있습니다. 이런 성질을 adversarial transferability라라 하는데, 일종의 adverse generalizability같은 느낌이라 보면 됩니다. 현재까지는 model ensemble을 했을 때 공통적으로 틀리는 example을 찾는 방법이 제일 효과가 좋은 것으로 알려졌으나, model ensemble의 성능은 각 model이 서로 이질적이어야 한다는 점과 adversarial transferability는 example이 general하게 adverse해야 한다는, 상충되는 요소가 있어 개념 자체가 한번에 이해하기 어려운 면이 있습니다.
빌드업
우선 adversarial transferability를 정의합니다. adversarial example z = (x, y)라 하고, 만큼의 perturbation이 부여된 데이터 x의 set 을 가정하면,
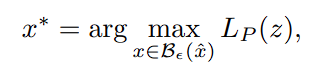
학습 데이터 pool D에서 샘플링한 데이터로 학습된 모델들 P의 loss 기댓값 를 maximize하는 수식을 생각할 수 있습니다.
다만 위에서 언급했듯 model ensemble attack의 variance와 efficacy, 여기서는 vulnerability라 표현한 것이 서로 상충되는데… 어떤 ideal한 adversarial example z*를 가정할 때,
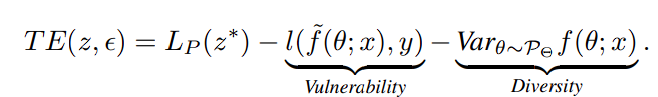
입력 x에 대해 vulnerability는 여러 모델들에 대해 공통적으로 높은 loss를 가져야 하고, diversity는 여러 모델들이 서로 다른 결과를 내야 합니다. 그냥 딱 봐도 tradeoff입니다.
제안 방법: Rademacher complexity를 통해 transferability error의 상한을 제시합니다. 이 때 model ensemble에 대한 complexity 를 제시하여, model ensemble이 만들어낼 수 있는 데이터 추론 결과 Z = X * Y를 가정합니다.
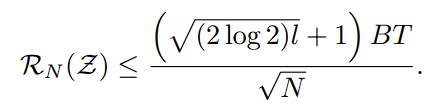
즉, 모델 크기가 클수록 더 다양한 결과를 만들 수 있고, 당연히 모델 갯수가 많아지면 생성 결과의 교집합 영역(생성 모델들이 만들어 낼 수 있는 공통 데이터 수)도 줄어들겠죠? data x의 norm 상한 B와 weight W의 norm 상한 T를 가정할 때, 모델 갯수 N은 크기에 반비례, BT는 비례한다고 볼 수 있습니다.
그리고 갑자기 adversarial transferability를 Rademacher complexity를 사용한 form으로 바꿔버리는데…
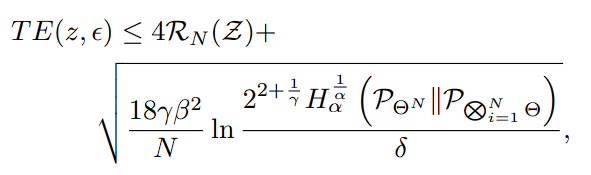
이 수식 유도는 저도 이해를 못해서 넘어가겠습니다. 다만, term은 모델 크기에 비례하고 모델 갯수에 반비례하는 어쩔 수 없는 부분이라 쳐도, 뒷부분은 모델 파라미터 분포가 서로 다를수록 더 커지는 term이라고 설명합니다. 입력 x에 대해 레이블 y를 출력하는 모델은, 파라미터가 작아질수록 분포가 더 크게 달라질 수 있으므로, adversarial transferability는 모델의 수에 비례하고 모델 크기에 반비례하는 수식이라고 해석할 수 있습니다.
실험 결과
Attack Success Rate(ASR)은 평균적인 공격 성공률이니, adversarial transferability로 해석할 수 있습니다.
loss는 example이 얼마나 틀리게 하는지 → vulnerability
variance는 example의 diversity로 상정할 수 있습니다.
weight decay 계수 로 weight norm을 직접적으로 조절한 결과, Fashion-MNIST에 대해서는,
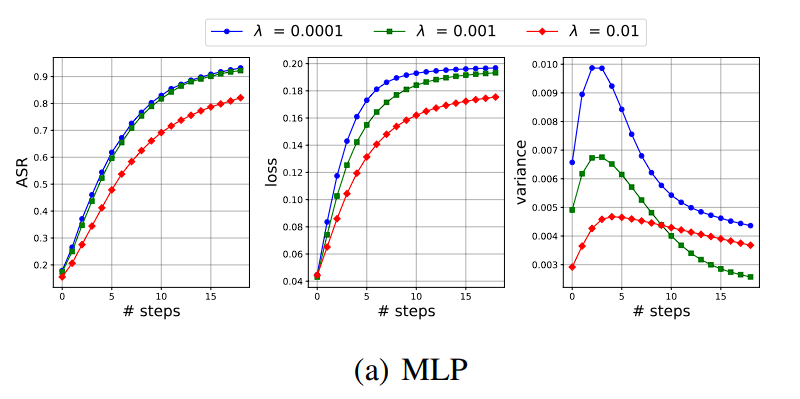
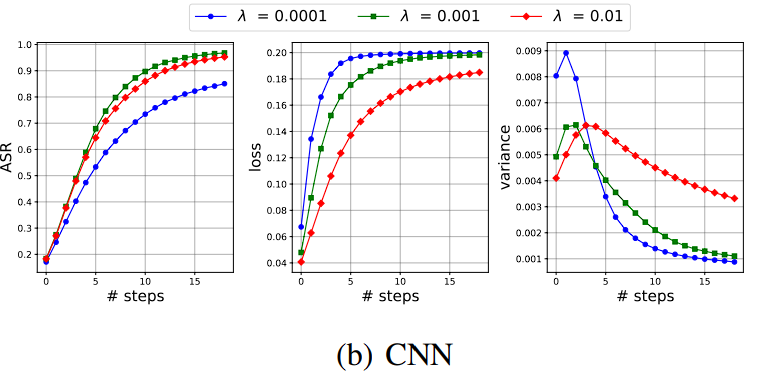
모델 크기가 작을 때보다 클 때 오히려 ASR이 낮은 현상을 vulnerability와 variance를 분리함으로서 성공적으로 설명했습니다.
부차적인 설명으로는, 모델 크기가 너무 작으면 만들어낼 수 있는 adversarial example이 오히려 작아지니 variance가 역으로 작아지겠죠? 또한 MLP보다 CNN이 더 parameter-efficient함을 추정할 수 있습니다.
좀 더 큰 데이터인 CIFAR-10로 가보면 더 명확하게 해석 가능합니다.
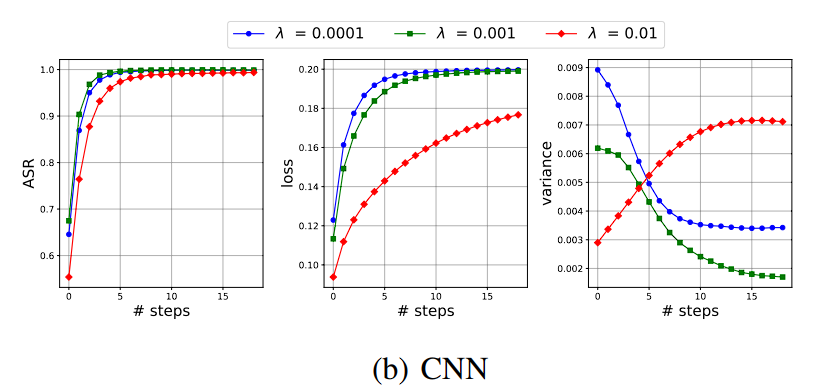
개인 의견: 사실 잘 아는 분야가 아니어서 모델 크기와 ASR이 반비례하는 경우가 있다는 모순이 있는지도 잘 몰랐습니다만, 정말 그런 경우가 있고 작고 많은 모델로 ensemble model attack을 하면 transferable adversarial example을 만들 수 있다는 점은 상당히 실용적인 결론인것 같습니다. LLM에서도 통하는지 확인하기도 쉽고 바로 적용하기도 좋은 방법인것 같습니다.
Learning Dynamics in Continual Pre-Training for Large Language Models
TL; DR:
기존 문제: GPT4.5, Llama4, grok3.5 등 proprietary 대형 LLM들이 대참사가 나고 있는 원인은 아마도 continual pre-training의 어려움이 아닐까 라고 추정됩니다. 그만큼 대형 모델을 지속해서 pre-train하는 것은 매우 많은 문제점을 야기하는데, 이걸 미리 추정할 수 있으면 참 좋겠죠? (돈낭비를 안 해도 되니까)
실험 세팅: 두 데이터를 통해 pre-training을 하는 과정과 중간에 데이터를 바꿔서 CPT를 하는 과정, 네 학습 과정을 기본 베이스라인으로 삼고, CPT를 진행하며 발생하는 distribution shift가 예측가능한지 살펴봅니다. 구체적으로는 두 데이터셋으로 쭉 pretraining하는 과정중 나타나는 validation loss에 맞춰 CPT하는 경우의 validation loss도 따라가는지 보는건데,
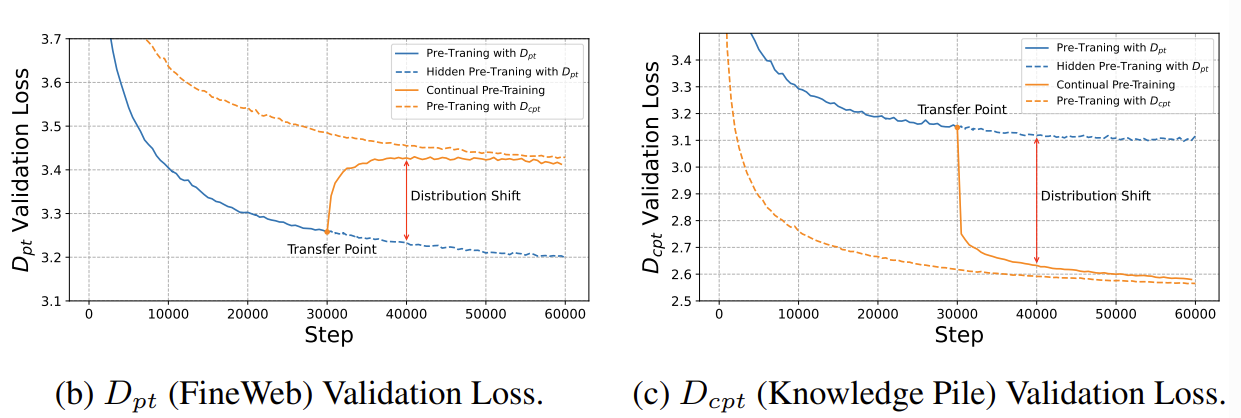
보시다시피 뭔가 특정 구간에서 distribution shift가 일어나는걸 볼 수 있습니다. 별도의 learning rate 설정은 하지 않았는데도 갑자기 뭔가 수렴하는 구간이 생깁니다.
중간에 learning rate를 annealing하는 세팅 등 여러 LR 스케일링 과정
3. New Methods
Optimizing Test-Time Compute via Meta Reinforcement Finetuning
기존 문제: 일명 ‘thinking’ 토큰을 쓰는 cot 방법이 각광을 받고 있지만, cot 체인이 물리고 물리면 마치 ‘자폐’처럼 출력이 이상해지거나, 생각 과정 중 사용자의 의도를 거부하는 등 추론 양상을 조절하기 어려워진다는 문제가 있습니다. 이는 결국 추론 내용을 기반으로 한 출력 결과만이 loss로 작동하기 때문으로 추측됩니다. 물론, thinking 결과에 loss를 어떻게 계산할지 마땅치 않다는 문제도 있습니다.
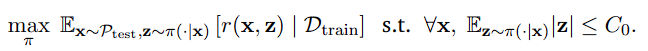
논문의 분석: 우선은 강화학습의 목표는 입력 x에 대해 결과 z를 내서 reward function r(x, z)를 최대화하는 데 있습니다. 그리고 thinking 과정은 budget C_0 내에서 최대로 사용할 수 있는 z의 크기로 놓습니다.
논문에서는 budget C_0를 명시한다는 데 문제점을 제기합니다. thinking을 효용적으로 사용하려면 문제의 난이도나 필요에 따라 thinking을 적당하게 수행해야 하는데, C_0가 fixed 된 케이스라면 thinking scale을 모델이 능동적으로 조절하기 어려울 것이라는 추측입니다. 따라서, 본 논문에서는 ‘budget-agnostic’이라고 하며 어떤 contiguous (논문에서 continuous라고 했어요…) 에 대한 수식의 필요성을 제시합니다.
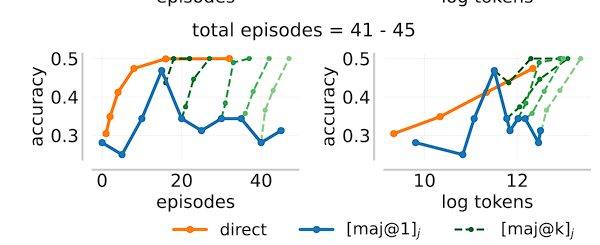
실제로 thinking 과정이 길어질수록 오히려 잘못 추론하는 경우가 더 많아지고, 이는 ‘optimal amount of thinking’ 이 존재한다는 의미가 됩니다. 만약 능동적으로 thinking 과정이 이루어진다면, exploration과 exploitation과 같이 t(<k) 시점의 z_{t}에서 다음 thinking을 수행해야 할지, 아니면 이 잘못되어 다시 검토해야 할지, 아니면 어쨌거나 에 도움이 되는지를 알아서 판단할 수 있을 것입니다.
제안 방법:
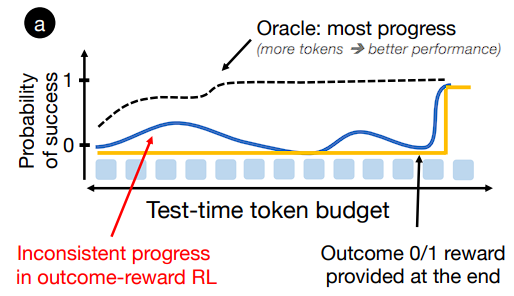
ideal thinking step과 그에 따른 ideal probability function이 있을 때, ‘oracle’ curvature를 기대할 수 있을 것입니다.
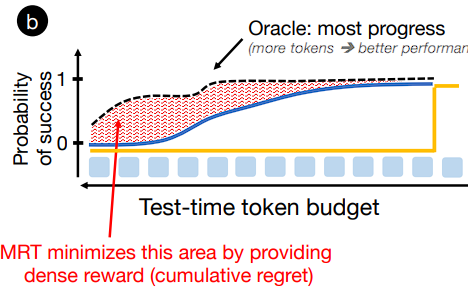
그러면, oracle을 정답으로 놓고 reward function을 학습시키면 되겠죠? 이는 oracle과의 차이가 최소화되는 function이 될 것입니다.
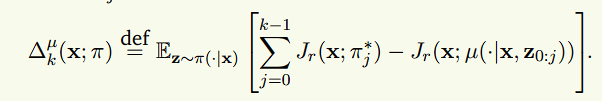
어? 그럼 이거 그냥 적분이네? 라는 생각이 듭니다. 실제로 reward function 를 학습시키는 수식은 위와 같이, binary classification function J에 대해 oracle reward 와 의 차이를 최소화하는 수식이 제안됐습니다.
그럼 finetune도 포함해서 적당한 LLM 학습 수식을 만들 수도 있겠죠? 어차피 thinking은 <think> 태그로 시작되어 출력을 생성하므로 context c의 일부로 간주할 수도 있으니, 입력 내용에 생각 과정을 포함시켜 아예 통으로 c로 간주하고, 그에 후행할 thinking z가 유의미한 개선을 보이는지 확인하는 reward function 를 학습한다면…
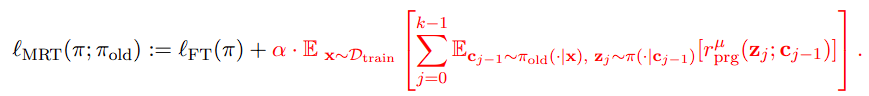
LLM의 학습 방식처럼 매 토큰마다 계산하고 학습하는 수식을 생각해볼 수 있겠습니다.
Figure
친절하게도 그림으로 표현해줬는데, 위에서 설명했듯 budget을 0에서 k까지 증가시키며 thinking 과정을 생성한다음, 이에 대해 평가하는 함수를 학습시키면 됩니다.
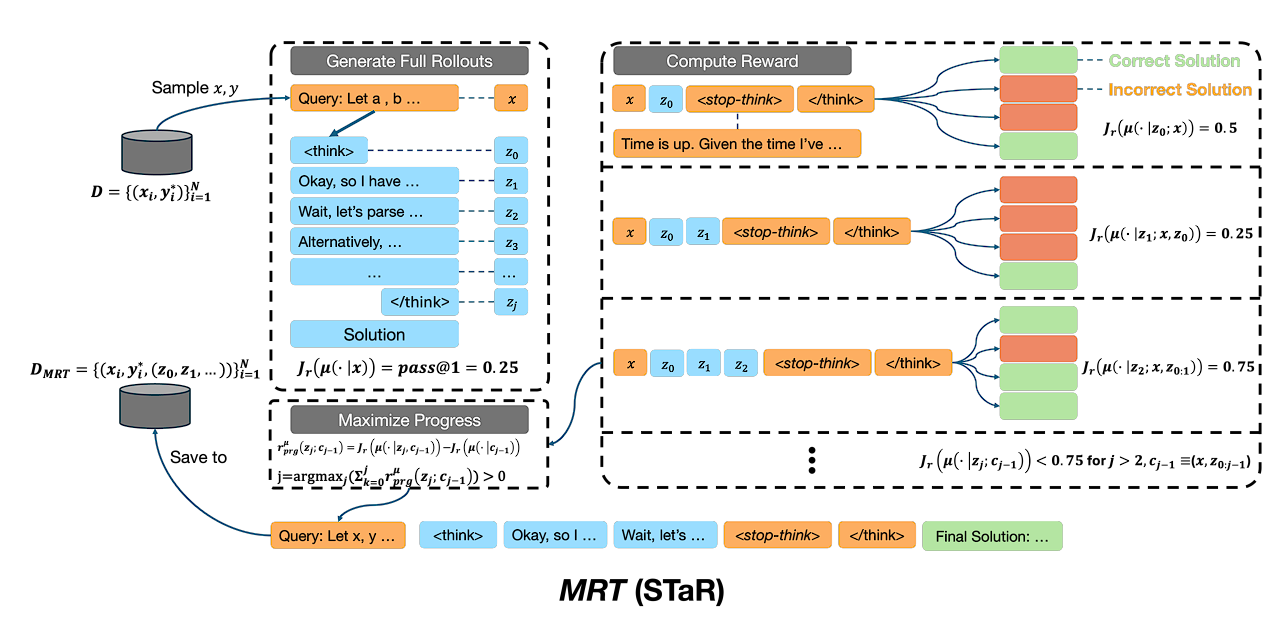
혹은, 실제 강화학습 모델처럼 다음 thinking을 수행할지 말지 판단하는 방식으로 학습할 수도 있습니다. 시점에서 think를 했을 때 출력되는 output의 정답률을 계산하면 되겠죠.
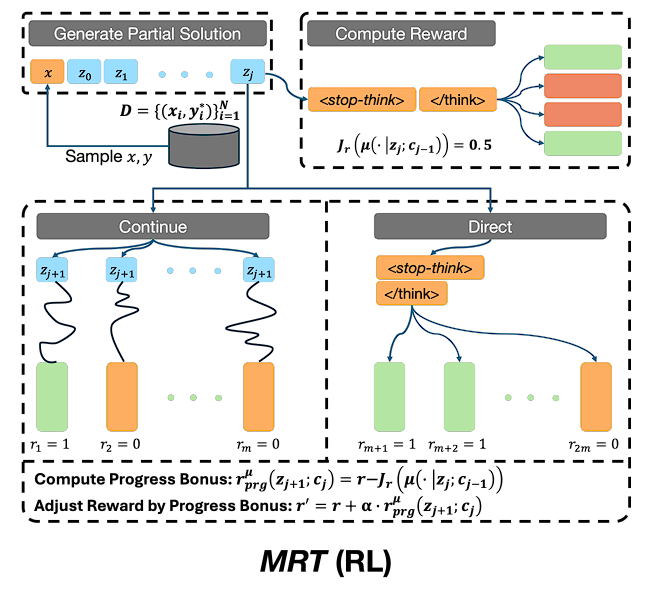
개인 의견: thinking 과정을 어떻게 제어할지 여러 naive한 방법론들은 많이 나왔는데, oracle function을 가정하는 방법은 꽤 나쁘지 않은것 같습니다. 데이터를 얻기도 유용하고 그에 따라 distillation도 유용하니까요. 하지만 결국 누가 더 좋은 베이스 모델을 가지느냐에 따라 결과가 좌지우지되는 방법론이기도 하고, 개인적으로는 올해 2월에 나왔던 gradient descent를 meta-objective로 설정한 논문이 여러부분 더 우위에 있는것 같습니다. 물론 그 논문이 너무너무 놀라워서 그런거지, 이 논문이 별로라는건 절대 아닙니다.
Training a Generally Curious Agent
TL; DR: 스무고개를 잘 하는 능력을 가르칩니다.
기존 문제: 최근 LLM에 결합되고 있는 RL은 결국 explore할지 exploit할지 결정하는 문제라고 볼 수 있는데, 이 균형을 맞추기도 어렵고 특히 LLM에게 있어서는 미지의 분야에 가깝습니다. 다만 ICL 등 연관된 정보를 활용한다면 일반화 능력이 증가한다는 여러 단서는 존재하는 상황입니다.
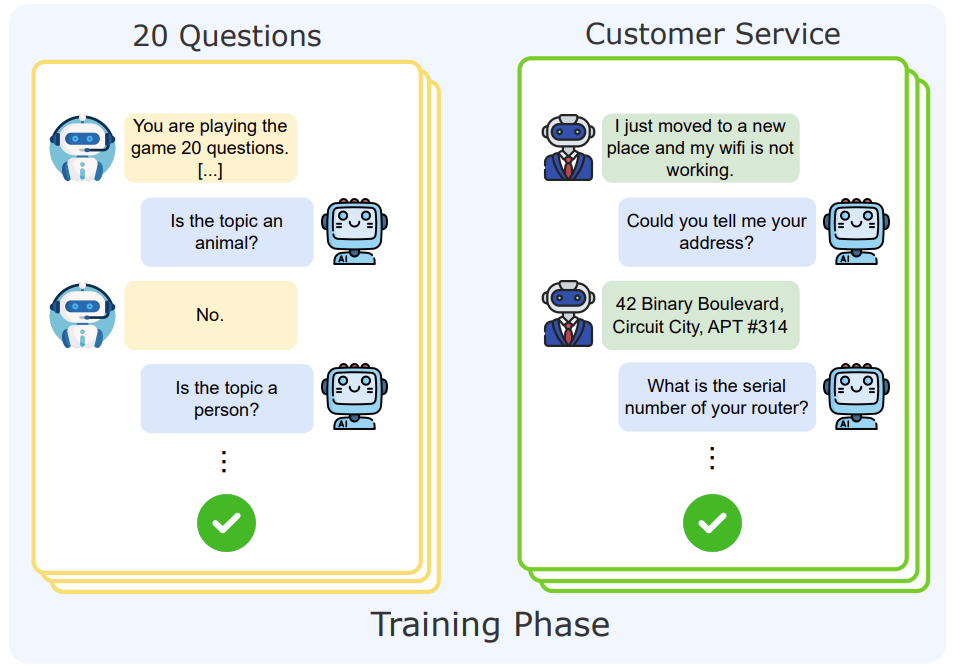
아이디어: 기존 방법들이 정답을 잘 맞추는지를 평가했다면, 이 방법은 스무고개를 잘 하는지를 평가합니다. 질문과 응답 데이터 h = {(o, a)_1, … (o, a)_20} 이 있다고 할 때, 해당 질의응답이 특정 environment를 잘 서술하는지 r(h) 를 통해 평가합니다. 그러면 스무고개를 잘 하는 모델은 r(h)를 최대화하는 모델이 되겠습니다. 자연스럽게 이 모델은 exploration과 exploitation을 잘 하는 모델이 되겠죠?
이 아이디어는 기존 이론들과 정말 잘 매끄럽게 연결되는데, 예를 들어 multi armed bandit problem에서 아주 잘 다루고 있는 문제이기도 합니다. 게다가 실생활에서도 customer service와 같이 고객의 의도를 정확하게 캐치해내는 문제와도 연관되어 있습니다.
실험 결과:

이 데이터셋과 방법으로 학습된 모델은 놀랍게도 DPO처럼 일반적으로 질문자의 의도를 캐치해내는 능력 뿐만 아니라, LLM의 일반화 능력까지 모두 향상시킵니다.
개인 의견:
정말 심플하지만 대단한 방법이면서, 이론까지 모두 깔끔하게 연결되네요 (trajectory). 역시 ICML oral은 퀄리티가 대단한것 같습니다. 이전에 dreamary라는 연구가 약간 떠오르기는 하지만, 이 방법은 좀더 구체화되면서도 이론적으로 잘 설명된다는 차별성이 있습니다.
Core Context Aware Attention for Long Context Language Modeling
기존 문제: long-range context dependency 문제는 아주 유서깊고 유명하기 때문에 생략하겠습니다.
제안 방법의 조건: 본 논문에서는 아래 두 요소를 충족하는 방법을 제안하고자 했습니다.
- attention이 이전의 그 어떤 토큰이라도 참조할 수 있어야 함
- 계산량이 되어서는 안 됨
제안 방법은…
global attention (k-token grouped)
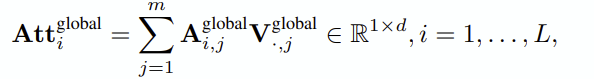
Local attention (sliding window)
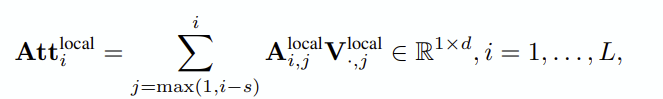
심플하게 이 둘을 합친 것이 되겠습니다.
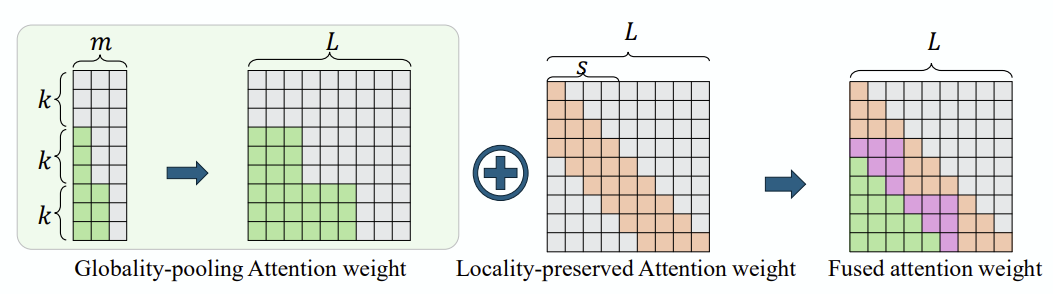
왜 global attention을 저렇게 설정했냐 하면, full attention에서는 주로 문장이나 span의 마지막 토큰에 집중되는 경향이 있기 때문입니다. 따라서, 각 group마다 마지막 토큰의 query에 대해서만 key, value attention을 계산하고, 이걸 ‘global attention weight’로 간주합니다.
개인 의견: 단순하고 간단한 아이디어같아 보여도 span의 마지막 토큰이 중요 역할을 한다는 점, 그리고 마지막 토큰이 group 내에서 어느 토큰에 attention을 주는지를 ‘group attention’의 중요 요소라고 본 점 등이 꽤 디테일하고 좋은 아이디어 같습니다.
Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
Multi-agent Architecture Search via Agentic Supernet
TL; DR:
기존 문제: 기존 에이전트 시스템은 거의 function calling을 여러번 한것과 다름 없는 시스템이라, 사실상 발전이 크게 이루어졌다고 보기 어려웠습니다. 특히 큰 작업을 여러 작업으로 쪼갤 때 기존에 정의된 작업 에이전트들만 사용할 수 있어 그 한계가 명백했습니다.
아이디어:
작업이 아니라 알고리즘 기준으로 에이전트들을 분류하고 구현합니다.
중간에 learning rate를 annealing하는 세팅 등 여러 LR 스케일링 과정
4. Observation-driven Approaches
Great Models Think Alike and this Undermines AI Oversight
기존 문제: LLM의 생성 결과들이 인터넷을 뒤덮는다! 죽은 인터넷 이론! 들이 대두되기 시작하며 LLM이 생성한 데이터를 판별한다던가 여러가지 연구들이 나오기 시작했는데…
분석 결과: 이 연구는 LLM이 다른 LLM을 평가하거나 학습하는 데 보조도구로 쓰일 때, 두 LLM이 제시된 x에 대해 출력하는 결과의 유사도와 효용성이 서로 반비례함을 보였습니다.
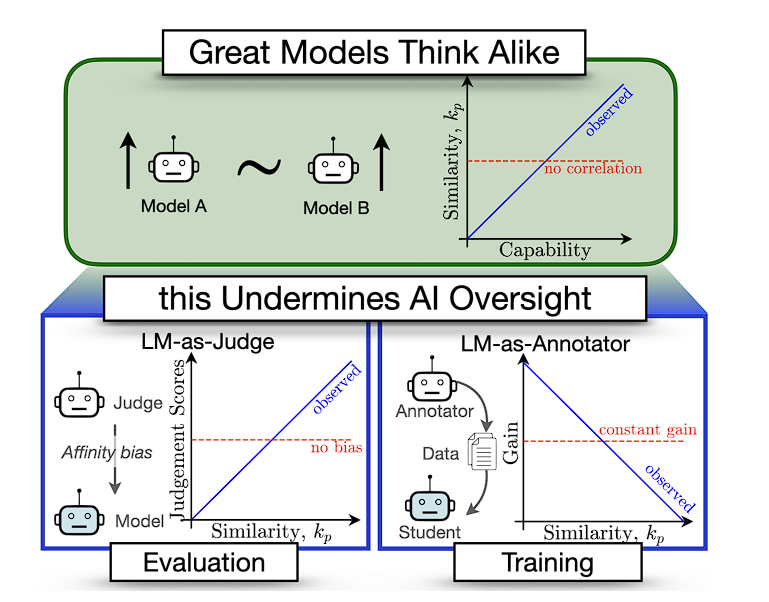
그러니까… model favors their self-generation 논문에서 파생될 수 있는 여러 결론들을 실제로 실험해서 보여준 논문입니다.
개인 의견: 타이밍을 놓쳐서 불쌍하니 걍 붙여준걸까요? 전년도에 너무 상위호환인 연구가 있어서… 그리고 연구가 너무 모델 출력 결과에만 의존하고 있습니다. distillation쪽 연구에서는 훨씬 진전된 담론들이 형성된 것으로 알고 있는데, 조금 실망이네요.
Overestimation in LLM Evaluation: A Controlled Large-Scale Study on Data Contamination’s Impact on Machine Translation
기존 문제: 기계번역에선 데이터의 질이 무엇보다도 중요해서 사실상 어떻게 학습해야 할지보다 어떻게 데이터를 모을지가 중요한데, 문제는 데이터의 퀄리티를 판단하는 데 아직까지도 언어 전문가가 필요하고, 또 시중에 기계번역된 데이터가 너무 많아 제대로된 데이터를 모으기가 어렵습니다.
연구의 주제: 본 논문에서는 여러 실험을 통해 오염된 데이터가 어떤 영향을 끼치는지 알려주는데, 제일 기여가 큰 부분은,
- source 및 target language 모두 오염되는건 문제지만, 한쪽만 오염된 경우 생각보다 모델 학습에 큰 지장이 가지는 않는다. 특히 source의 오염은 큰 지장이 가지 않는다.
- 오염 부분이 생각보다 꽤 많아야 실제 모델 성능에 지장이 간다.
개인 의견: 생각보다 instruction tuning하기 꽤 쉬울수도 있겠습니다.
VideoRoPE: What Makes for Good Video Rotary Position Embedding?
Foundation Model Insights and a Multi-Model Approach for Superior Fine-Grained One-shot Subset Selection
5. Misc
The Best of Both Worlds: Bridging Quality and Diversity in Data Selection with Bipartite Graph
기존 문제: 최근 강화학습된 모델 또한 베이스라인 모델의 성능에 비례한다는 주장이 제기되면서, 학습 데이터셋을 어떻게 수집하고 필터링하는지에 대한 방법론들이 제기되고 있습니다. 물론 강화학습 용으로도 계속해서 데이터 선택 방법론들이 제기되고 있습니다. 다만 데이터 크기가 워낙 크다보니, 이걸 정제할 수 있는 자동화된 metric을 계속해서 찾으려는 추세입니다.
제안 방법: 본 논문에서 언급하는 bipartite 그래프는 그냥 모든 노드가 두 집합 중 어느 한곳에 속하는 그래프임을 의미합니다. 신경망 레이어 구조와 동일하다고 봐도 무방합니다.
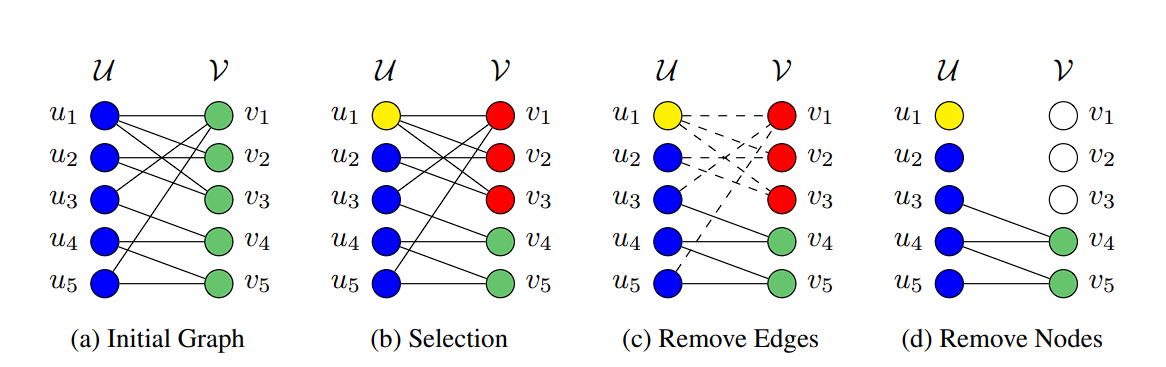
set 1(U)은 data row(sentence), set 2(V)는 n-gram이며, n-gram element를 포함하는 data row와 서로 edge가 생깁니다. 그러면 자연스럽게 edge가 많은 데이터는 중복일 가능성이 높은 데이터라 볼 수 있겠죠?
매우 단순한 아이디어지만 이걸 그래프로 표현함으로써 의 계산복잡도로 정제하고, 정제 기준 또한 비교적 자연스럽게 설정할 수 있습니다.
개인 의견: 음……. 간단하고 좋지만…. 그래프로 표현한것도 좋지만…. 이게 ICML이군요.
Principled Data Selection for Alignment: The Hidden Risks of Difficult Examples
TL; DR: (레이블 노이즈가 아닌) 지나치게 어려운 데이터는 학습을 방해합니다.
기존 문제: 데이터의 중요성이야 예전부터 계속 강조되어 오고는 있지만, 그렇다면 ‘어떤 데이터가 학습에 효과적인지’ 는 아직까지 명확히 밝혀지지 않았습니다. 특히 ‘쉬운 데이터’, ‘어려운 데이터’ 와 같이 데이터를 난이도로 구별하기도 하는데, ‘난이도’와 ‘학습 효용’ 이 어떤 관계인지 또한 밝혀진 바가 없습니다.
전제: 데이터 관련 논문들이 워낙 다양한 가정을 제시하기 때문에 본 논문에선 우선 아래와 같이 정리했습니다.
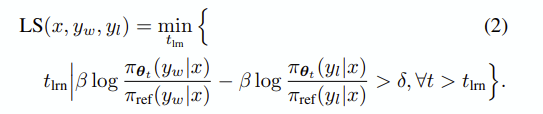
- 데이터 난이도는 레이블(DPO)에 대한 validation loss에 비례하는 수치로 설정한다.
- validation loss 순으로 정렬된 데이터들을 그루핑해서 각각 학습 돌려 성능을 측정한다.
도출된 결과:
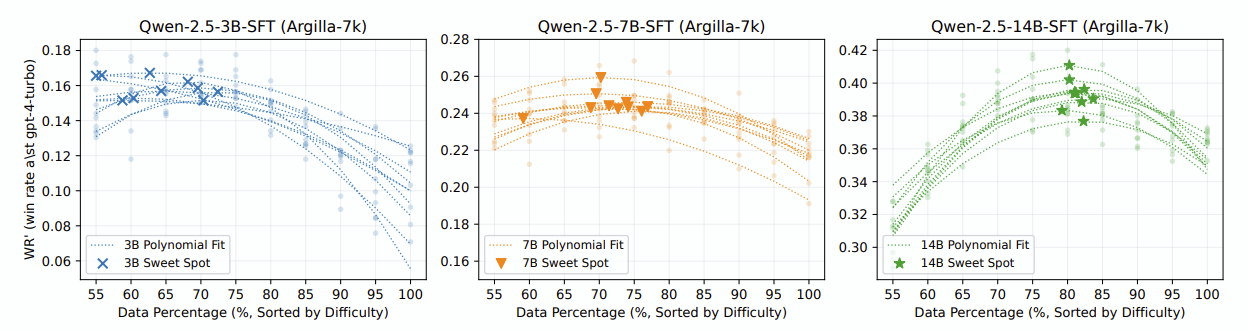
- 어려운 데이터들은 항상 뒤늦게 학습되는(train loss가 낮아지는) 경향이 있다.
- 지나치게 어려운 데이터가 섞여있을 경우, 학습 과정을 방해한다.
- 심지어 커리큘럼 식으로 ‘쉬운 데이터부터 학습’ 해도 마찬가지다. (다만 지나치게 어려운 데이터를 빼면 커리큘럼 방식은 잘 작동한다)
- noise 아니냐? 라고 의심할까봐 확인해봤는데, noise가 아니라 진짜 그냥 어려운 데이터라 하더라도 마찬가지이다.
- 다행히도 모델이 클수록 ‘학습을 방해하지 않는, 데이터의 최대 난이도 임계점’ 이 더 높아진다.
개인 의견: 개인적으로 꽤 재미있었던 플롯이 있었는데,
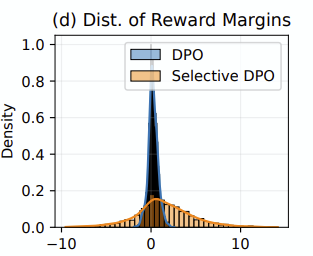
지나치게 어려운 데이터를 제거하고 (여러 모델에 입력했을 때 validation loss가 평균적으로 제일 높았던 데이터들) 학습시켰을 경우, reward model의 density가 오히려 더 broad해지는 경향이 있었습니다. 이걸 보면 ‘지나치게 어려운 데이터’를 없애는 것이 분산을 확 줄여주는 효과가 있는게 아닌가 싶습니다.
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs
TL; DR:
걸 볼 수 있습니다. 별도의 learning rate 설정은 하지 않았는데도 갑자기 뭔가 수렴하는 구간이 생깁니다.
중간에 learning rate를 annealing하는 세팅 등 여러 LR 스케일링 과정
Learning from others' mistakes: Finetuning machine translation models with span-level error annotations
기존 문제: 기계번역에선 sequence 단위 loss가 주로 사용되는데, 사실 대부분의 번역 결과는 일부는 맞고 일부는 틀려서 sequence 단위로 학습하는 데는 한계가 있습니다.
제안 방법:

span 단위 loss를 주는 대신,
- 약간 틀렸거나 많이 틀린 곳은 unlikelihood learning을 씁니다.
- 정답에 해당하는 span은 어떻게 학습하냐? error span이 시작되는 부분부터는 정답 부분이라 하더라도 loss를 계산하지 않습니다. 즉, SFT를 건너뜁니다. 오로지 error span이 시작되기 전 부분만 SFT를 합니다.
개인 의견: 너무 간단하고 단순하긴 한데, SFT를 건너뛴다는 아이디어는 괜찮은것 같습니다.