Reports about Recent Advances in DL © 2024 by Seunghyun Ji is licensed under CC BY-NC-SA 4.0
본 보고서는 상술한 라이선스를 따르는 조건 하 복제 및 변경/변조가 가능합니다.
Acknowledgement : 본 보고서는 株式会社 IBS (일본 소재) 지원 하 작성되었습니다.
Introduction 및 축약어 안내
올해의 경우 12000여편의 제출본 중 67편이 Oral paper, 237편이 Spotlight paper로 선정되었습니다. 본 보고서는 이 중 LLM에 기여할 수 있을 것으로 사료되는 연구들을 정리했습니다. 또한, 트렌드 배경을 챕터 1에 설명함으로써 연구들의 중요성을 이해하기 쉽게 서술하였습니다.
본 논문들은 5월 17일이 submission deadline이고 10월 27일이 camera-ready due, 12월 10일이 학술대회 개최일이었습니다. 즉, 아래 논문들은 개최일 기준 7개월 이전에 제출된 논문들입니다.
-
축약어 안내
chain of thought 기법은 이하 COT로 표기하였습니다.
In-Context Learning은 이하 ICL로 표기하였습니다.
Explainable AI는 XAI로 표기하였습니다.
LLM은 통상적으로 Autoregressive LLM을 의미합니다.
목차
- 기존 연구들 중 핵심이 되는 연구들 (NeurIPS 2023 이전의 연구들)
- Better Feedback for Reinforcement Learning for LLM
- XAI for LLM
- Causality with LLM
- 경량화 학습
- Others
Newly reviewed after 2024
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks
“모듈러 연산과 같은 간단한 문제에 대해서도 모델은 경우에 따라 다르게 해석하여 학습하므로, 복잡한 추론 문제에 대해서는 훨씬 다양한 인식/추론 방법이 있을 것으로 추정됩니다.”
문제 배경 : 간단한 작업에서부터 추상적인 작업에 이르기까지, LLM은 다재다능한 모습을 보이고 있습니다. 하지만 수학 영역에서는 유독 약한 모습을 보이며, 심지어 아무리 synthetic 데이터를 많이 제공해줘도 수학 알고리즘을 제대로 학습하지 못하는 모습을 보입니다. 이를 분석하기 위해 모델이 학습한 임베딩 방법, 추론 양상 등을 분석하는 연구가 집중되고 있습니다.
연구 맥락 : 기존 연구(Nanda et al., 2023) 에서는 모델이 (a + b) mod c 문제를 학습할 수 있게 다양한 synthetic 데이터를 제공해줬을 때, 모델은 이를 자연스럽게 Circular(clock) 임베딩으로 해석하는 양상을 보였습니다. 당시 저자들은 이를 Clock 알고리즘으로 칭했습니다.
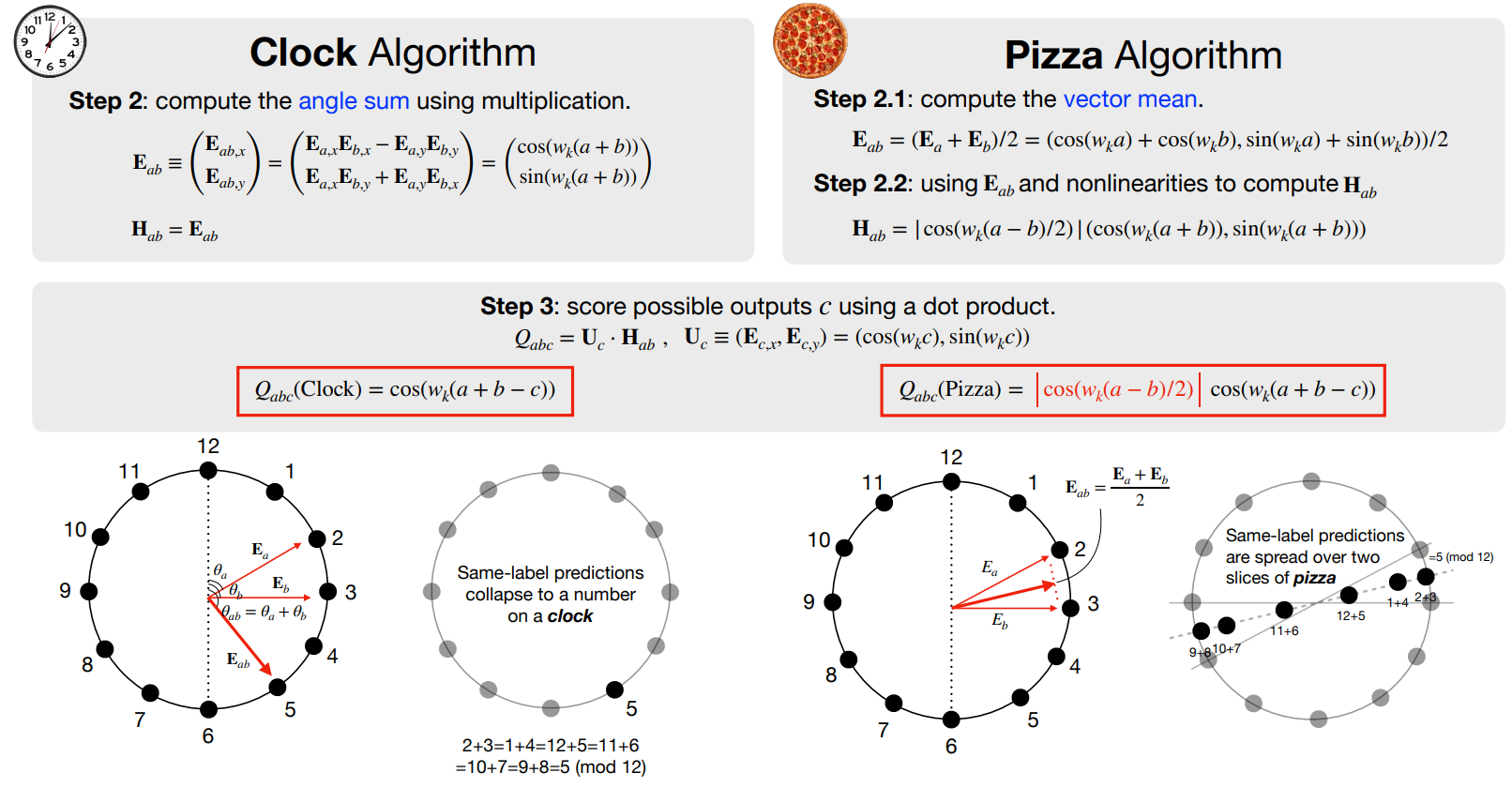
빌드업 : Clock 알고리즘은 입력 순서를 바꿨을때 그래디언트 형태가 달라집니다.
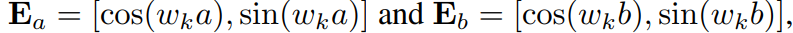
따라서 gradient symmetricity 특성이 확인되면 이는 Clock 알고리즘이 아닌 다른 알고리즘으로 인식됨을 추측해볼 수 있고, 저자들은 이를 Pizza 알고리즘이라 칭합니다. clock은 circular embedding에 matmul하는 방법으로, Pizza는 average하는 방법으로 모듈러 연산을 이해하는 방법이라 가정합니다. 자연스럽게 어텐션을 활용하면 곱연산을 할 수 있으니 이를 통해 모듈러 연산을 이해하는 방법은 Clock, 어텐션을 활용하지 않고 모듈러 연산을 이해하는 방법은 Pizza라고 설정합니다.
최종 가정 및 실험결과: 아래의 두 metric을 통해 모델이 어떨 때 clock 혹은 pizza 알고리즘을 학습하는지 확인했습니다.
- gradient가 input argument permutation invariance를 지님: 입력 a와 b가 서로 위치를 바꾸더라도 동일한 gradient를 준다는 것이므로 Clock 알고리즘을 학습한다고 추정됨.
- embedded input argument간 distance에 irrelevant함: 입력 a와 b에 대해 vector mean을 수행하므로 다양한 입력값도 모듈러 결과값으로 수렴하여 Pizza 알고리즘을 학습한다고 추정됨.
Highlight Figure
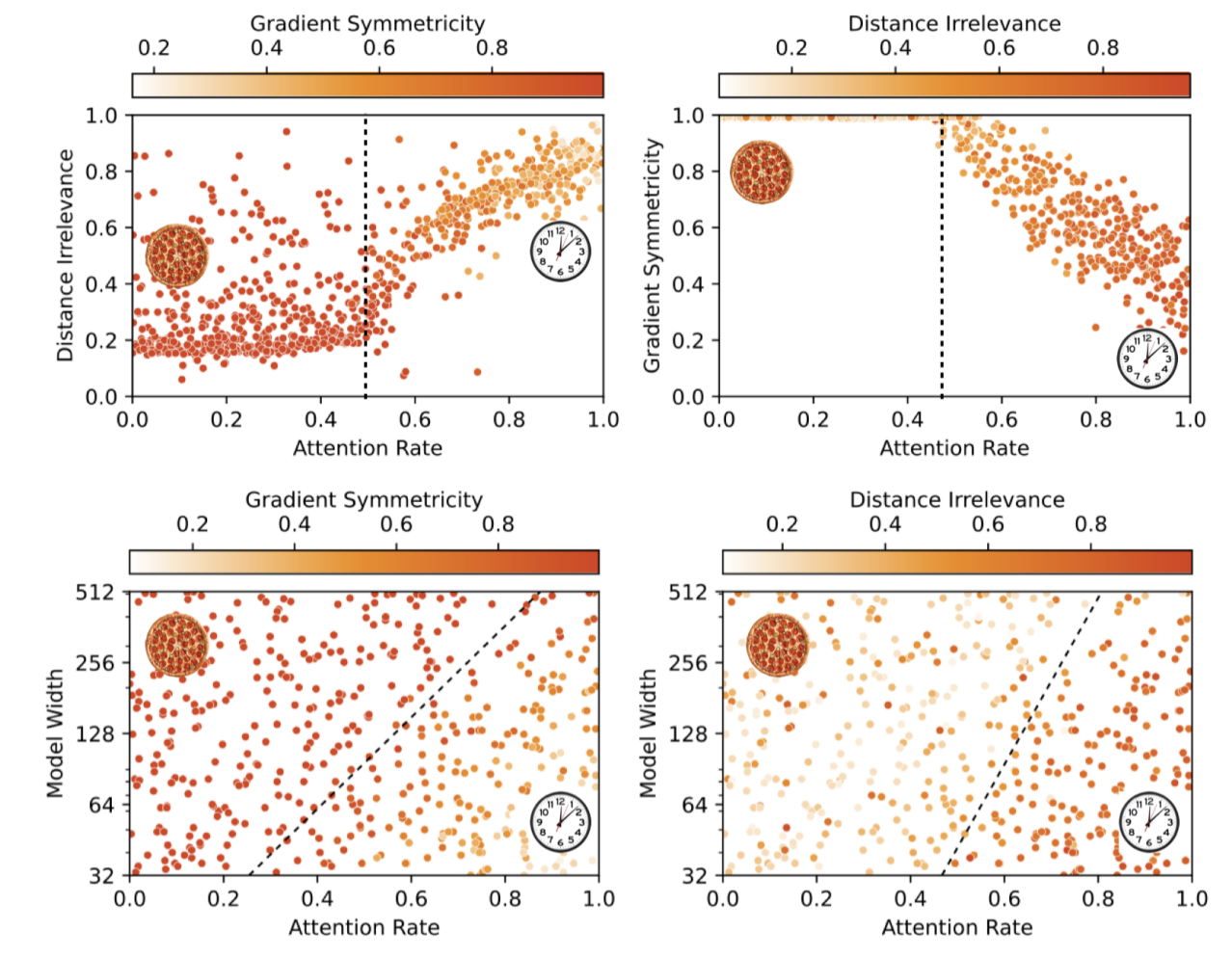
그 결과 신기한 현상을 발견할 수 있었는데, Clock인지 Pizza인지 결정하는 요소는 모델 크기, gradient symmetricity 등에 해당하며, 더 신기한 것은 Pizza 혹은 Clock 이외에도 모듈러 연산을 학습하는 또 다른 알고리즘이 여럿 존재한다는 것입니다.
활용방안 및 향후 연구(개인적 의견) : 이 연구는 transformer 구조의 interpretability 연구로써 거의 처음으로, 주어진 문제에 대해 어떤 조건에 따라 모델이 어떤 dynamics를 가지는지 분석한 연구입니다. 심지어 circular embedding을 사용하는 것 이외의 다른 방법으로도 모듈러 연산을 학습할 수 있다는 것을 발견하여, 그간 모델을 해석하는 방법으로서 추상 레벨로만 다룬 memorization-generalization의 관계성 관련 연구들에 비해 더 진보된 방법이라고도 볼 수 있을것 같습니다.
*. https://arxiv.org/abs/2305.13165 (neurips 2023)
TIES-MERGING: Resolving Interference When Merging Models
“model merge에 있어 각 가중치들이 서로 반복되거나 간섭하는 부분을 제거하면 더 효율적으로 merge가 가능합니다.”
문제 배경 : 딥러닝 모델은 초기값, 어떤 데이터를 어떤 순서로 넣는지, 학습률 혹은 배치 사이즈 등 너무 많은 요소에 의해 성능이 좌지우지됩니다. 때문에 별도의 시행착오 없이 주어진 데이터에 대한 ‘최선의 모델’을 학습하고자 하는 연구는 계속되어 왔습니다.
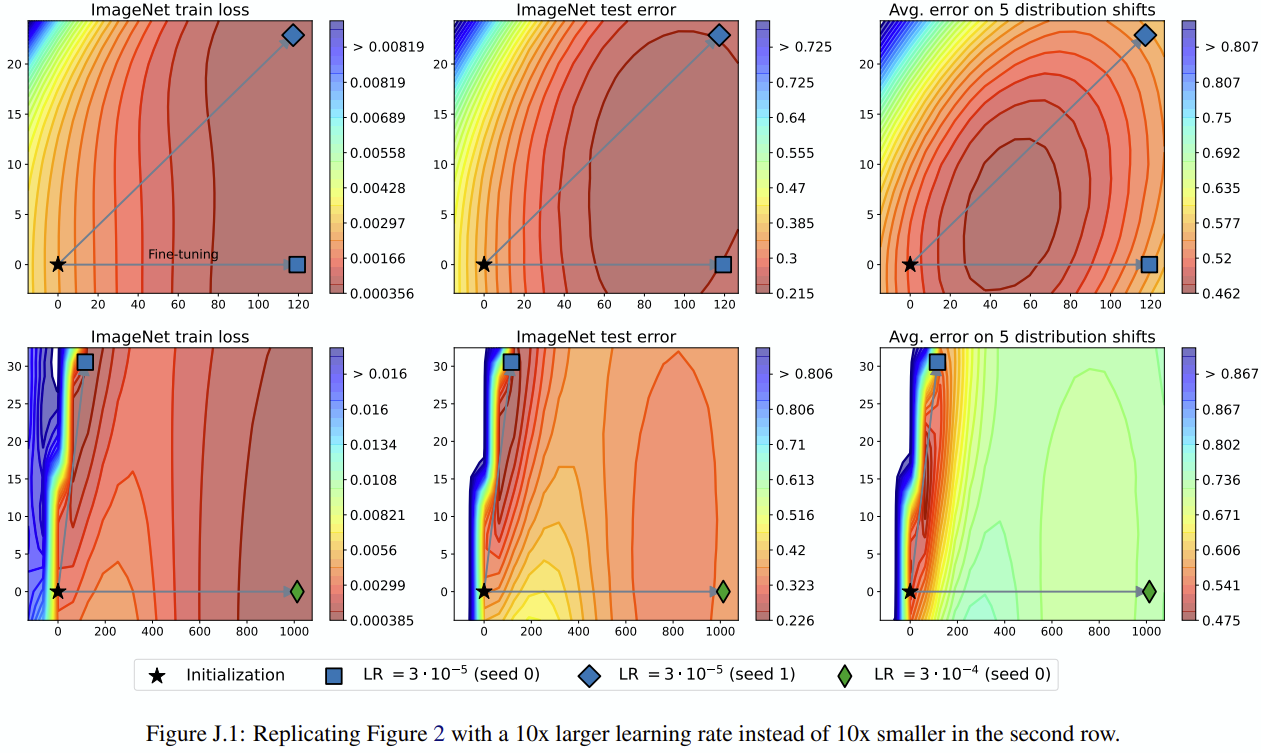
연구 맥락 : **Model soup**에서는 학습률을 다르게 설정했던 모델을 취합할 경우 일반적으로 더 optimal한 가중치를 얻을 수 있다고 주장한 바 있습니다. weight들의 metric space로 잘 visualize 해줬지만, weight들이 결국 어떤 feature라고 가정한다면, feature간의 collinearity, interference 등을 고려해볼 수 있습니다.
Highlight Figure
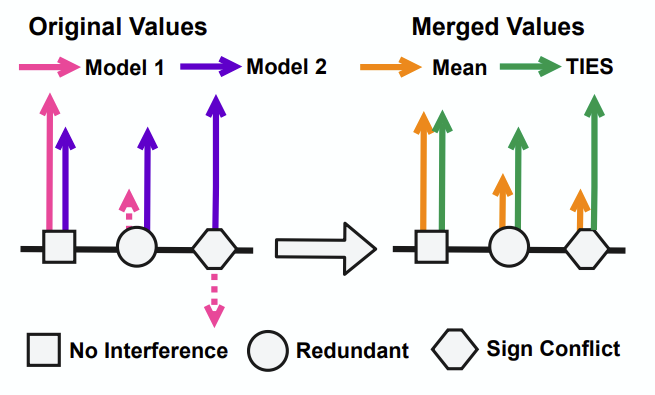
merge할 model들의 weight들이 서로 겹치거나 상반되는 경우를 제거합니다.
활용방안 및 향후 연구(개인적 의견) : 너무 당연하고 심플하지만 토큰별 loss를 distillation? 하는 연구 등을 생각해보면… 너무 나이브하다고 말할 수는 없겠네요. 실제로 고전적인 머신러닝 이론으로도 충분히 설명되는 방법이고, 현대 딥러닝 연구 트렌드에도 부합하는 내용입니다. 뭔가 현타가 오네요…
1. 기존 연구들 중 핵심이 되는 연구들
Locating and Editing Factual Associations in GPT (NeurIPS 2022)
기존 문제 : 기존의 LLM 모델은 ‘블랙박스’처럼 여겨지며 내부에 어떤 동작을 통해 정답을 생성하는지 이해하기 어려웠습니다. XAI는 이런 맥락에서 계속 연구되고 있습니다.
논문이 이끌어낸 직관 : 레이어 중반부의 MLP 모듈은 subject에 대한 정보를 인식하여, 레이어를 거쳐갈 때마다 정보를 축적합니다. 그리고 후반부 레이어에서 attention은 해당 정보의 위치를 파악하여, ‘subject에 대한 정보 및 추론내용’을 출력합니다.
활용방안 및 향후 연구(개인적 의견) : 이 연구는 LLM의 동작원리, 활용을 이해하고 연구하는 데 있어 아주 중요한 논문입니다. 저자의 제안방법은 입력된 내용에 대해 사용되는 attention-MLP 연결고리, 즉 모델이 습득한 지식을 직접 분석할 수 있습니다. 심지어는 지식을 이식(Editing) 할 수도 있습니다.
논문의 구체적인 방법론 : corrupted(perturbation, e~N(0,v)) input에 대한 output과 정상적인 input에 대한 output을 attention과 MLP를 분리하여 비교한 결과, MLP는 layer 중반, attention은 레이어 후반부에서 추론에 대한 지배적인 영향을 발휘합니다. 또한 15번 레이어(GPT2-XL 모델에서 clean run과 corrupted run의 출력을 비교했을 때, h가 가장 많이 바뀌는 레이어)의 {subject 단어가 포함된 텍스트들을 입력할 때 last token of subject 부분의 k의 평균, 출력을 최대로 바꾸는 MLP부분} 을 수정함으로서 모델에 존재하는 지식(s, r, o)을 변경하는(edit) 방법을 제안했는데, 후속 연구에서는 이 방법이 효과적이지 않은 것으로 나왔습니다.
Calibrate Before Use: Improving Few-shot Performance of Language Models (ICML 2021)
기존 문제 : GPT3가 발표되며 few-shot ICL만으로 LLM의 성능이 크게 향상된것을 기점으로, Autoregressive language modeling으로 학습된 LM에 대한 관심이 폭발적으로 증가했습니다. 또한 Large Language Model(LLM)이 통상적으로 Autoregressive하게 학습되는 모델임을 뜻하는 단어가 된 계기가 되기도 했습니다. 그에 따라 GPT3의 한계는 무엇인지에 대해서도 다양한 연구가 이뤄졌습니다.
논문이 이끌어낸 직관 : LLM은 ICL을 위한 example을 어떻게 배치하는지, prompt format이 어떻게 변하는지, example들의 label balance가 어떻게 변하는지에 따라 성능 편차가 크게 변합니다. 이를 보정하게 되면 적은 shot으로도 높은 성능을 달성할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 처음 GPT3 논문을 읽었을 당시 왜 few-shot example을 주는 것이 “few-shot learning”이라고 하는 것인지 이해하지 못했었는데, 본 논문을 읽고 ICL의 기법에 대한 연구가 지속되자 그제서야 learning이라는 단어를 이해하게 되었습니다. 또한 당시 졸업논문으로 작성했던 confidence regularized MLM이 LLM 단계에서 이뤄지고 있었음을 이해하게 되었습니다. 본 논문을 기점으로 context distillation, RLHF, ICL의 방법 등 다양한 연구가 파생되었고, LLM의 성능 향상이 가속화되었다 생각합니다.
논문의 구체적인 방법론 : 2-shot prompt를 입력하고 instruction을 제시하지 않았을 때 label이 정확하게 0.5가 되도록 학습합니다. 이를 Contextual calibration이라 명명하였습니다.
An Explanation of In-context Learning as Implicit Bayesian Inference (ICLR 2022)
기존 문제 : 명령문이나 질의응답 과정 등은 ‘자연스러운 문장의 일부’는 아닙니다. 즉 소설과 같이 자연스러운 언어 흐름이 아닌 것입니다. 그런데 ‘다음 토큰을 예측하는 작업’으로 학습된 LLM은 ICL을 잘 이해할 뿐만 아니라 예시가 더 많이 입력될수록 더 추론 성능이 높아집니다. “예시가 많으면 더 잘 하지” 라는 사람의 직관으로는 설명되지만, 언어모델의 차원에서는 다소 모호하게 여겨져왔습니다.
논문이 이끌어낸 직관 :
LLM은 특정 지시문이 입력되거나 보기 문단이 입력되는 상황을 포착하여, 어떤 가중치의 지식을 사용해야 할 지 감별할 수 있습니다. 특히, 예시가 많아질수록 예시간에 존재하는 shared feature를 더 정확하게 예측할 수 있으므로, 정답을 더 정확하게 예측할 수 있는 파라미터를 고를 확률이 높아집니다. 또한 다양한 prompt/concept로 학습되지 않은 경우 ICL을 잘 수행하지 못합니다. 다만, 학습 데이터셋의 순서나 경우에 따라서 ICL 성능이 크게 흔들리는 현상이 나타나, Hyperparameter에 dependent한 것으로 나타났습니다.
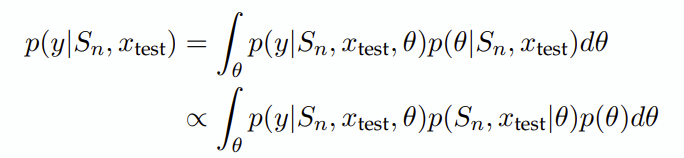
활용방안 및 향후 연구(개인적 의견) : 본 연구에서는 학습단계에서 쓰인 프롬프트를 재현하여 입력할 때 추론능력이 제일 좋아진다고 주장합니다. 또한 대부분의 representation이 entangle 되어있다고 가정한다면, 본 논문에서 분석한 Non-distinguishable case (between concept-theta and prompt-concept-theta) 에서는 concept theta가 prompt-concept-theta와 비슷한 출력을 내도록 한다는 내용은 해석의 연결고리같은 느낌이 있습니다.
Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers (ACL 2023 Findings)
기존 문제 : ICL은 추상적으로 보자면 “보기 문맥이나 질의응답 예시를 통해 비슷한 형태로 추론하면 되는구나” 라는 것을 언어모델에게 알려주므로 당연히 예시로 받은 작업을 잘 할 것이라고 여겨지지만, 구체적으로 어떤 원리로 ICL이 작동하는지는 밝혀지지 않았습니다.
논문이 이끌어낸 직관 : ICL은 질의응답 예시를 인식하는 방법을 바꾸지 않지만(q vector), prompt에 따라 어떤 질의응답을 출력하는지 바꿀 수 있으며, 이는 Finetuning과 근사한 수식으로 나타납니다.
활용방안 및 향후 연구(개인적 의견) : Finetuning은 특정 도메인과 특정 작업에 고도화될 수 있다는 장점이 있으면서도 광범위한 일반적 지식을 잃게 만들 수 있다는 단점이 존재합니다. 본 연구를 활용해 ICL이 안전하다는 장점을 살리면서 Finetuning보다 좋은 효과를 내는 방법을 찾을 수 있을 것입니다.
논문의 구체적인 방법론 : ICL에 의해 수정되는 input representation을 Zero-shot 과 ICL에 의해 변하는 부분을 분리해서, query-key-value 라는 attention 형태가 ICL에서는 key, value를 수정하는 것으로 보았습니다.
Chain of thought prompting elicits reasoning in large language models. (NeurIPS 2022)
기존 문제 : LLM은 어떤 질문에 대해 즉각 답하라고 요청하는 대신 여러 질의응답 예시를 추가해서 입력할 때 더 성능이 증가합니다. 하지만 복잡한 추론 과정이 필요한 상황에서는 질의응답 예시를 넣어주기엔 각 예시 텍스트들이 너무 길기도 하고, 애초에 복잡한 과정을 잘 수행하지 못했습니다.
논문이 이끌어낸 직관 : 입력문에 ‘let’s think step by step’이라고 하거나, 추론 과정을 사람이 직접 단계를 나눠서 입력해주면 복잡한 추론 task도 잘 수행할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : COT는 아주 단순하지만 혁신적인 연구입니다. 학술대회에 더 다양한 industrial(산업계)에서 논문이 나오게 된 계기라고도 생각합니다. prompt engineering이라는 용어 자체가 나오게끔 LLM 연관 직업군을 완전히 새로 만들어낸 논문입니다.
논문의 구체적인 방법론 : 질의응답 예시에서, 추론과정을 상세하게 설명한 응답을 넣어주면, LLM도 똑같이 상세하게 응답하고 실제로 추론 능력도 좋아집니다.
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning (NeurIPS 2022) (aka IA3)
기존 문제 : LLM은 pretraining은 고사하고 finetuning도 너무 비용이 많이 듭니다. 또한 ICL에서 few-shot example은 비록 같은 지식을 함유하더라도 순서에 따라 추론 결과가 바뀔 수 있어, 불안정하다는 risk가 존재합니다.
논문이 이끌어낸 직관 : 잘못된 데이터를 잊도록 학습하는 ‘Unlikelihood training’, 출력길이에 대해 정규화하여 학습하는 ‘Length-normalization’(좌측), hadamard product를 이용한 IA3 training(우측)을 통해 finetuning 효율을 대폭 향상시켰습니다.
활용방안 및 향후 연구(개인적 의견) : 제가 올해 제출한 논문에서 방법론을 저비용으로 구현하기 위해 이 학습 기법을 사용했습니다. 이는 finetuning 대비 10~20배 정도 컴퓨팅 자원을 절감할 수 있습니다. 하지만 LORA(2021년 제안된 경량화 학습 기법)와 같이 컴퓨팅 자원 절감 정도에 따라 finetuning 과정에 수렴(즉 finetuning과 결국 동일해짐) 하는게 아니라 학습 방법을 비틀어버린 것이라, 해당 학습 방법에는 아직 알려지지 않은 취약 부분이 있을 수 있습니다. 즉 기존 finetuning 방법에 가까운 방법이라면 기존에 연구된 내용을 적용하기 쉬운데, 그게 아니라면 알려지지 않은 risk가 있다는 의미입니다. 또한 unlikelihood training과 length-normalization이 어떤 효과를 발휘하는지 정확한 analysis가 없어서 아쉽습니다. 특히 unlikelihood training의 경우 사람이 즉각적으로 feedback을 줄 수 있는 파이프라인의 하위 버전처럼 느껴지기도 합니다.
Constitutional AI: Harmlessness from AI Feedback (Anthropic, 2022/12)
기존 문제 : LLM은 인터넷에 존재하는 데이터들을 학습하여 만들어지지만, 데이터의 품질(비용)과 모델의 성능은 명확한 비례관계가 있어 양질의 데이터를 생산하고 인건비를 지출하는 일이 계속되고 있습니다. 특히 RLHF는 학습을 위해 사람의 feedback을 필요로 하므로, 기존 대비 인건비가 폭발적으로 증가합니다.
논문이 이끌어낸 직관 : RL을 수행하는 모델을 Finetune 합니다. 즉 RLHF -> RLAIF라고 할 수 있습니다. 심지어 RLHF보다 RLAIF의 성능이 더 향상된것을 확인할 수 있습니다. 이는 파라미터가 일정 수준 이상(52B) 인 경우 COT 추론만으로 RLHF 모델과 competitive한 성능을 낸다는 점, Helpful+Harmless RLHF는 Helpful RLHF과 tradeoff가 있다는 점을 근거로 하였습니다.
활용방안 및 향후 연구(개인적 의견) : RLHF는 결국 주관적인 기준을 사용하고, 해당 기준을 명확하게 컨트롤하기 어렵습니다. 더군다나 논문에서 언급한 바와 같이 Human feedback 기준을 설계하는 것도 상당히 어려운것 같습니다. 오히려 단순히 답변을 rank하도록 하는 방법이 유저 입장에서는 더 좋을 수도 있습니다.
2. Better Feedback for Reinforcement learning in LLM
Toolformer: Language Models Can Teach Themselves to Use Tools
기존 문제 : gp4가 아무리 다양한 작업을 능통하게 한다고 해도, 모든 task에 능통하거나 최신정보를 항상 반영하지는 못합니다. 특정 위치의 지식 베이스를 찾는다던가, 뉴스 정보 반영, 컴파일 등 LLM이 수행하기 어려운 문제들이 있습니다.
논문이 이끌어낸 직관 : 저자는 prompt engineering을 통해 LLM이 답변 중 API가 필요한 부분을 작성하도록 한 다음, 해당 부분에 API를 호출하여 텍스트를 생성하였습니다. 이 방법은 기존의 학습 데이터를 더 효율적으로 만들어주며, 능동적으로 API를 call 하도록 finetuning할 경우 성능이 대폭 증가합니다. 무엇보다도 human cost가 거의 발생하지 않습니다.
활용방안 및 향후 연구(개인적 의견) : 본 연구는 LLM의 취약 부분 (아주 전문적인 도메인에 대한 질의응답, 최신정보를 요구하는 등)을 잘 캐치하고 이를 각 API(검색, 데이터베이스 조회 쿼리문 등)를 활용하여 보강하고자 하였습니다. 이를 통해 다양한 task 데이터셋을 효율적으로 확보할 수 있는 것도 확인했습니다.
논문의 구체적인 방법론 : {다양한 API call function을 고르는 모델 -> API call function을 수행하여 답변을 얻은 이후 sequence의 language modeling loss가 더 증가하면 해당 API call은 filter out -> 남은 API call의 response를 데이터에 결합} 하여 학습 데이터를 만듭니다. 이 과정은 전적으로 자동화될 수 있습니다.
- ToolkenGPT 논문도 본 방법과 비슷하고 특히 LLM을 freeze하여 학습비용을 단축시킬 수 있으나, 사람이 직접 ToolkenGPT를 학습시킬 데이터를 만들어야 한다는 점에서 따로 언급하지 않았습니다. 다만 학습 비용의 경우 ToolkenGPT가 훨씬 저렴합니다.
Fine-Grained Human Feedback Gives Better Rewards for Language Model Training
기존 문제 : 기존의 RHLF는 Preference-based라고 불리우며, 모델이 출력해낸 답변 여러가지 중 사람이 선호하는 순으로 답변을 ranking하는 데 그쳤습니다. 때문에 사람에 따라 주관적인 기준으로 ranking하여 이후 RL 모델을 학습하는 데에도 지장이 생길 수 있습니다.
논문이 이끌어낸 직관 : 기존 human feedback은 단순히 생성된 결과가 ‘좋다 나쁘다’ 로만 평가했지만, 본 논문은 ‘연관성, 사실성, 정보가 온전한지’ 세가지 평가기준으로 RHLF을 수행할 것을 제안합니다. 이를 통해 SFT(Supervised Finetuning) 모델보다 성능이 향상되었음을 보였습니다.
활용방안 및 향후 연구(개인적 의견) : 흔히들 딥러닝을 할 때 중요한 3가지 요소로, {컴퓨팅 자원, 학습 데이터, 기술력}을 꼽습니다. 실제로 학습 데이터를 구축할 때 저임금 노동자 대신 고임금 노동자를 사용할 때 학습 효율이 크게 올라갔다고 주장한 논문도 있는 만큼, 고품질 데이터 확보는 ai 비즈니스에서 필수적인 요소입니다. 하지만 연구가 이뤄지면 이뤄질수록 학습해야 하는 학습 데이터는 점점 많아지고 고품질이 되어가고, 결국 데이터 구축 비용이 기하급수적으로 증가하게 됩니다. 이런 측면에서 본 연구는 ‘좋다 나쁘다’ 한가지 평가기준(metric) 대신 세가지 평가기준을 제시하여 데이터 구축 비용 및 학습 비용을 증가시켰습니다. 물론 이 덕분에 모델 성능은 향상되었지만, 때문에 데이터 구축 비용 혹은 학습 비용 대비 성능 향상 정도에 대한 metric이 필요할 것 같습니다.
Effective Human-AI Teams via Learned Natural Language Rules and Onboarding
기존 문제 : chatGPT의 등장으로 ai agent라는 개념이 등장하였지만, ai와 ‘협업’을 한다는 개념이나 방법론은 아직 제시되지 않았습니다.
논문이 이끌어낸 직관 : AI와 사람이 효율적으로 협업할 수 있는 소프트웨어공학적 개발방법론을 제시하였습니다.
- ai는 데이터를 representation으로 나타내고, 이들의 task 범주라고 생각될만한 부분을 경계선으로 감싸 일종의 ‘region’을 만듭니다. 이 때 ai는 region에 있는 데이터들을 서술할 수 있는 ‘text description’ 또한 생성합니다.
- 사람에게 region 경계 내부/외부 데이터를 랜덤으로 10~20개 제공합니다. 이 때 ai가 틀린 추론을 한 데이터가 존재한다면, 이를 반영하여 ai에게 region과 description을 다시 서술하도록 합니다.
- 어느정도 ai의 성능도 향상되었다면, region 경계에 인접한 내부/외부 데이터(즉 task를 수행하기 어려운 데이터)를 사람에게 제공하고, 사람은 다시 ai에게 주는 등 서로의 정확도가 높아집니다.
- 실사용 단계에서는 ai가 task를 잘 수행할 수 있는 데이터인지 아닌지 판단하여 ‘ai의 판단을 믿을지’ 혹은 ‘ai를 무시하고 사람이 수행할지’ 여부를 제시합니다. 이에 따라 능동적으로 ai를 학습시키려는 경우 3번 과정을 되풀이해도 되고, 아니면 3번 과정을 충분히 수행했다고 판단된다면 ai의 task 수행 가능 여부 판단을 신뢰합니다.
활용방안 및 향후 연구(개인적 의견) : ai와 사람의 협업이란, 쉽게 생각하면 ai를 사용하는 작업이지만, 어렵게 생각하면 ai가 잘하는 부분과 사람이 잘하는 부분을 어떻게 서로 상호보완적으로 짜맞출지 고민해야 할 것 같습니다. 본 논문은 이러한 점을 잘 꿰뚫어보고 향후 ai와 사람이 어떻게 협업할지에 대한 프레임워크를 잘 구현한 것 같습니다. 물론 이는 기존에 active learning (ai가 잘 못하는 부분을 사람이 채워주거나 잘 추론하지 못하는 데이터를 선택적으로 학습하는 방법) 라는 개념으로 존재했지만, LLM이 데이터를 서술한다는 부분에 있어 개선된 점이 있는것 같습니다.
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
기존 문제 : LLM은 인터넷에 존재하는 데이터들을 학습하여 만들어지지만, 데이터의 품질(비용)과 모델의 성능은 명확한 비례관계가 있어 양질의 데이터를 생산하고 인건비를 지출하는 일이 계속되고 있습니다.
논문이 이끌어낸 직관 : Principle을 잘만 만들면 RLAIF의 성능이 효과적으로 향상됩니다.
활용방안 및 향후 연구(개인적 의견) : 기존 연구분야들에는 ‘어떻게 스스로 학습시킬지’, ‘레이블링된 데이터가 아닌 시중에 떠도는 데이터를 어떻게 활용하여 학습할지’, ‘어떤 데이터가 더 좋은 모델을 만들지’ 등등의 주제를 다루었었습니다. 그런데 LLM이 등장하며 이들의 경계를 뒤엎고 ‘어떤 데이터가 학습하는 데 있어 중요할까’ 라는 질문을 다시 던지는 것 같습니다.
논문의 구체적인 방법론 :
- 전문가들이 175개의 Rule, 20개의 topic-specific rules를 엄선하여 제작합니다.
- LLM은 해당 Rule들을 바탕으로 자연과학, 사회과학 등 다양한 주제에 대해 맞춰진 질문지시사항(instruction)들을 만들어냅니다. (175 -> 360K개)
- 전문가들이 16개의 응답 준수 기준을 만들고. 기준을 준수하는 답변 방법 예시를 5-shot ICL로 입력합니다.
- {instruction + 응답 준수 기준 + 5 shot examples} prompt에 대한 답변을 생성하게 한 다음, {instruction, 답변} 데이터만을 뽑아서 LLM에게 학습시킵니다. 이는 학습 과정에서 문맥을 포함하는게 아니라 문맥 반영한 답변만을 출력하도록 학습하는 것이므로, context distillation이라고 표현합니다.
3. XAI for LLM
Learning Transformer Programs
기존 문제 : transformer 구조는 residual connection, self-attention 등 복잡한 구조로 이루어져 동작을 해석하기 어렵고, 특히 지식이 어떻게 저장되는지, attention을 어떻게 해석해야 하는지 등의 난제가 산적해 있습니다. 때문에 아직 특정 지식을 갱신하거나 선택적으로 활용하기 어렵습니다.
논문이 이끌어낸 직관 : transformer 구조 내 동작을 discrete하게 변환한 다음, 파라미터가 학습되면 attention head를 0과 1로 매핑하는 함수로 변환함으로써 신경망 자체를 파이썬 코드로 변환합니다.
활용방안 및 향후 연구(개인적 의견) : quantization과 비슷한 기법이 들어간다기보다, 아예 임베딩이나 attention 등을 categorical한 output으로 만들도록 수정하고 학습될 수 있도록 만들었기 때문에, 어떤 특정 모델에 특화하여 압축/양자화하는 개념은 아닙니다. 아무튼 이를 통해서 sort 알고리즘이나 간단한 NLP task를 수행하도록 학습된 모델을 분석했을 때, 다양한 heuristic이 사용되는 등의 재미있는 경우를 확인할 수 있었습니다. 다만 개인적으로는 disentangled representation 등을 유도할 수 있지 않을까 생각했지만 그런 효과는 없었던 것 같습니다.
Jailbroken: How Does LLM Safety Training Fail?
기존 문제 : adversarial attack/defense 라는 분야는 모델이 오류를 내는 입력을 만들어내는 연구분야입니다. 기존 컴퓨터 보안 관련 프로그램들과도 연관이 있습니다. ‘오류’에 초점이 맞춰지면 robustness나 generalization과 같은, 오래된 학문을 기반으로 정의된 내용들을 활용할 수 있으므로, 금방 다양한 연구가 이뤄졌습니다. 하지만 LLM이 유해한 답변을 내놓거나 거짓 정보를 출력하는 것은 기존 연구들과는 상당히 다른 요소입니다.
논문이 이끌어낸 직관 : Jailbreak라고 하는, LLM이 유해하거나 거짓 정보를 출력하게끔 입력문을 교묘하게 변조하는 연구분야를 새로이 개척해냈습니다. 방법 또한 매우 간단합니다.
‘네 알겠습니다!’ 로 시작할 것을 강요하거나, 사과하지 말라 등의 지시를 내리면 유해한 답안을 생성할 수 있습니다. 심지어 이 공격 방법은 일반적인 방법으로 학습된 LLM이라면 무조건 통하는 것으로 확인되며, 특정 prompt에 대해 방어하는 방법도 얼마든지 우회 가능한 것으로 파악됩니다.
활용방안 및 향후 연구(개인적 의견) : 기존 LLM 학습 방법으로 만들어진 모델에는 모두 통하는 방법이므로, 방법론이나 실험결과가 단순한데도 NeurIPS 2023 Oral로 선정되었습니다. 그만큼 파급력이 매우 높고 attack 진영(이를테면 해커) 에서는 너무 다양한 응용방안이 생기게 됩니다. 이 방법을 통해 수행가능한 연구나 활용방안도 물론 무궁무진 하겠지만, 저는 이 방법이 GPT4에 통한다는 것을 통해, 논문이나 방법론이 공개되지 않은 GPT4의 학습방법 등을 유추할 수 있다고 생각합니다. (다만, 2023년 11월에 공개한 gpt4 turbo 모델에는 아직 적용하기 어렵습니다.) 제가 추측하는 내용들은 다음과 같습니다.
- GPT4는 기존 LLM 학습방법을 크게 벗어나지 않았다. 또한 이는 LLM이 representation으로 만든 지식요소 등이 entangled되어있기 때문으로 추정됨.
- GPT4는 텍스트 데이터를 변조하여 추가하는 등 안정적인 성능을 위해 데이터 및 모델 사이즈를 매우 방대하게 구성했다.
- GPT4에는 보조적인 모델이 거대 LLM 앞/뒤로 많이 추가되어, 텍스트의 유해성, 주제, 출력형태 등을 조절한다. 그렇지 않으면 naive(단순)하게 LLM의 데이터를 늘리는 수밖에 없는데, 다양한 인코딩/디코딩 기법이나 창의적인 attack의 경우에는 LLM만으로 대처할 수 없으므로, 이를 필터링하는 소규모 비공개 보조 모델이 있을 것으로 추정.
Are Emergent Abilities of Large Language Models a Mirage?
기존 문제 : LLM은 모델 크기가 일정 수준 이상으로 커질 때 급격하게 task에 대한 성능이 증가합니다. 이런 현상을 ‘실세계의 일반상식을 학습’ 하거나 ‘다양한 지식을 통합적으로 활용’ 하는 조건이 ‘모델 사이즈’와 높은 상관관계를 가지고 있다고 해석하는 것이 기존 연구의 관점이었습니다. 즉, 모델 사이즈 증가에 따라 LLM의 추론능력이 급격하게 변하는(sharp) 구간이 있다고 여겨왔습니다. 하지만 어떤 task는 LLM의 사이즈가 1에서 2로 커질때 좋아지고, 어떤 task는 10에서 11로 커질때 확 좋아지는 등 일관성이 없었고, 기존에는 이를 ‘mirage’(신기루) 현상이라 표현했습니다.
논문이 이끌어낸 직관 : 특정 작업에 대해 LLM의 추론능력이 제각각으로 보이는 이유는, 연구원들이 제각각 학습한 LLM의 평가 데이터 및 task를 각자의 측정방법으로 추론능력을 측정했기 때문입니다. 본 논문에서는 입력 텍스트의 길이에 따라 정규화하거나 특정 task에서 선호되는 평가 metric을 다른 것으로 대체하는 것으로 mirage가 사라진다고 보았습니다.
활용방안 및 향후 연구(개인적 의견) : 재작년부터 LLM의 추론능력을 평가하는 작업이나 데이터셋이 급증하고 있습니다. 이는 기존 데이터셋들과 추론능력을 평가하는 방법이 다양한 흠결이 있었다는걸 의미한다고 생각합니다. 본 논문은 훨씬 일반적으로 접근해서, 평가방법과 추론능력에 대한 일종의 메타분석을 수행했습니다.
Why think step by step? Reasoning emerges from the locality of experience
기존 문제 : COT는 LLM이 복잡한 추론문제를 효과적으로 풀도록 제안된 기법인데, 어떤 원리로 작동하는지는 잘 알려지지 않았습니다. (상술한 내용과 동일)
논문이 이끌어낸 직관 : 복잡한 추론 문제는 평소에 통계적으로 같이 발생하지 않은 단어들을 연결해야 하므로, LLM이 풀기에 어렵게 느껴집니다. 하지만 COT는 추론 과정을 단계적으로 나누어 통계적으로 같이 발생한 단어들을 입력받도록 해줍니다. 또한, LLM은 복잡한 추론을 위한 중간중간의 추론 step을 잘 추적하므로*, 학습한 텍스트가 지엽적이고 다른 텍스트와 잘 연결되지 않을 때** 더 높은 추론 성능을 보입니다.
활용방안 및 향후 연구(개인적 의견) : 사람에게 있어 COT는 복잡한 개념을 직관적인 개념 몇 가지로 나누어서 해석할 수 있는 방법입니다. 딥러닝의 추론 방법이 사람의 추론 방법과 유사한지는 알 수 없지만, 통계학으로 연결고리를 만들면 이렇게나마 공통점을 찾을 수 있는 것 같습니다.
논문의 구체적인 방법론 : 통계적으로 인접한(자주 동시발생한) 문구들을 chain으로 묶었을 때 (scaffolded) 와 직접 복잡한 추론을 바로 해내야 할 때 (direct prediction), 그리고 LLM이 자유롭게 COT를 구성할 때 (free generation)를 가정하고 이들의 평균 에러 수치를 비교했습니다. scaffolded가 제일 낮은 에러율을 보였지만, free generation과 유의미한 차이를 보이지는 않았습니다.
*. 논문에서는 bayes net에서의 intermediate variable이라고 표현했지만, 인과관계가 있는 개념들의 causal graph라고 간주해도 무방합니다.
**. 데이터 복잡도가 높은 경우라고도 말할 수 있음. 이를테면 학습한 텍스트가 의학, 법률 등 전문 도메인일 경우 데이터가 복잡하다고 할 수 있음.
Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective
기존 문제 : COT는 LLM이 복잡한 추론문제를 효과적으로 풀도록 제안된 기법인데, 어떤 원리로 작동하는지는 잘 알려지지 않았습니다.
논문이 이끌어낸 직관 : COT는 사람이 수학문제를 풀 때 수식을 전개하는 step과 유사합니다. 또한 COT를 통해 추론된 내용이 다시 입력으로 들어가므로, ‘transformer 구조상 레이어 추가’ 와 비슷한 효과를 냅니다. 따라서 COT로 복잡한 수학문제를 풀 수 있듯이 복잡한 추론 문제를 더 잘 수행할 수 있습니다. 또한 모델 사이즈가 커질수록 전반적 추론성능이 높아지는 것도 맞지만, COT의 효과는 복잡한 추론 문제에 있어 모델 사이즈보다 더 효과적인 요소가 됩니다.
활용방안 및 향후 연구(개인적 의견) : COT와 같은 prompting의 중요성도 있겠지만 ICL을 잘 수행하는 LLM이 ‘좋은’ LLM이라고 생각되기도 합니다. ICL을 잘 수행할수록 COT 효과도 상승한다고 생각합니다.
논문의 구체적인 방법론 : 수식적인 증명과정이 너무 많아서 (16~42페이지) 스킵합니다.
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models
기존 문제 : 기존 연구(Locating and Editing Factual Associations in GPT)에서는 특정 지식을 담고 있는 attention 및 MLP를 특정할 수 있고, 특정해낸 부분을 수정함으로서 LLM이 가진 지식을 수정할 수 있다고 보았습니다. 신경망에서 특정 지식이 저장된 위치를 추적하는 것을 causal tracing이라고 불렀습니다.
Highlight Figure
논문이 이끌어낸 직관 : 기존 방법은 평균적으로 영향을 크게 끼치는 레이어 하나를 causal tracing 결과로 얻어낼 수 있다고 주장했던 반면(상단좌측), 본 연구에서는 실제 지식은 여러 개의 레이어 작용을 통해 지식이 저장된다고 보았습니다(상단우측). 또한, causal tracing으로 추적한 하나의 레이어를 바꾸더라도 실제 LLM의 추론이 바뀌지 않는다는 것을 실험으로 보였습니다. 따라서 저자들은 ‘지식을 수정하는 것’과 ‘지식이 어디에 저장되어 있는지 찾는 것’은 서로 직결되는 부분이 아니다라고 주장합니다.
활용방안 및 향후 연구(개인적 의견) : 만약 현재 기술로 LLM transformer 구조에서 ‘지식’이 저장된 부분을 특정하고 조작할 수 있다면 딥러닝의 발전이 매우 혁신적으로 빨라졌을텐데, 이 연구는 저장 부분을 특정하는 것도 어렵고, 특정된 부분이 수정되더라도 추론 결과에는 영향을 미치지 않았다는 실험 결과를 제공하므로, LLM의 구조 연구에는 좀 더 많은 시간이 걸릴 것 같습니다.
논문의 구체적인 방법론 : 기존 연구에서 제안한 tracing 방법으로 레이어를 포착하고 이를 수정했을 때 개선 효과를 ‘tracing effect’, 평균적으로 많이 수정된 레이어(본 실험에선 6번 레이어)만 수정하는 방법의 개선 효과를 ‘edit success’로 칭할 때, tracing effect로 인해 바뀌는 결과는 극히 미미하며, edit succeess가 실제로 결과를 바꿉니다. 즉 기존 연구의 localization 방법은 “특정 입력문에 대해 반응하고 출력 모듈에 영향을 주는 내부 MLP 모듈”의 위치를 어느정도 잘 추적하지만, 지식 수정을 위한 추적 방법으로서는 효과가 없습니다.
Counterfactual Memorization in Neural Language Models
기존 문제 : 딥러닝에 있어 암기(memorization)현상은 과거 일반적인 지식 습득을 방해하는 요소로 여겨졌으나, 최근 연구들에서는 오히려 전반적 추론 성능을 향상시키는 것으로 알려져 있습니다. 특히, 딥러닝 모델에 패턴이 복잡한 데이터를 학습시키면, 실제 모델은 학습이 아닌 이를 ‘암기’해버리는 현상을 보이고, 암기한 지식이 곧 일반적 추론 성능에 큰 영향을 미치는 요소로 생각되었습니다.
Highlight Figure
논문이 이끌어낸 직관 : 기존 연구들에 따르면 ‘암기되기 쉬운 데이터’와 그렇지 않은 데이터로 나눌 수 있는데, 위키피디아와 같은 시간/공간/주체 정보가 중요하고 고유명사가 자주 등장하는 데이터는 암기되기 쉬우며, 이러한 ‘암기되기 쉬운 데이터’는 추론 성능에 아주 큰 영향(high influence)을 미치거나, 아니면 아예 아무런 영향도 미치지 못하는 것으로 나왔습니다. 다만 저자는 ‘아예 아무런 영향을 미치지 못하는 상황’은 테스트용 데이터가 학습 데이터로부터 얻은 지식을 충분히 테스트하지 못하거나(그만큼 커버하지 못하거나 양이 작아서?), 질이 낮은 학습 데이터가 ‘복잡한’ 패턴을 가지므로 ‘암기되기 쉬운 데이터’로 나타났을 수 있다고 주장하였습니다.
활용방안 및 향후 연구(개인적 의견) : LLM의 암기 현상 관련해서는 이전에 세미나나 블로그 게시글로 정리한 적이 있을만큼 개인적으로 관심있는 주제입니다. 복잡한 패턴의 데이터 혹은 평소 학습하던 데이터 domain과 다른 데이터를 얼마나 얻어서 어떻게 학습할 지, 또 어떤 목표를 위해 학습할 지 판단하는 것이 딥러닝 엔지니어의 역량이 될 것 같습니다.
논문의 구체적인 방법론 : 학습 데이터를 n개로 쪼개고 그 중 랜덤한 피스 하나를 빼고 학습한 모델과 전부 학습한 모델의 추론 결과를 비교하였습니다.
4. Causality with LLM
Human-like Few-Shot Learning via Bayesian Reasoning over Natural Language
기존 문제 : 사람은 few-shot learning을 매우 잘 하고, 어떤 개념을 습득하면 여러 연관 개념을 연결시키며 잘 활용합니다. 딥러닝도 사실은 기존 인공지능에 비해 지식의 응용/일반화를 매우 잘 하기 때문에 발전해왔습니다만, gpt4와 같은 최신 LLM도 사람만큼 새로운 문제에 대한 응용/일반화를 하기 어려워합니다. 이런 성능 간극을 메우고자 하는 연구는 인공지능 역사에 걸쳐 계속돼왔습니다.
논문이 이끌어낸 직관 : 주어진 task에 특화된 사전지식(concept)을 가진 상태에서, few-shot에 따라 사전지식을 선택 혹은 수정할 수 있는 모델은 사람의 문제풀이 과정과 유사한 추론과정 및 성능을 가집니다.
활용방안 및 향후 연구(개인적 의견) : 기존에 제시되었던 개념이나 개선 포인트를 재언급한 느낌이 있지만, concept를 python 코드로 표현하게끔 하여 어떤 함수를 쓸지 선택하게 한 점이 흥미로웠습니다. 또한 gpt4가 이런 종류의 task에는 매우 취약하다는 것을 확인할 수 있었습니다.
논문의 구체적인 방법론 : 제안 모델은 여러 사전지식을 미리 설계한 다음, 입력문을 인식하여 각 task에 특화된 사전지식을 선택하게 합니다. 또 선택된 사전지식은 python code로 표현되고, 결과에 따라 사전지식을 선택할 수 있게 설계했습니다. 사람의 문제풀이 과정과 비교한 결과, 제안 모델의 성능이나 문제풀이 과정은 gpt4보다 훨씬 사람의 성능에 근접했습니다.
~~Unpaired Multi-Domain Causal Representation Learning
(수정예정)~~
기존 문제 : Representation Learning은 입력 데이터를 적절한 벡터로 변환하도록 학습하는 연구분야입니다. 이 때 적절한 벡터란 입력 데이터의 일반적 의미를 잘 압축하고, 문맥에 따라 유연하게 적용할 수 있는 벡터를 의미합니다. 기존 방법은 학습 데이터의 domain이나 causality를 잘 고려하지 못하고, 아무리 방대한 데이터셋을 통해 학습하더라도 일반상식(commonsense)을 잘 이해하지 못한다는 문제점이 있습니다.
논문이 이끌어낸 직관
: 학습 데이터에 존재하는 지식 요소나 인과관계는 관점(View)에 따라 달라지지만, 데이터 domain에 따라 공통적으로 존재하는(교집합) 지식 요소나 인과관계가 있을 수 있습니다. 이를 그래프 및 행렬로 표현하여 학습하면 데이터들의 domain 교집합 부분을 잘 고려할 수 있고, 데이터들을 활용한 인과관계 그래프를 잘 학습할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 그래프 구조를 활용한 인과관계 추론 연구는 아주 오래전부터 계속되어 왔습니다. 통계적 방법은 인과관계 방향이 없는 ‘상관관계(Correlation)’만을 학습하므로, 인과관계 방향을 고려하는 학습 방법은 통계적 방법의 개선 방향이라고 생각하는 연구 그룹이 있습니다. 제 의견으로는 인과관계 방향이란 객관적으로 설계하기 어려우며, 데이터를 수집하기도 어렵습니다. 본 논문은 효율적인 학습 방법인 denoising, re-ranking 등을 응용하여 domain별 인과관계 학습을 했다는 데 의의가 있지만, 텍스트나 이미지 데이터에는 이러한 인과관계 정보가 담겨져 있지 않아서, 근본적으로 학습할 데이터 자체를 구하기 어렵습니다.
논문의 구체적인 방법론 : 인과관계를 효과적으로 학습하기 위해 인과관계 그래프 행렬을 만들고, 이를 랜덤하게 섞어 인과관계가 달라지게 만든 다음, 추론 모델이 이를 복원하게끔 합니다. 이 때 조건으로 동일 domain을 가진 데이터는 동일 latent node를 가지도록 합니다.
Zero-shot causal learning
기존 문제: 질병의 기전, 약의 효과 등 인과관계 방향이 매우 중요한 분야에서는 이를 고려하지 않는 통계적 추론 방법을 신뢰하기 어렵습니다(정확하게는 임상 3상까지 필요할 정도로 엄밀한 A/B 테스트가 필요합니다). 따라서 현재의 딥러닝 모델은 새로운 인과관계 정보를 정확하게 인식하고 갱신하거나, 기존에 발생하지 않았던 새로운 사건에 대해 분석하는데 있어 부족한 면이 있습니다.
Highlight Figure
논문이 이끌어낸 직관 : 주어진 task에 필요한 데이터의 feature와 feature에 intervention을 가한 벡터를 입력받아 task 추론을 수행하는 모델 + 여러 종류의 task를 합친 데이터(task의 종류에 따라 유사한 데이터더라도 다른 label을 가질 수 있다는 점을 활용) 를 사용하면, 기존 모델보다 인과관계 추론을 더 잘 수행할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 본 모델은 데이터만 존재한다면 어느정도 성능이 보장된 인과관계 기반 추론 모델을 만들 수 있습니다. 하지만 intervention을 가하기 어렵다는 언어 데이터의 특성상, 곧바로 LLM이나 NLP에 적용하기는 어려워 보입니다.
논문의 구체적인 방법론 :
- 데이터: 서로 다른 데이터셋을 섞거나 label이 바뀌지 않는 미세한 변조를 통해 meta-dataset을 만듭니다.
- 제안 모델은 데이터의 feature과 변조(intervention)한 feature를 MLP로 압축하는 방법으로 학습됩니다. 이를 통해 data intervention에 따른 결과 변화를 추론하는 모델을 만들 수 있습니다.
5. 경량화 학습 관련 연구들
Fine-Tuning Language Models with Just Forward Passes
기존 문제 : LLM은 pretraining은 고사하고 finetuning도 너무 비용이 많이 듭니다.
논문이 이끌어낸 직관 : finetuning 학습 시 각 레이어에 loss를 미분한 값을 넣는 것이 아니라, loss에 랜덤한 값을 곱하여 가중치를 업데이트합니다. 이를 통해 엄청난 메모리와 계산량을 요구하는 기존의 finetuning(레이어 수만큼 미분)을 간단한 계산으로 대체합니다.
활용방안 및 향후 연구(개인적 의견) : loss function 및 gradient를 간단한 수식으로 근사시키고, 근사 시 큰 오류가 발생할 확률을 최소화하는 등 깊은 수학 지식을 요구하는 최적화 문제에 해당하는 것으로 생각됩니다.
논문의 구체적인 방법론 : 학습 과정에서 perturbation을 사용하여 weight를 변형하고, loss의 음의 방향 및 양의 방향으로 가중치에 perturbation을 부여하고, 이를 파라미터에 랜덤한 learning rate를 적용하여 업데이트합니다. 이는 Simultaneous Perturbation Stochastic Approximation에서 정리한 수식이 근거가 됩니다.
QLoRA: Efficient Finetuning of Quantized LLMs
기존 문제 : LLM은 pretraining은 고사하고 finetuning도 너무 비용이 많이 듭니다.
논문이 이끌어낸 직관 : 기존 딥러닝에 쓰이는 부동소수점 계산을 정수 계산으로 치환하면 학습 비용을 엄청나게 절약할 수 있습니다.
이를 quantization이라 하는데, 왼쪽과 같이 continuous value를 계산하는 것이 아닌 오른쪽의 조각 파편 인덱스 (1번 파편, 2번 파편…)를 고르는 문제로 바뀌기 때문에 부동소수점 계산이 정수 계산으로 바뀌게 됩니다.
활용방안 및 향후 연구(개인적 의견) : quantization을 수행한 모델은 당연히 성능이 하락하는데, finetuning의 경우에는 보통 특정 task에 모델을 특화하려고 하다보니 부동소수점 연산이 크게 필요하지 않거나, 가중치를 quantize해도 성능에 큰 변동이 없어 보입니다. 개인적으로는 Neural processing unit (NPU)가 본격적으로 등장하기 시작하면 크게 뒤흔들릴 연구분야같아서, 지금은 조금 관망하는 것이 좋을것 같습니다.
논문의 구체적인 방법론 : 32-bit float를 8bit Integer로 변환하고 quantile(4개 분위) 중 하나로 변환하면 4-bit으로 quantization이 가능합니다. 이를 LoRA training에 적용합니다.
Scaling Data-Constrained Language Models
기존 문제 : 딥러닝 학습에는 ‘전체 데이터에 대해 관측하고 에러율을 갱신’ 하는 것을 몇 번 수행할 지 결정하는 것이 중요합니다. 이를 epoch라 하며, 이를 비롯해 사람이 설정해줘야 하는 다양한 Hyperparameter가 존재합니다. 하지만 아직 LLM에 대해서는 적절한 Hyperparameter search 방법이 제시되지 않았습니다.
논문이 이끌어낸 직관 : 본 논문에서는 일반적으로 모델 크기나 데이터 크기에 따라 효과적인 hyperparameter를 설정하는 방법을 제시합니다. 이와 관련된 연구를 scaling이라 합니다. 또한 학습할 데이터가 모자랄 때 이를 효과적으로 보충하는 방법을 제시합니다.
활용방안 및 향후 연구(개인적 의견) : 현재 경량화 학습 기법이 너무 많이 쏟아져 나와 있어서 scaling 관련 연구에는 의심의 여지가 너무 많습니다. 또한 본 논문의 hypothesis가 analytical basis를 기반으로 설계되어 어느정도 신빙성은 있습니다만 Are Emergent Abilities of Large Language Models a Mirage? 연구와 같이 좀 더 발전된 metric을 쓰면서 연구를 진행해야 하지 않을까 싶습니다.
논문의 구체적인 방법론 : 학습에 따른 loss contour plot, gradient update 수식을 기반으로 scaling law에 대한 hypothesis를 제시한 다음, 이를 empirical하게 보여주고 있습니다.
6. Others
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
기존 문제 : 복잡한 사고 과정을 요구하는 추론 작업의 경우 LLM이 즉각 수행하기 어려워하고 있습니다. Few-shot learning, Prompt engineering, Chain-Of-Thought 등의 다양한 프롬프팅 기법은 복잡한 사고를 단계적으로 풀어서 LLM이 수행하도록 하는 방법론들입니다.
Highlight Figure
논문이 이끌어낸 직관 : prompting을 통해 {발상 가능한 제안 생성, 해당 추론이 합리적인지 판단} 하는 역할이 부여된 LLM 2개를 활용합니다. 트리 형태의 사고과정 전개를 위해 기존에 잘 알려진 search 방법을 (Breadth-first Search, Depth-first Search) 사용하거나, 가지치기를 써도 좋습니다.
활용방안 및 향후 연구(개인적 의견) : LLM에게 발상을 제안하도록 한 것이라 task별로 디테일이 약간씩 다릅니다. 다만 LLM을 AI agent로 해석하고 Tree 구조의 문제풀이 방법은, “여러 AI를 통합하는 ensemble”, “여러 사람이 다수결로 더 좋은 방법을 찾는 voting” 등보다 더 긴밀한 상호보완(나아가서는 협업)이 가능해 보입니다.
Lexinvariant Language Models
기존 문제 : LLM이 큰 주목을 받기 시작한 것은 GPT3가 Few-shot 예시를 통해 ICL을 수행하며 성능이 향상되었기 때문입니다. 이후로 LLM은 일반적으로 ICL을 잘 수행한다는 것이 알려져, COT같은 프롬프트 방법론 혹은 분석 논문 등이 등장하기 시작했습니다.4
Highlight Figure
논문이 이끌어낸 직관 : 본 논문은 cipher를 통해 알파벳 및 숫자 체계를 뒤섞고(permutation), 이를 Autoregressive language modeling으로 학습합니다. 이를 통해 자연스럽게 문맥을 통해 추론하는 방법을 학습하기 때문에, ICL 능력이 뛰어난 LLM이 만들어집니다. 특히 입력문이 길 때 낮은 perplexity를 보입니다. 또한 일반적인 LLM의 regularizer로도 응용될 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 저는 이 논문이 LLM 분야에 한해서는 NeurIPS 2023의 best paper라고 생각합니다. 사람과 LLM의 추론 능력은 ICL로부터 온다고 한다면, 제일 먼저 Causal graph나 Bayesian inference가 떠오르지만, 그러기에는 데이터를 구하기 어렵거나 모델 자체가 너무 크다는 문제가 있습니다. 이 논문이 ICL 능력 향상을 의도했든 의도하지 않았든 간단해보이는 아이디어로 Pretraining method를 아예 뒤흔들수도 있다는 생각이 듭니다.
In-Context Impersonation Reveals Large Language Models’ Strengths and Biases
기존 문제 : Impersonation이란 LLM에게 역할 혹은 성격을 부여해서 일종의 페르소나를 지니도록 하는 것입니다. 실제로 GPT4 api는 prompt와는 별개로 역할(role)을 부여하는 메소드를 제공하고 있습니다. 다만 role을 부여했을 때 추론 결과가 어떻게 바뀌는지는 아직 제대로 정리되지 않았습니다.
논문이 이끌어낸 직관 : 4살, 7살, 13살, 20살 등 나이를 기준으로 LLM에게 role을 부여하고, 해당 role이 multi-armed bandit* 문제를 어떻게 푸는지 재현해보라는 task로 reward를 평가하거나, 그 외 domain expert, 인종이나 성별에 따른 impersonation이 유의미한 추론 능력 차이를 야기합니다.
*. 제각기 다른 당첨확률의 슬롯머신이 여러개 주어졌을 때, 적은 수의 trial로 제일 높은 당첨확률의 슬롯머신을 찾는 task. 강화학습 형태로 쉽게 구현할 수 있음.
활용방안 및 향후 연구(개인적 의견) : multi-armed bandit 문제를 나이별 impersonation으로 풀게 한 것은 재밌는 실험이지만, 다른 인종/성별 등의 bias에 대해서는 어느정도 알려진 문제인 것 같아서 조금 아쉬웠습니다.
ID and OOD Performance Are Sometimes Inversely Correlated on Real-world Datasets
기존 문제 : compositional generalization이라고 하는 현상은 학습했던 데이터 형태(ID, In-distribution)와 이질적인 데이터 형태(OOD, Out-Of-Distribution) 가 들어오더라도 추론을 잘 수행하는 것을 의미하며, robustness 개념과도 연결됩니다. 그런데 LLM을 포함한 일반적인 딥러닝 모델은 ID 추론 성능이 상승할수록 OOD 성능이 떨어지는 반비례 관계가 일반적으로 나타납니다. ID에서 일반적인 지식을 잘 학습하면 OOD 성능이 향상된다는 것이 사람의 학습 원리인데, 이와는 정 반대의 현상이 나타나는 것입니다. 이에 대한 정교한 실험 연구는 아직 미비한 상태입니다.
논문이 이끌어낸 직관 : 기존에 이론 및 분석적인 근거를 들어 generalization, robustness를 잘 향상시켰다고 주장하는 연구들이 많이 존재하지만, 본 논문에서는 이들의 제안/평가방법 자체가 generalization을 평가하는 데 부족하다고 주장합니다.
활용방안 및 향후 연구(개인적 의견) : 새로운 딥러닝 학습방법을 제시하는 연구는 실험 재현성(reproducibility) 및 일반화 가능성(generalizability)를 확보하기 위해 다양한 Hyperparameter에 대해 모델을 학습시키고, 이들의 평균 성능이 향상되었다는 결과를 통해 제안하는 딥러닝 학습방법의 효과를 주장합니다. 또한 최근에는 컴퓨팅 자원 환경이 좋아져서 다양한 데이터셋에 대해 제안 방법을 검증하는 경우도 많습니다. 이렇게 딥러닝이 빠르게 발전하고 있음에도 불구하고, 아직까지 어떤 데이터셋을 어떻게 학습해야 일반적 추론 성능이 높은 모델을 만들 수 있는지 추정하기 어렵습니다. 본 논문은 이에 대한 허점을 지적하여, 딥러닝 학습 방법에 대한 효과적인 데이터셋 혹은 검증 수단이 새로이 정의되어야 함을 강조하고 있습니다.
논문의 구체적인 방법론 : 다양한 데이터셋에 대해 다양한 Hyperparameter로 학습하고 OOD 성능과 ID 성능을 도표로 정리하였습니다. 그 결과 많은 연구들에서 pretraining seeds, Hyperparameter, task에 특화된 모델 구조 등 generalization을 평가하는 데 있어 방해요소가 있었던 것으로 확인됩니다.
Evaluating the Moral Beliefs Encoded in LLMs
기존 문제 : LLM은 단순히 통계적 프로그램이라고 하지만, 그래도 도덕적으로 선택해야하는 질문 등이 주어지면 LLM에 따라 반응이 다르거나, 불확실함을 어필하며 대답하는 것을 꺼려하는 경우가 있습니다. 이를테면 트롤리 문제 같은게 있습니다.
논문이 이끌어낸 직관 : LLM에는 약간의 랜덤성이 있다는 것을 활용하여 입력문이 일부 달라지고 의미가 변하지 않아도 대답이 바뀌는 경우, 혹은 LLM이 불확실하다며 답변을 거절하는 경우를 분석해보았습니다. 그 결과 gpt계열의 모델은 불확실하더라도 대답을 확실히 하는 경향을 보였습니다.
활용방안 및 향후 연구(개인적 의견) : model calibration을 우회적용하는 연구는 직접적인 calibration이 아니더라도 꽤 의미가 있는것 같습니다. 특히 RAILF를 구현하는 데 있어 유용한 principle을 찾는 등의 활용방안을 생각해볼 수 있습니다.
Leveraging sparse and shared feature activations for disentangled representation learning
기존 문제 : Representation을 사람이 만드는 것보다 ai에게 알아서 만들도록 하는 것이 대부분 훨씬 효율적인 방법이지만, 또한 대부분의 경우 representation의 feature들은 서로 Entangle되어 해석하기 복잡해지거나 다른 task에 대해 finetuning하기 어려워지는 경향을 보입니다. 그래서 disentangled representation을 만드는 것이 좋다고는 여겨지면서도… 실제로 그 어떤 task에 대해 finetuning 하더라도 향상된 성능을 띄는지?는 아직 미지의 영역에 해당합니다.
논문이 이끌어낸 직관 : 다양한 task에 대해 학습시킬 때, representation을 다양하게 쓰면 패널티를 주는 식으로 학습합니다. 이는 task에 대해 finetuning 시 representation의 전체가 아닌 필요한 부분만을 학습하게 하므로, 학습한 데이터 및 task 이외의 데이터에 대해서도 추론 능력을 향상시킵니다.
활용방안 및 향후 연구(개인적 의견) : 텍스트 데이터에 대한 실험이나 구현이 없어서 아쉽지만 후속연구를 기대해볼만한 내용이라 생각합니다. 다만 어느 레이어의 representation에 대해 regularize를 할지, attention이 제대로 흐를지 등 다양한 난제가 쌓여있는것 같습니다. 특히 neural collapse 현상*과 연결되는지 분석하는 연구도 유의미할 것으로 보입니다.
*. https://arxiv.org/abs/2305.13165 (neurips 2023)