Reports about Recent Advances in DL © 2024 by Seunghyun Ji is proprietary licensed.
목차
- 들어가기 전
- Rethinking motivations
- Interpretability for LLM
- Novel Architectures
- Applications / Best practice
- Others
본문
0. 들어가기 전
올해의 best novel paradigms : Simulation learning
LLM은 하나의 거대한 지식인같은 존재를 넘어, 주어진 규칙과 환경 속에서 특정 행동을 수행했을 때의 결과를 마치 실제 결과처럼 재현해낼 수 있습니다. 이는 다양한 형태로 표현되거나 생성되어 다른 모델이 가상환경 혹은 실세계의 원리를 학습 가능케 합니다.
올해 새로 보인 용어 : Asymptotic convergence
discretize 되었음에도 continuous space상 converge하는 theoretical phenomenon에 크게 오차가 나지 않는 성질을 의미합니다.
1. Novel Paradigms
✨LLM Evaluators Recognize and Favor Their Own Generations
“주어진 텍스트가 사람이 작성했는지 LLM이 작성했는지 구분하는 task에 대해 fine-tune 시켰을 때, 해당 LLM은 구분 능력이 향상됨에 따라 self-preference 성향 또한 강해집니다.“
트렌드 배경 : LLM agent 개념과 함께 LLM instance끼리 학습하는 패러다임 속 self-refinement, reward modeling 등의 방법이 제시되고 있습니다. 다만 LLM끼리 학습할 경우 mode collapse 등 여러 예상치 못한 오류가 나올 가능성이 있습니다. 이를 통제하기 위해 현 시점에서는 LLM의 interpret-ability 연구가 제일 크게 조명을 받고 있습니다.
기존 문제 : 주어진 corpus가 사람이 쓴 것인지 LLM이 쓴 것인지 갈수록 판별하기가 어려워지고 있습니다. 특히 학습 데이터에 벤치마크 데이터가 포함돼버리거나 특수한 성향의 LLM인 경우 성능 평가에 있어 어떤 영향이 갈지 예측하기 어려운데, 이것이 LLM은 스스로가 생성해낸 corpus가 어떤 corpus인지 아는 능력, 즉 self-recognition 능력이 약해서 발생하는 문제라고 주장된 바 있습니다. 만약 이것이 옳다면 LLM이 스스로가 생성한 corpus에 대해 더 긍정적으로 평가하는 self-preference현상도 설명할 수 있습니다.
-
Highlight Figure
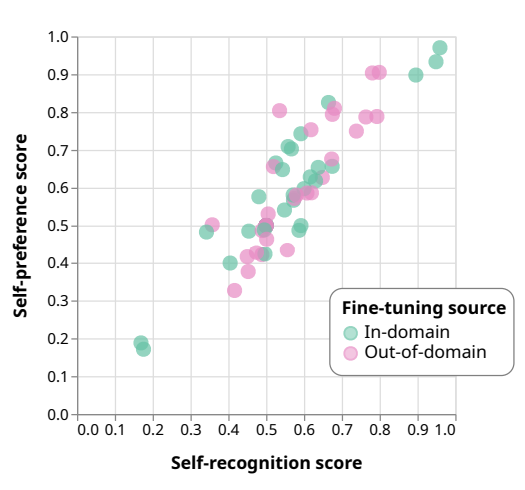
상세 실험 방법 : 주어진 텍스트가 자신(평가할 LLM) 이 작성한 것인지 아닌지 구별하는 ‘self-recognition task’를 학습시킵니다. 학습된 LLM은 이후 자기가 작성했던(학습 이전의) 텍스트와 사람의 텍스트 중 어떤 텍스트가 주어진 목표를 더 충족하는지 선택합니다. 이 때 사람이 선택한 결과보다 자신이 작성했던 쪽을 더 좋다고 평가한다면, self-preference 현상이 발생했다고 정의합니다.
실험 결과 : LLM들은 self-recognition을 학습함에 따라 self-preference 성향을 강하게 지닙니다. 이는 매우 강한 correlation에 해당합니다. 데이터 도메인, 품질, counterfactual (일부러 레이블을 반대로 놓는다던지) 혹은 LLM의 성능과 관련 없이 consistent하게 유지되는 양상입니다.
활용방안 및 향후 연구(개인적 의견) : Jailbroken 논문과 비슷하게 가설 자체는 나이브하지만 매우 중요한 이슈를 시사합니다. 특히 일반적인 딥러닝 모델은 세부 task에 대해 학습할수록 본래 지니고 있던 다른 지식을 잊는 현상(catastrophic forgetting) 이 존재하는데, 그럼에도 불구하고 self-preference 현상이 존재한다는 것은 (1) self-recognition task에서 자신이 작성한 텍스트로 도메인이 좁혀짐 혹은 (2) self-preference 성향이 self-recognition과 직접적으로 연결된다고 볼 수 있습니다. 실험 결과를 살짝 확대해석 해보면 다음과 같이 생각해볼 수도 있습니다.
- LLM은 사람보다 자신이 작성한 corpus가 더 informative하다고 여길 수 있다.
- LLM은 사람의 response/evaluation이 정답이 아니라고 가정할 수 있다.
- 만약 LLM이 RLHF와 같은 feedback based learning을 수행할 때, o1 계열과 같은 internal inference 모델의 경우 사람이 통제할 수 없는 중간 추론 과정이 발생할 수 있다.
Policy Learning from Tutorial Books via Understanding, Rehearsing and Introspect
“Tutorial book을 통해 다양한 시나리오 및 문제 해결 과정을 생성하고, 이를 통해 LLM을 학습한다는 Simulation-based RL은 모델 학습 과정에 혁신을 불러올 수 있습니다.”
트렌드 배경 : 여러 머신러닝 모델들의 추론결과를 활용하겠다는 bagging 방법의 경우, 각 모델들이 서로 이질적일수록 효율이 높아진다는 연구결과가 있습니다. 따라서 LLM끼리 학습시킬 때에도 서로 다른 특성을 부여하는 방법을 생각해볼 수 있습니다. 대표적으로 impersonation, verifier 등이 성공적인 방법론으로 떠오른 바 있습니다.
기존 문제 : LLM이 가진 ‘특성’은 ‘추상적인 특성’에 머무를 수밖에 없습니다. 즉, 실제로 내부 가중치는 크게 다르지 않음에도 출력 결과만 서로 매우 달라보일 수도 있습니다. 이는 마지막 layer가 추론 결과에 결정적인 역할을 한다는 연구 등 여러 연구 결과들을 근거로 합니다. 그렇다고 해서 정말로 가중치 레벨로 넘어가면 LLM의 가중치를 분석해야 한다는 (불가능에 가까운) 결론으로 수렴합니다.
최신 트렌드 : direct representation learning이라 해서, 데이터가 아닌 RNN의 가중치를 입력받아 학습하겠다는 연구가 조금씩 나오고 있었습니다. 다만 차원이 너무 크다는 점 등 한계점이 너무 많기 때문에 마이너한 트렌드에 그쳤지만, 올해 “입력받은 RNN 가중치가 어떤 출력을 해내는지 예측하는 emulator를 설정하고, 실제 RNN 모델의 출력 결과와 비교해 emulator를 대신 학습하겠다”는 연구를 바탕으로 일종의 simulation 패러다임이 등장하게 되었습니다. 이는 (1) 데이터 의존성을 크게 낮추며 (2) 자연어 입출력과 같은 추상적인 데이터가 아니라 가중치 레벨로 접근할 수 있다는 두 강점을 가지므로, 잘만 일반화하면 딥러닝 필드에 또 다른 혁신을 가져올 수도 있습니다.
-
Highlight Figure
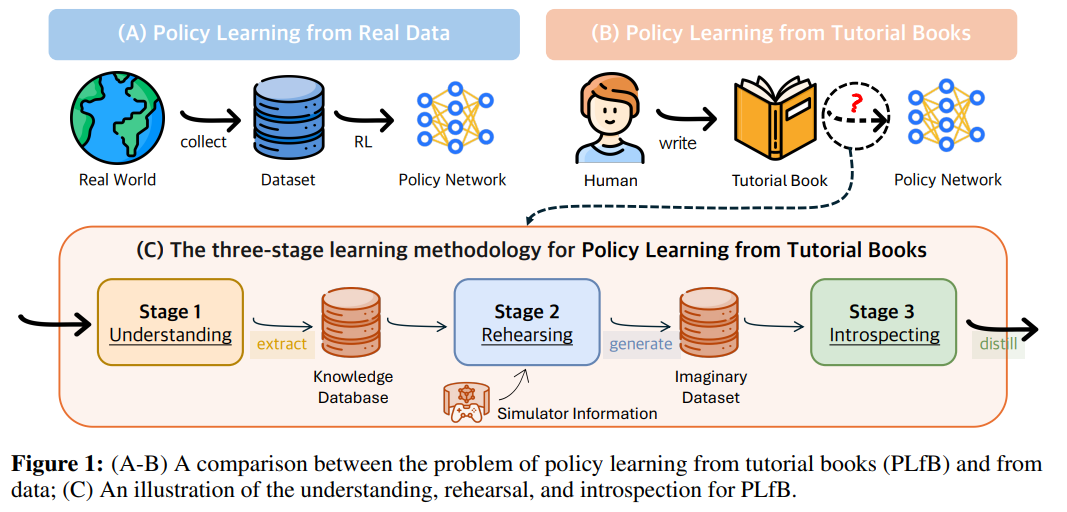
제안 방법 및 결과 : tutorial book의 내용을 그대로 학습하는 대신 이를 knowledge set으로 가정하고, drawn knowledge나 retrieved knowledge를 기반으로 다양한 state, action, policy (in a certain state) 등을 생성하고 학습하기를 반복한다면, knowledge set으로부터 다양한 시나리오 데이터를 생성할 수 있습니다. 시나리오 데이터란, 주어진 상황에서 적절한 knowledge를 제시해주는 상황, 규칙, 지식 등을 통합한 discrete한 정보들을 의미하며, 시나리오 데이터를 바탕으로 policy model을 학습합니다. 실험 결과 기존 RAG 기반 모델보다 필요 knowledge set을 더 정확하고 빠르게 찾을 뿐만 아니라, real data에 가깝거나 가깝지 않은 simulation data distribution도 잘 형성하는 결과를 보입니다.
활용방안 및 향후 연구(개인적 의견) : 드디어 LLM에도 simulation-based learning 패러다임이 나와 구현된것 같습니다. 특히 tutorial book을 knowledge set으로 일반화했다는 점에서 굉장히 강력하게 generalize 할 수 있는 연구이고, 실제 상황에서 textbook에 따르면 어떻게 행동해야 하는지에 대한 다양한 예시를 row 구분이 있는 데이터셋으로 표현했다는 것이 거의 혁신에 가까운 발상입니다. 다만 앞에서 언급한 LLM의 불안한? 가능성(사람이 통제하기 어려운 중간 추론과정이 생성될 수 있다) 도 고려해보면 simulation 데이터를 좀 더 강하게 통제/향상시키는 방법이 필요할것 같습니다.
DenoiseRep : Denoising model for representation learning
“given data의 noise를 representation에서 특정하려는 시도 중 하나입니다.”
트렌드 배경 : representation learning은 갈수록 중요성이 강조되고 있습니다. naive하게도 접근할 수 있고 theoretical하게도 접근할 수 있습니다. 해석 방법도 너무 다양하고 objective도 transferability, interpretability, sparsity 등 다양하게 설정할 수 있어서, evaluation 방법론조차도 계속해서 다른 연구들이 나오고 있습니다.
기존 문제 : 딥러닝은 결국 data distribution을 이해하는 것이 최종적 목표인데, 그것보단 representation distribution을 추정하는 것이 문제 자체의 난이도를 낮추는 방향입니다. 물론, representation distribution은 정해진 규칙도 실제 데이터와 연결짓기도 어려우므로 가정의 영역에만 머물거나, 아예 표준정규분포로 설정하는 편입니다.
빌드업 : Person Re-Identification이라는 task로 한정지어보면, noisy, clear 등 다양한 환경에서 사람 얼굴의 feature를 얻을 수 있고, ‘clear feature’를 정의할 수 있습니다. 이 말은 noisy feature도 정의할 수 있다는 것이며, 아주 손쉽게 diffusion process를 떠올릴 수 있습니다.
-
Highlight Figure
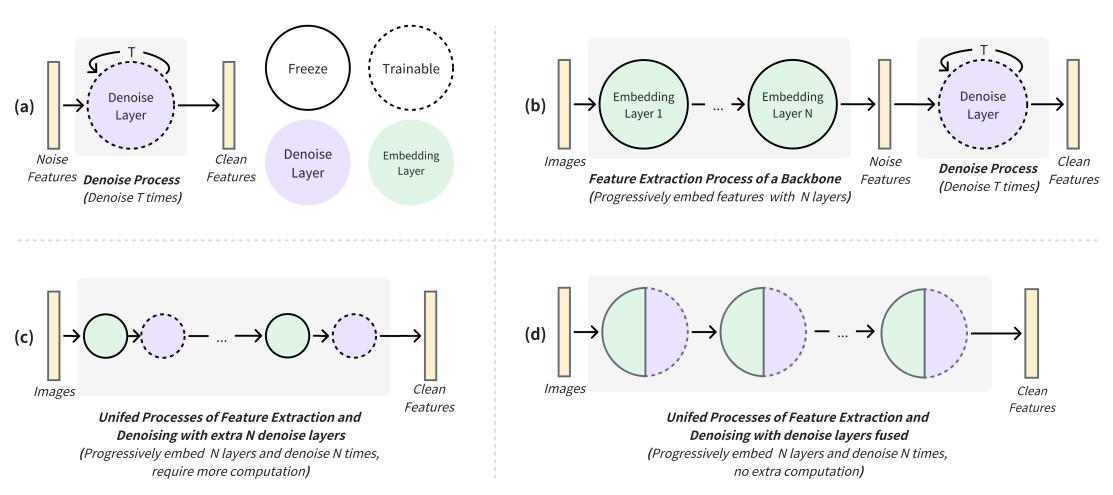
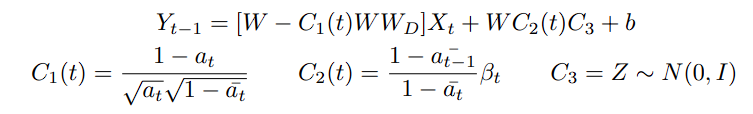
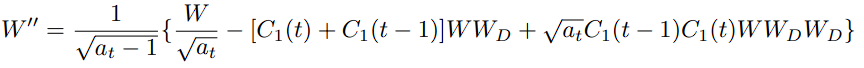
제안 방법 : diffusion process와 forward module을 결합합니다. 기존의 module을 Y=(W_2+W_1)x+b 라고 한다면, W_1에 diffusion process weight를 적용하고 W_2를 freeze 함으로써 손쉽게 W_1를 학습 가능하며, W_1과 W_2는 기존과 동일한 사이즈의 W로 re-parameterize 가능하니 additional inference cost가 들지 않는 방법이자 transformer를 사용하는 모든 모델에 적용할 수 있는 구조입니다.
활용방안 및 향후 연구(개인적 의견) : noisy data는 의외로 딥러닝 모델이 다루기 어려워하는 영역입니다. 어떤게 noisy인지 아닌지 사람이 알려주지 않으면 noise-robustness와 general performance 사이의 tradeoff가 생기기 때문에, ‘noisy data만이 만들어내는 어떤 representation column’ 을 설정하자는 트렌드가 생기게 됩니다. 본 논문에서는 noisy representation를 정의할 수 있는 문제설정을 가져왔으므로 직접적으로 diffusion을 적용할 경우의 성능 향상 정도를 확인할 수 있으며, representation distribution도 정의할 수 있다는 것입니다. 여태까지 generation 문제로 한정하여 가상의 representation distribution에서 draw된 데이터로 샘플링한다는 개념은 있었지만, 이걸 반대로 적용시키면 noisy image에 대한 representation까지도 명확하게 정의할 수 있습니다.
하지만 아쉬운 점은 clean feature가 general하게 정의 가능한지, interpolation 능력이 있는지, 분석 연구만 10개 20개 나올 수 있을것 같은데 이에 대해 다루지 않았다는 점 등입니다.
Return of Unconditional Generation: A Self-supervised Representation Generation Method
트렌드 배경 : Unconditional generation은 말 그대로 실세계의 데이터 분포를 예측해야 하는 어려운 문제이면서도, training objective로 채택할만한 매력적인 문제입니다. 이를테면 Autoregressive language modeling같은 문제도 “해결하기에는 어려운 문제”이지만, 이를 training objective로 채용한 모델은 기존 방법 대비 실세계의 언어를 매우 잘 이해하는 모델로써 사용될 수 있습니다. 따라서 같은 논리로 Unconditional generation을 잘 수행하는 모델은 conditional generation 또한 잘 수행하도록 보정될 수 있기 때문에 중요한 문제에도 해당됩니다.
기존 문제 : 이미지에 대한 Unconditional generation은 당연히 language modeling보다 훨씬 어렵습니다. 전제 가능한 support가 너무 방대하면서도 uncertain합니다. 그래서 실질적으로 diffusion model은 pre-training procedure을 적당하게만 진행하고 input space, 이를테면 text prompt를 condition으로 입력받아 학습하게 됩니다. 그러면 사실상 text의 distribution에 의지하게 되므로, text prompt가 조금이라도 학습한 형태와 달라지는 경우, 사람이 보기에 그럴듯한 이미지를 만드는 능력, 즉 interpolation, extrapolation 모두 취약해지게 됩니다. 이것이 비단 이미지 생성 모델 뿐만 아니라 Visual language model의 일반화 능력이 매우 낮은 이유입니다.
빌드업 : Unconditional generation을 수행할 때 generated representation을 condition으로 준다면 학습 난이도가 조금이나마 낮아질 것입니다. 뿐만 아니라 representation generation이란 것은 representation distribution을 이해한다는 것인데, 이는 그 어떤 형태의 데이터라도 distribution을 이해할 수 있다는 말과 같습니다.
-
Highlight Figure
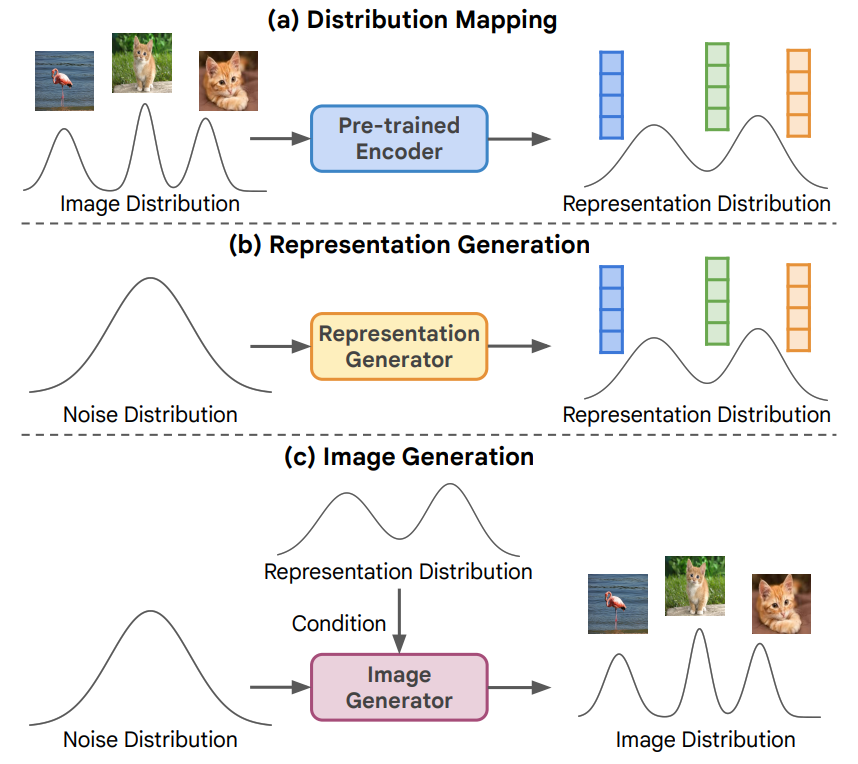
논문이 이끌어낸 직관 : 특정 encoder가 만든 data representation이 주어졌을 때, 이에 대해 diffusion process를 학습하면 representation distribution을 학습하는 것으로 볼 수 있습니다. 그러면 위에서 언급했듯 diffusion model을 pre-training할 때 ‘사람이 보기에 그럴듯한 이미지’를 만드는 능력을 더 향상시킨 다음 conditional (혹은 downstream task)로 넘겨줄 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 일단 논문에서 어떻게 문제 해결 과정을 전환했는지는 이해했습니다만, hypothesis에 대한 theoretical / analytical 근거가 거의 없어서 아쉽습니다. 물론 본 논문은 새로운 패러다임을 제시했으니 그것만으로 큰 가치가 있지만, 조금 더 intuitive한 설명을 해줬으면 합니다. data와 representation을 직결시키는 관점에서 탈피했다면, neural discrete representation learning 논문처럼 다양한 application을 보여준다거나, unconditional generation에 어떻게 작용하는지 좀 더 보충설명이 있었으면 합니다.
RL-GPT: Integrating Reinforcement Learning and Code-as-policy
“LLM은 강화학습을 하는 데 있어, 사람과 모델을 이어주는 인터페이스가 될 수 있습니다.”
트렌드 배경 : LLM은 자연어를 통해 입출력을 받으므로 사람이 생각(latent variable) 한 내용은 관측할 수 없어 결정적인 gap이 있다는 것이 문제입니다.
기존 문제 : RLHF, RLAIF의 결정적인 문제는 출력 결과에 대해서만 평가한다는 것입니다. 그래서 결과에 대한 피드백이 가중치에 어떻게 전달되어 추론 양상을 어떻게 바꾸는지 정확하고 밀도있게 평가하기 매우 어렵습니다. 이는 추론 과정을 직접 텍스트로 표현하더라도 예외가 아닌데, 추론 과정을 텍스트로 표현한 것은 모델 내부에서 해당 추론 과정이 존재한다는 것과는 다른 얘기이기 때문입니다.
아이디어 : LLM이 직접 모든 작업을 수행하는게 아니라, **RL interface (실제 3.1절 소제목)**로서 기능하게 만듭니다. LLM은 자연어 등을 임베딩 형태로 번역하고, 핵심 모델에게 전달하고 피드백을 줌으로써 차세대 딥러닝 라이브러리와 같은 역할을 수행합니다.
-
Highlight Figure
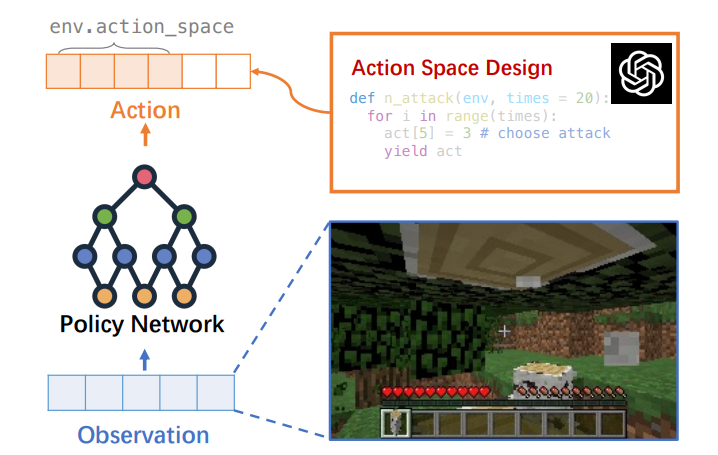
제안 방법 : Policy network의 Action을 억지로 LLM의 기준에 끼워맞추지 않고 반대로 LLM이 이를 자연어 혹은 코드로 번역해냅니다. 따라서 복잡한 작업 수행능력을 LLM의 일반적 추론 능력에 의존하지 않고 별도의 전용 모델로 대신할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 제안 방법에 화려한 테크닉이나 참신한 발상이 담긴 것은 아니지만, 아주 중요한 패러다임을 제시했다는 데 의의가 있는것 같습니다. 만약 앞으로 policy network가 자연어나 코드 형태가 아닌 representation 등으로도 학습할 수 있게 된다면, LLM agent들보다 훨씬 정확하고 신뢰성있는 agent들을 LLM 대비 매우 적은 리소스로 구현할 수 있을 것입니다.
2. Generalizable Interpretability
✨Unlocking the Boundaries of Thought: A Reasoning Granularity Framework to Quantify and Optimize Chain-of-Thought
“주어진 문제에 필요한 단계적 사고 과정이 많을수록 LLM의 정확도가 낮아진다는 점을 역이용하여, 필요 사고 과정의 개수와 task에 대한 정확도를 normalize하여 새로운 평가 기준을 제시했습니다.”
트렌드 배경 : CoT가 사람의 추론 방식과 유사하다는 특징도 있고, 통계적 혹은 query-key 관계 등으로 CoT의 효용에 대한 해석도 다양하게 제시된 바 있습니다. 그러면서 LLM, sLLM이 엄청나게 난립하고 그에 따른 다양한 prompting strategy 파생형까지 겹치니 도대체 LLM을 어떻게 평가해야 하는지 헷갈리는 상황입니다. 그래서 이에 대한 평가 기준이 지속적으로 요구되고 제시되고 있습니다.
문제 분석 : 주어진 작업 t를 모델 m이 풀 때, t를 풀기 위한 step이 많으면 많아질수록 m이 풀기 어려워집니다. 본 논문에서는 이것이 다양한 작업 t들간에 공통적으로 나타나는 현상이라 가정했고, 분석 결과 가정이 어느정도 들어맞는 것으로 보았습니다. 따라서 task t의 difficulty d를 일단 t를 푸는 데 필요한 step 수로 정의했습니다.
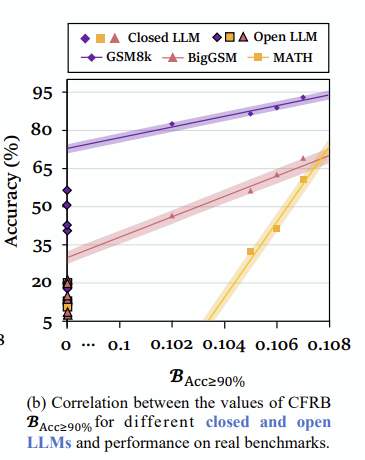
제안 평가 방법 : 특정 task t의 difficulty는 사실상 task t의 정보 안에 포함된 것인데, 따로 formulize 해버리면 정량적인 성능 측정이 훨씬 어려워집니다. 따라서 task t에 대한 모델 m의 정확도를 측정하고, 해당 정확도를 일정 수치 이상으로 보장하는 d의 최대값을 B( t | m )으로 표기합니다. 예를 들어 B_acc>90%는, 주어진 t를 90%이상의 정확도로 풀어낼 수 있는 d의 최대값입니다. 따라서 t의 difficulty는 12 정도로 생각해볼 수 있고, difficulty가 12인 t ∈ T 들에 대해 90% 이상 정확도를 가지게 하는 B( T | m )>90%는, LLM이 어려워하는 수학 관련 작업 t들로 구성했을 때 0.1~0.2정도 됩니다.
-
Highlight Figure
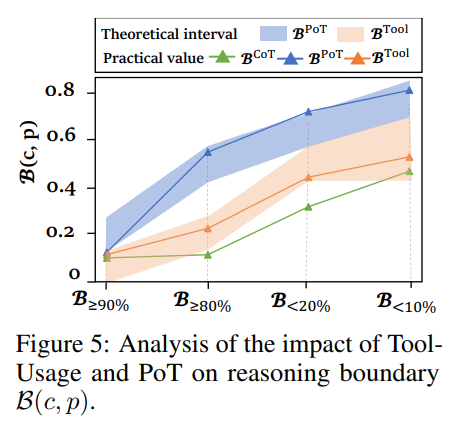
제안 최적화 방법 : LLM에게 수치 계산 tool이 주어졌다면, 복잡한 수학 문제에 담긴 일부 step은 아예 skip하는 효과를 가집니다. 때문에 본 제안 평가방법과도 강한 비례관계를 가집니다. 그 외에도 program of thought, 다양한 모델, 다양한 task 등에도 일관적인 상관관계를 관측하여, LLM을 task-agnostic하게 평가할 수 있는 방법으로 사료됩니다. (다만 task domain에는 dependent합니다)
활용방안 및 향후 연구(개인적 의견) : 어떤 문제를 풀기 위한 사고과정 step이 많으면 많을수록 사람에게도 LLM에게도 어려워집니다. 하지만 task에 따라 step 하나만 필요한 경우도 어려운 task가 될 수 있고, 아무 의미 없는 step이 많다면 step이 많아도 쉬운 task가 될 수 있습니다. 때문에 다양한 task에 대한 평균 성능을 보는 것이 기존의 벤치마크 시스템이었지만, task 안에서도 쉬운 문제와 어려운 문제, step을 적게/많이 요구하는 문제가 혼재돼 있으니 학습보다 평가가 더 어려워지는 마당이었는데, 이 논문은 그런 tradeoff같은 존재를 아예 바꿔놓은 논문이라 할 수 있겠습니다.
Human Expertise in Algorithmic Prediction
“주어진 문제에 조합가능한 feature subset이 매우 많을 경우, 기존 모델들이 사용하지 않았던 feature subset을 주는것 만으로 모델 set (혹은 pool) 의 성능을 향상시킬 수 있습니다.”
트렌드 배경 : LLM이 발전하여 거의 사람과 유사한 추론 능력을 갖게 되자, 그에 따라 ‘사람도 하기 힘들어하는’ 문제에 도전시키기 시작했습니다. 전세계의 석박들에게 데이터 레이블링을 부탁하거나, o1의 경우에는 문제 풀이 과정까지 레이블링 시킨게 아닐까 의심되고 있습니다. 아무튼 사람에게도 어렵다면 근본적으로 ‘레이블러간에도 레이블이 다를 수 있다’ 는 문제가 있어 데이터셋의 문제로 회귀되는게 아닌가 하는 의견도 있습니다.
기존 문제 : 만약 사람의 답변이나 레이블을 신용할 수 없다면, 무엇을 기준으로 학습해야 하는지에 대한 의문이 남습니다. 특히 실세계에 해당하는 특징, 즉 feature들이 서로 entangle 되어있고 causation을 추측해야 하는 경우, 모델에게 어떤 피드백을 줘야 하는지 아직 확실한 매커니즘은 정립되지 않았습니다. 다만 correlation만을 사용한다면 Entropy-based, Active learning 등 여러 solution은 많이 나와 있습니다.
새로운 문제 설정 및 제안 방법 : expert(human)는 주어진 문제에 대해 기존 모델들이 다룬 feature 조합 이외의 feature들로 해당 정보를 갖고 주어진 문제를 해결할 수도 있습니다. 모델 집합 F (where an element f is a model) 를 가정한다면, \any f가 출력해내지 못한 결과가 모델들이 사용하지 않은 새로운 feature set으로부터 만들어졌을 때, 사람이 해당 feature 조합을 넘겨주고, 모델은 새로운 feature를 적용하여 개선시킵니다.
-
Highlight Figure
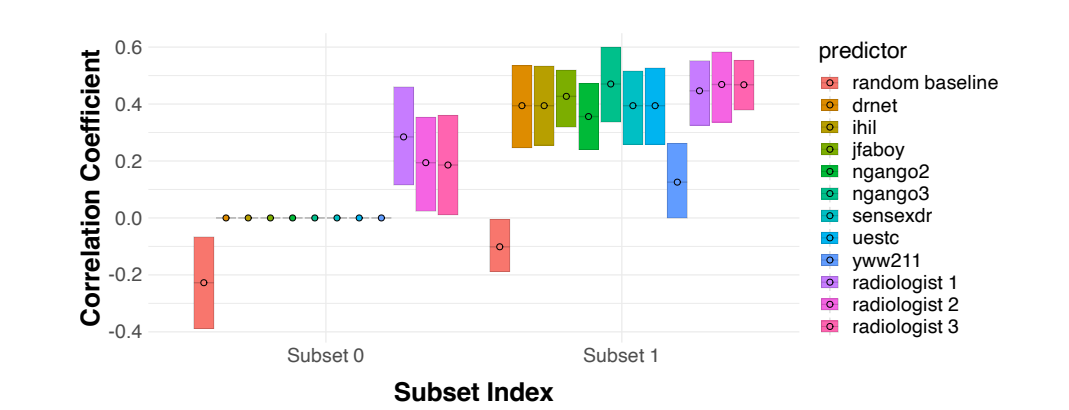
실험결과 : 주어진 문제 데이터셋에 대해 모델들은 평균적으로 사람보다 더 높은 성능을 나타내기도 하지만, 조합가능한 feature subset이 매우 많고 이들의 발생빈도수가 long, heavy tail 형태의 분포를 가진 경우 비선형적 모델링이 필요할 수 있기 때문에, 사람은 모델에 비해 훨씬 정확한 추론 능력을 가집니다. 따라서 사람이 모델에게 피드백을 줄 때, 사람이 사용했던 feature subset을 주는것 만으로 모델 set F의 성능을 향상시킬 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 의외로 사람-AI 협업 방법론은 의미있는 진전이 많지 않습니다. 사람이 애초에 AI를 꺼린다는 성향도 있지만, 기본적으로 사람이 ‘정답’ 이고 모델이 ‘멍청한 프로그램’ 이라고 가정되기 때문이기도 합니다. 하지만 사람이 모델의 추론을 선택적으로 받아들이는 것보다, 사람의 추론 근거를 모델에게 피드백으로 제공하는 것이 사람과 AI 모두 어떤 predictor f로서 정확도가 높아질 수 있는 방향이 될 수 있습니다. 특히 본 연구는 이전 패러다임인 ‘모델의 취약부분 피드백’ 이 아닌 ‘모델이 고려하지 못한 feature 피드백’ 이라는 점에서 좀 더 일반화된 접근이며, 사람이 피드백을 전달함에 있어 더 유용한 방법이라고 볼 수 있습니다.
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks
“LLM 내부에 한 종류의 문제를 푸는 여러 알고리즘이 공존할 수 있으며, ICL few shot 개수에 따라 보다 일반화된 알고리즘을 선택하는 경향이 있습니다.”
문제 배경 : LLM은 다재다능하면서 주어진 문제에 대해 어떻게 추론하여 일반화하는지 그 실체를 알기 어렵습니다. 특히 training loss가 매우 작아진 시점에서도 학습을 이어나가면 갑자기 더 일반화된 알고리즘으로 전환했다가 다시 되돌아가버리는 현상이 있는데, 이를 grokking이라 하고, 이에 관련된 연구들을 analyses on grok로 후술했습니다. 기존 연구(Zhong et al., 2023) 에서는 모델이 모듈러 연산과 같은 단순한 문제에 대해서도 모델 크기, 어텐션 활용가능 정도 등에 따라 다양한 방법으로 해석/풀이하는 모습을 볼 수 있었습니다.
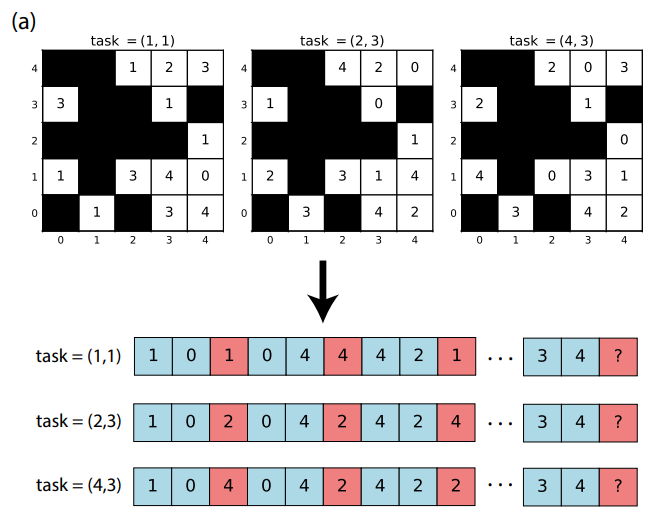
실험 세팅 : 모듈러 연산 문제를 Autoregressive + ICL 입력 가능한 데이터셋으로 전환했습니다. 이는 LLM이 추론하는 방법과 완전히 동일하다는 면에서 기존 toy model로만 시도된 analyses on grok 연구들보다 진전된 시도입니다. 또한 문제 데이터셋을 (ax + by) mod p = z 에서, (x, y)는 입력값, (a, b)는 task vector로 칭하여, 결과값 z를 관측하여 (a, b)를 학습해야 하는 문제로 구성합니다. 또한 p에 대입되는 숫자에 따라 다양하게 데이터셋을 구성할 수 있으므로, (a, b)를 학습하는 문제 데이터셋을 p^2개만큼 만들어 학습/테스트 비율을 알파로 지정했습니다.
가정 : 저자들은 모델이 모듈러 연산을 이해하는 두 알고리즘을 제시합니다.
- Ratio matching : 추론해야 하는 문제에 대해 ICL shot에서 cx, cy가 있는지 참고하여 p를 추론합니다. 이 때 c는 정수 형태의 계수로, (ax + by) mod p = (acx + bcy) mod p 라는 원리임을 알 수 있습니다.
- Modular regression : 주어진 모든 shot에 대해 만족하는 task feature coefficient를 찾습니다. 계수를 찾는다는 점에서 regression 문제라고도 할 수 있습니다.
만약 task vector의 종류가 애매할 경우 (256개) train phase 도중 Modular regression을 사용하다가, 갑자기 Ratio matching을 해버리는 현상이 재현된다면, 기존 LLM에서 발견되었던 grok 현상으로 이를 해석할 수 있고, 역으로 본 논문에서 발견한 새로운 현상이 ‘LLM에서 발생하는 일반적 특성’ 인 것으로 해석할 수도 있습니다.
-
Highlight Figure
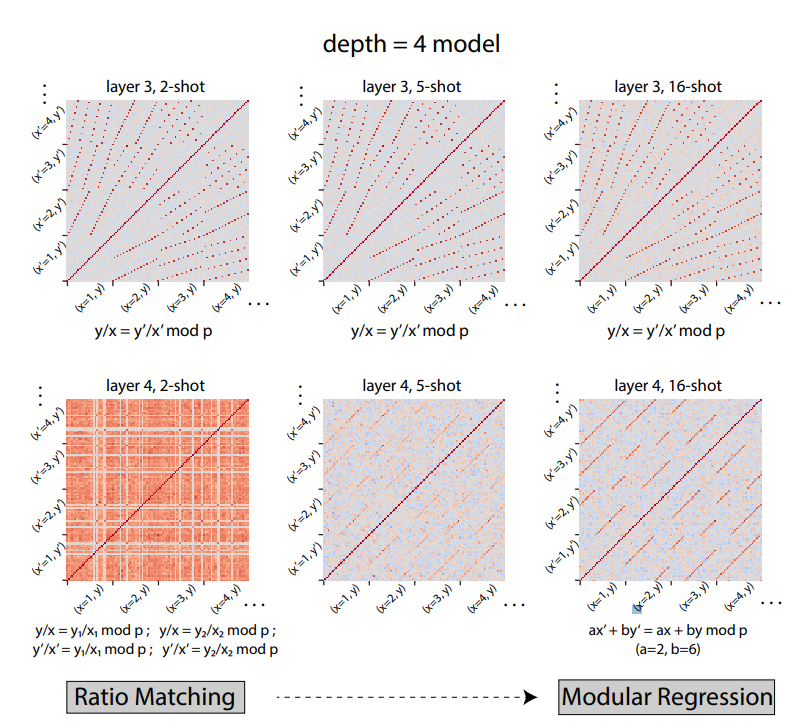
최종 가정 및 실험결과 : 가정에서 언급한 grok 현상이 재현되는 양상을 볼 수 있었고, 본 논문에서 새로이 발견한 현상으로는 ****transformer model의 (1) depth가 클수록, (2) 학습한 task vector의 종류가 다양할수록(≥512개), 또 (3) few-shot 개수가 클 수록 일반적인 모듈러 연산알고리즘을 택하는 경향을 볼 수 있었습니다. 이후 상세 실험에서 - (1) Attention module은 train data가 다양할수록 더 일반화된 representation을, (2) MLP module은 few-shot이 커질수록 더 일반화된 알고리즘을 - 사용하는 경향이 있고, 역으로 few-shot이 작으면 같은 모델이라도 덜 일반화된 알고리즘으로 문제를 풀어버리는 현상이 있습니다. 즉, 모델 내부에 여러 알고리즘이 공존할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 기존 analyses on grok 연구를 LLM의 ICL inference로 더 발전시키기도 했고, 심지어 grok이 학습 중간에 잠시 일어난다는 결과도 재현하여 신뢰성있는 연구임을 잘 보여줌과 동시에, 같은 모델임에도 알고리즘 전환이 일어날 수 있다는 결과도 보여줘서 그간 emergent 등 여러 설명하기 어려운 현상들을 잘 분석하고 설명한 논문이라 생각합니다.
Guiding a Diffusion Model with a Bad Version of Itself
트렌드 배경 : 생성 모델 p(x)의 학습을 위해 loss를 단순 스칼라로 리턴하는 score-based diffusion model이 등장하면서, diffusion 모델이 크게 주목받기 시작했습니다. 특히 기존보다 더 intuitive한 접근이 많아졌는데, condition으로부터 guidance를 유도하거나, step 0과 step T 사이의 brownian bridge같은 범위 내부로 모델 파라미터가 포함되게끔 하는 기법(Flow matching) 등이 등장했습니다. 특히 condition에 부합하는 결과물을 만들어 낼 수 있다면 text prompt 형태의 condition을 제시하는 것도 가능한데, 이 때 generated 결과물이 condition을 따르도록 하는 것을 alignment라고 부릅니다. 이걸 다양하게 활용해볼 수 있는데,
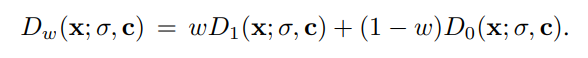
flow matching, 혹은 conditional diffusion process의 경우 위와 같이 condition의 세기를 조절할 수 있는 모델 두개를 통해 diffusion modeling을 수행하는데, 이 때 w를 1 이상으로 설정하게 되면 특정 모델이 guidance로 작용하는 효과가 생기게 됩니다. 이것이 condition 혹은 classifier guidance에 해당합니다.
기존 문제:
classifier-free guidance는
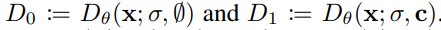
와 같이 P_data를 따르는 모델을 설정하여, 더 그럴듯하고 align된 결과를 만들어냅니다.
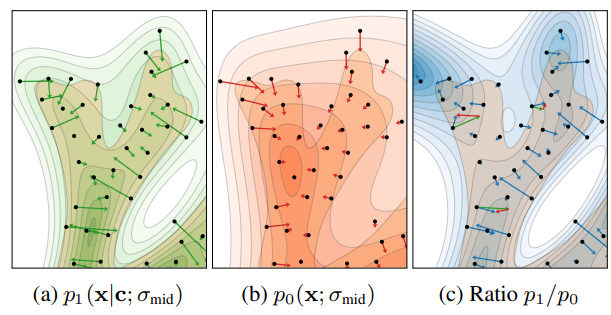
저자들은 이전에 GAN에서 자주 발생하는 mode collapse에 빗대 conditional diffusion process의 문제를 설명합니다. conditional (a)의 경우 지엽적인 부분에 대해 norm이 큰 gradient를 가지는 반면, unconditional diffusion process (b)는 그냥 noise로 fit해버리면 되니 mode collapse 하더라도 목표를 달성합니다. 이 둘을 위에서 언급한 w와 같은 coefficient로 밸런싱되지 않는 경우가 (c)와 같은 예시입니다.
사실 모델 (a)에 많은 데이터와 많은 파라미터를 부여하면 conditional generation을 충분히 수행할 수 있습니다. 문제는 unconditional data distribution이 효율이 너무 좋기도 하고, bayesian 등 기존의 탄탄한 이론들이 워낙 다양한 증거를 제시해주며, 다양한 condition에 대해 일일이 fine-tune 할 수는 없다는 문제도 있습니다. 결국은 unconditional generation을 어떻게든 활용해야 할 것으로 보입니다.
-
Highlight Figure
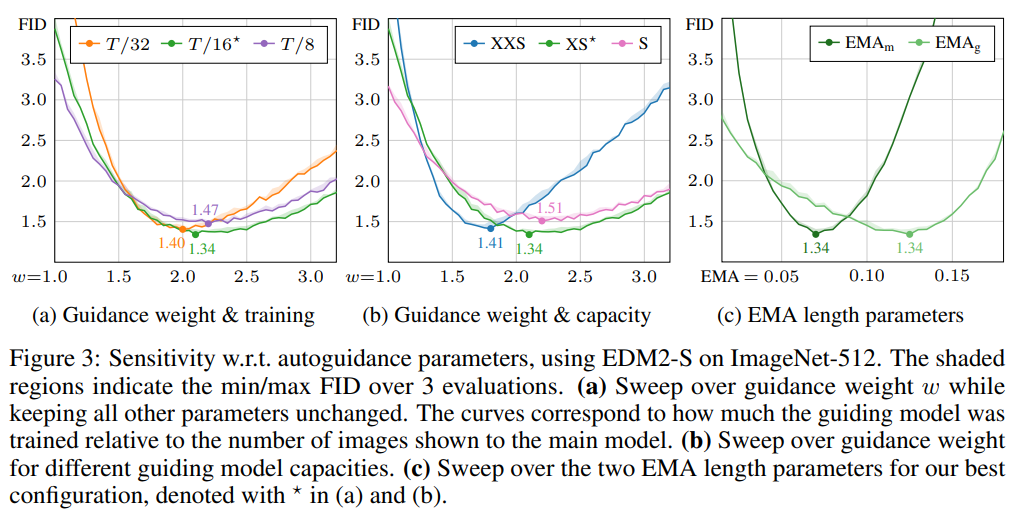
제안 방법: p_0이 unconditional, p_1이 conditional 모델일 때,
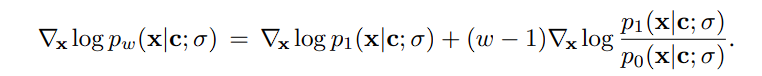
기존의 unconditional과 conditional model 간의 ratio에 (w-1)이라는 가중치를 부여합니다. w가 커질수록 unconditional guidance model에 낮은 가중치를 부여하여 ratio의 균형을 맞춥니다. 놀랍게도 모델 사이즈나 학습량 등의 hyperparameter에 큰 영향 없이 w=1.5 부근에서 optimize되는 현상을 보입니다. 즉, unconditional model의 guidance는 활용하되 그 영향력을 적절하게만 조절하면 좋은 성능을 달성할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : Classifier-free guidance는 unconditional generation에 해당하여 P_data 같은 distribution을 연상케 하고, 빌드업 및 제안 방법은 traditional bayesian method인 P_data와 P_condition의 보정을 연상케 합니다. 어떻게 보면 따분하지만 어떻게 보면 직관적 사고를 수식으로 잘 연결한 사례이므로 괜찮은 방법이라고 생각됩니다.
한편 Electra같은 모델이 weaker generator compared to discriminator 로 최적의 성능을 달성한 것처럼, 대충이나마 윤곽을 그려주는 보조장치, 즉 Weaker auxiliary-guidance라는 존재 자체가 머신 러닝에 있어 generalize 가능한 inductive bias일수도 있겠습니다.
Solving Intricate Problems with Human-like Decomposition and Rethinking
트렌드 배경 : o1 model이 ‘inference time cost’ 를 이슈화시킨 이유는 LLM이 스스로 복잡한 문제들을 분해하고 점검하는 과정에서 다양한 보조 모델을 사용할 수 있고 attack으로부터의 리스크를 크게 낮췄기 때문입니다. 때문에 o1만의 self-inference 하는 과정을 재현하려는 연구들이 최신(11월 26일 작성일자 기준 최신) 트렌드 연구에 해당됩니다.
-
Highlight Figure
제안 방법 : 주어진 문제를 여러 문제로 분해하고, 추론해낸 내용에 대해 점검하며 정답에 이르기까지 이를 반복합니다.
활용방안 및 향후 연구(개인적 의견) : LLM 전반에 큰 관심이 있다면 o1 모델 관련 여러 아카이브 논문들에서 한번쯤은 봤을 방법론입니다. 다만 중요한 것은 본 방법은 추론 중 일어날 수 있는 분해, 분석, 재고 등의 다양한 과정을 전부 분리했는데, 오히려 이것들을 하나의 과정으로 일반화하는 것이 더 좋은 방법일 수도 있고, Deepseek R1 논문에서 주장한 대로 MCTS와 같이 사람의 inductive bias보다는 최대한 특정 구조에 얽매이지 않는 추론 과정이 더 optimal한 결과를 낼 수 있습니다.
3. Novel Architectures
✨Flipped Classroom: Aligning Teacher Attention with Student in Generalized Category Discovery
기존 문제 : representation learning에서는 아직 분석하고 개선할 여지가 많습니다. 특히 zero-shot class 데이터에 대해 학습한 feature들로 표현하는 것은 transferability야 그렇다 치고 feature들이 잘 표현됐는지 분석하기조차 쉽지 않습니다. 대표적으로 Generalized category discovery task는 zero-shot data representation에 대해 cluster하여 해당 cluster가 zero-shot class를 기준으로 형성되었는지 확인하는 task인데, representation 성능을 확인하기에 꽤 좋은 방법입니다.
문제 설정 : 본문에서는 teacher-student 설정을 데이터에 적용합니다. weakly augmented data로 학습할 때는 ‘teacher’, strong augmented data로 학습할 때는 ‘student’로 놓습니다. 좀 더 추상화하자면, teacher는 좀 더 정돈된 feature들을 학습할 것이라 가정할 수 있습니다. 이 때 저자들은 teacher-student setting의 난점을 다음 두가지로 정리합니다.
- teacher와 student가 형성하는 new class input에 대한 representation gap
- teacher data와 student data에 대한 학습 양상은 서로 이질적이며, 해석하기 어려움
α 와 A가 각각 teacher, student data representation 이라고 한다면, 이 문제를 consistency loss 수식 하나로 표현할 수 있습니다.
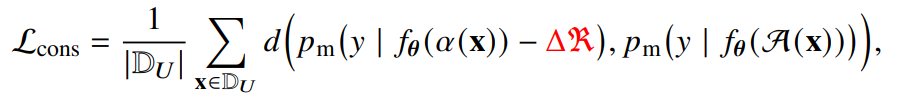
빌드업
VQ-VAE처럼 N개의 패턴 임베딩 X ∈ R^d * Z^N 을 가정하고, 입력된 데이터를 어떻게 표현해야 할지 쿼리 𝝃 가 들어올 때 출력되는 distribution을 Ise(X𝝃), ( ∑︁ Ise() = 1, softmax ) 라고 가정합니다. 그러면 자연스럽게 objective Energy function E는 아래와 같이 나타내지는데, 쿼리 𝝃가 패턴 임베딩 중 정확한 패턴 하나를 찾았을 때 E가 최소화됩니다.
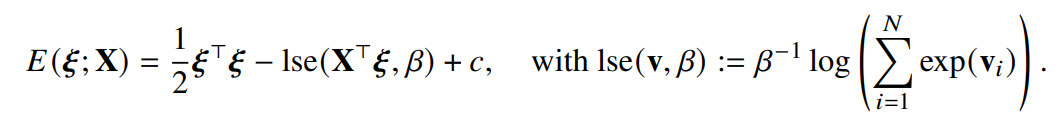
다만, 정확한 패턴이라는 레이블이 없으니 대신 distribution의 entropy를 최소화하는 문제로 대신할 수 있습니다. 이러면 너무 confident 해지는것 아닌가 싶을 수 있는데,
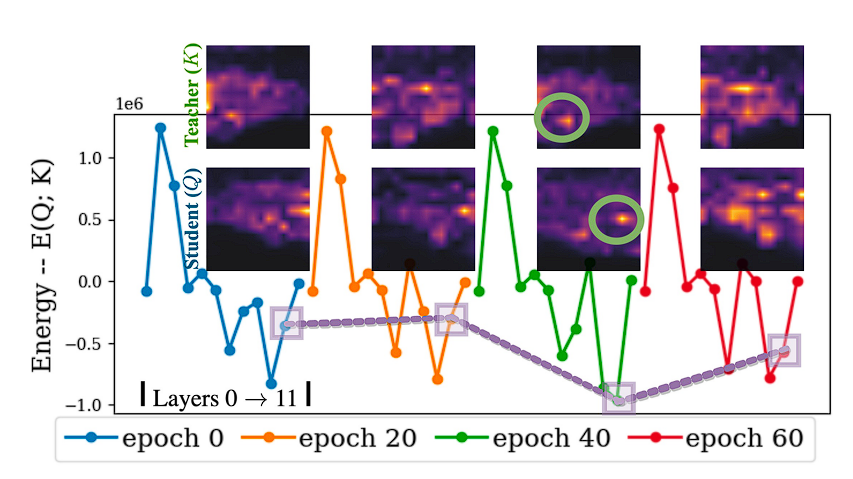
실제로 모델의 성능은 student와 teacher간의 attention distribution의 entropy와 반비례하는 것으로 관측됐습니다.
제안 방법
-
Highlight Figure
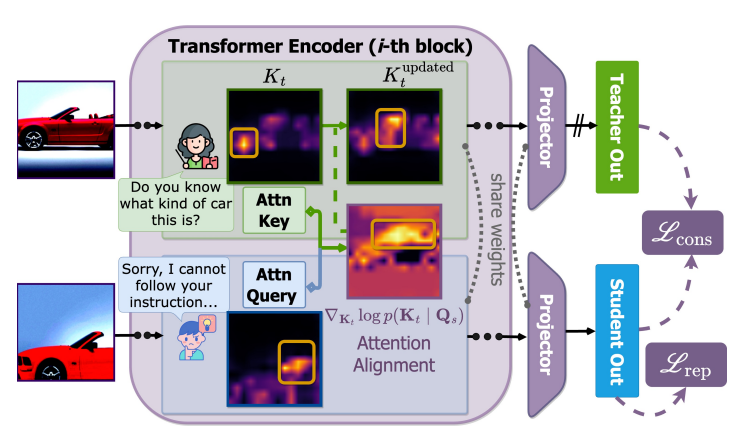
직관적으로도 teacher의 attention은 보다 정형적인 데이터로부터 학습됐으니, noisy한 데이터라 하더라도 robust한 attention을 위해서라면 student의 query에 대해 teacher의 key를 찾는 것이 이상적이라는 발상도 가능합니다. entropy를 최소화하는 문제에 적용할 때,
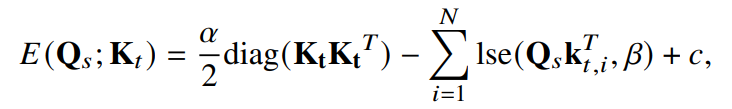
diag term은 K_t를 규제하는 역할입니다.
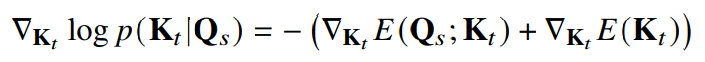
베이지안 정리를 통해 유도
나머지는 기존 loss를 사용합니다.
활용방안 및 향후 연구(개인적 의견) : NLP 분야에서는 attention이 깔끔하게 interpret된 연구가 아직 나오지 않은 걸로 알고 있어서, 비전 도메인에서 attention으로 이리저리 새로운 시도를 해보는 게 조금 부럽네요. 특히 본 논문과 같이 data를 student와 teacher로 추상화하고, 결국 representation learning이라는 본질을 잊지 않고 teacher의 key를 업데이트해야 한다는 바텀업 + 탑다운 빌드업이 인상적입니다. 어쩌면 기존 논문들의 전개 패턴보다 더 좋은 전개가 아닐까 싶기도 합니다.
✨Learning diffusion at lightspeed
“외부 조건 혹은 지식을 활용할 수 있다면 기존 DE에 비해 훨씬 빠르고 간단한 방법으로 학습할 수 있습니다.”
기존 연구 : energy-based model이 나온 이후로 diffusion을 DE로 접근하기 시작하면서, 다음과 같이 표현하게 되었습니다. J가 에너지 함수이고 μ는 t 시점의 μ_t에서 학습되는 probability measure, W_2는 Wasserstein distance일 때 t+1 에서,
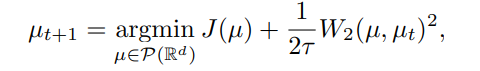
(W_2 부분도 argmin 안에 속해있습니다)
이는 일명 ‘JKO scheme’이라고 불립니다. μ_t+1가 낮은 엔트로피를 갖게 하여 μ_T로 향하게 하는 한편 Wasserstein distance를 통해 μ_t 대비 너무 크게 변화하지 않게 만듭니다. 또한 각 step을 명시적으로 표현하므로 timestep set {μ_1, μ_2, … μ_T} 중 아무 원소나 접근할 수 있다는 장점이 있습니다.
문제 정의 :

가능한 모든 미분 방법에 대해 탐색해야 하므로 계산량이 너무 많다는 문제가 있습니다. 이를 회피하기 위해 parametric한 신경망 \psi를 사용하고 실제 값과의 차이를 줄이는 방향으로 학습하게끔 설계되었지만, 정확한 차이를 계산하기는 어렵다는 문제가 있습니다.
제일 단순한 형태 : DE가 아닌 모델 J에 대한 최적화를 떠올려보면, 아래와 같은 꼴입니다.
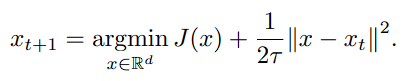
라그랑지안으로 term에 대한 미분꼴로 나타내고, 주어진 데이터 x_0~x_T에 대해 최적화한다 생각하면,
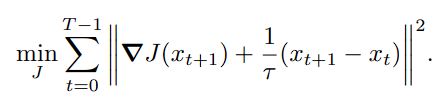
이렇게 단순하게 볼 수도 있습니다. 물론 DE solver가 필요하긴 하지만, 데이터가 변하지 않는다고 가정하면 신경망 학습 (Euler’s method) 으로 대체할 수 있습니다.
μ 대입 : J가 measure μ에 대해 적분한 형태이며, 어떤 함수 V: R^d → R가 있다고 가정한다면,
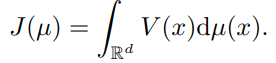
V(x)를 μ_t에서 μ_t+1로 이동할 때 발생하는 비용이라고 생각해봅시다. 커버 범위가 제일 넓은 Wasserstein distance \gamma (transportation plan)을 활용하자면,
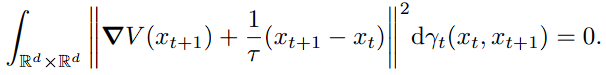
보기에는 복잡하지만 결국 V가 x_t에서 x_t+1로 이동하는 것이 당연하다고 학습된다면, Ideal case로서 상정할 수 있습니다.
전부 대입 : physics에서 사용되는 particle의 energy function을 전부 가져와봅시다.
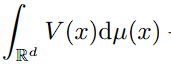
- potential energy V : μ_t에서 μ_t+1로 transport할 때 발생하는 비용
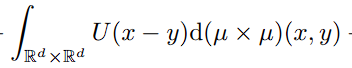
- interaction energy U : epoch i와 i+1 사이의 오차에서 발생하는 비용. 일반적으로 SGD에서 말하는 loss입니다. 여기서는 y로 표현됐습니다.
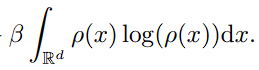
- internal energy H : 여기서는 entropy를 사용합니다.
위와 같이 function들이 모두 1차 미분식으로만 표현된다면, 전부 SGD로 학습 가능합니다.
페이퍼에서의 설명: 전체 측정 가능한 공간(측도 공간) 에 대해 미분의 미분 꼴을 구하려고 하면 필요한 데이터가 너무너무 방대해지는데, 이걸 1차 미분꼴로만 바꿔도 훨씬 간단해지고 필요한 데이터도 줄어듭니다.
특히 자연계 법칙과 같이 어떤 space상에 gradient가 고정된 형태를 가정한다면, 그로부터 얻은 데이터는 정답 그 자체이며 굳이 ‘생성한 데이터가 정답일 확률’ 에 해당하는 interaction energy나 internal energy는 그대로 제거할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 기존의 이미지, 영상 생성 모델들은 생성해낸 결과를 평가하기 위해 정답 probability function과의 KL divergence를 측정하는 등 난점이 너무 많아서 다양한 trick들이 나오게 된 건데, “사실 external knowledge를 활용하면 정답을 명확히 알 수 있는 문제” 라고 한다면, loss를 구성하는 term들 중 일부분만 사용해도 될 것입니다. 특히 강화학습의 경우 중간과정에 있어 정답이 있다던가, 아니면 중간과정을 검증할 수 있는 measure가 있다면 본 제안 방법을 통해 훨씬 빠르게 학습할 수 있을 것입니다. 앞서 소개드린 연구들과 어느정도 연결해볼 수도 있을것 같습니다.
DAPE V2: PROCESS ATTENTION SCORE AS FEATURE MAP FOR LENGTH EXTRAPOLATION
트렌드 배경 : transformer는 입력 토큰의 위치정보를 삽입하기 위해 positional encoding을 element-wise sum 하는데 이로 인해 (1) 학습할 당시 입력 길이보다 더 긴 입력을 처리하기 어려워 한다는 점, (2) 추론 시 입력 길이에 제한이 걸린다는 점 등이 주요 장애로 여겨졌습니다.
기존 문제 : 입력 길이를 늘려서 학습하면 당연히 학습속도가 크게 느려지고, 또 입력 길이가 길다 하더라도 학습 데이터의 input length dependency가 작으면 장기 문맥 추론 성능이 떨어집니다. (가불기?) 그래서 relative positional encoding이라 해서,
Attention(X) = XQ * XW
→ RelAttention(X) = XQ * XW + B
로 어텐션을 학습가능하게끔 하거나
→ RotaryAttention(X) = Rotational(Attention(X), T)
timestep T 주기로 어텐션이 동일해지도록 만들어 interpolation을 용이하게 만드는 방법이 제안되었습니다. 하지만 근본적으로 positional encoding 문제를 해결하지는 못합니다.
빌드업 : 모든 입력 토큰에서 위치 정보가 중요하게 사용되는 것은 아니고, phrase나 recall(혹은 검색?) 이 필요한 부분에서 위치 정보가 중요해집니다. 그러므로 입력 토큰의 의미정보가 고려되어야 합니다.
논문이 이끌어낸 직관 : 학습가능한 함수 f가 있을 때, DAPE(X) = XQ * XW + f( XQ * XW + B ) 를 통해 입력 토큰의 의미정보 및 학습 시 bias를 고려한 어텐션을 만들 수 있습니다. 다만 데이터를 받아 f를 학습시키는 방법이므로, 특정 도메인에 특화되는 방법입니다.
활용방안 및 향후 연구(개인적 의견) : 사람의 두뇌가 단기기억과 장기기억 담당 부분이 나뉘어 있듯이, transformer decoder 구조에서도 이를 구분하여 attention을 만들려는 시도는 계속되고 있습니다. 다만 어떻게 해도 approximation에만 해당하거나, general한 방법이 아닌 data adaptive 방법으로 우회하는 연구가 주류에 해당하여, State space machine 계열 연구가 아니라면 한동안은 난제로 남지 않을까 싶습니다.
You Only Cache Once: Decoder-Decoder Architectures for Language Models
“highest layer가 아닌 midst layer에서도 text length dependency가 어느 부분에 걸리는지 알 수(도?) 있습니다.”
문제 배경 : Transformer decoder가 LLM으로서 사용되고 있지만 input length에 대해 exponential 계산량을 가진다는 것은 닳고 닳은 문제입니다.
가정 및 실험결과 : 레이어 1 ~ mid 까지는 통상적으로 생성하고, 이에 대한 K, V 어텐션을 저장하여 레이어 mid ~ end 까지는 해당 K, V 어텐션만 사용합니다. 따라서 기존 계산량 O(n^2) 를 O(n^2/2) 으로 줄였습니다.
활용방안 및 향후 연구(개인적 의견) : 적용된 기존 제안 방법들이 너무너무 많아서 제안의 핵심인 ‘midst cache’ 가 묻힌 느낌입니다. ablation을 좀 넣었으면 하는데, 일단은 caching 기능을 효율화한 구조를 내놓았다는데 큰 의의가 있기는 합니다.
Improved Distribution Matching Distillation for Fast Image Synthesis
트렌드 배경 : diffusion model을 distillation 하면 좋겠죠?
기존 문제 : 기존 distillation 방법들(distribution matching distillation 등)은 여러 문제가 혼재되어 있는데, 제일 큰 문제는 diffusion process가 timestep T만큼 진행되는 과정에서, 0~T 모든 step에 대해 학습해야 하는지 등입니다. 안 그래도 diffusion process timestep을 discretize했다는 것도 문제인데, 소형 모델이 대형 모델의 매 denoised result를 베껴야 하는지도 문제입니다.
제안 방법
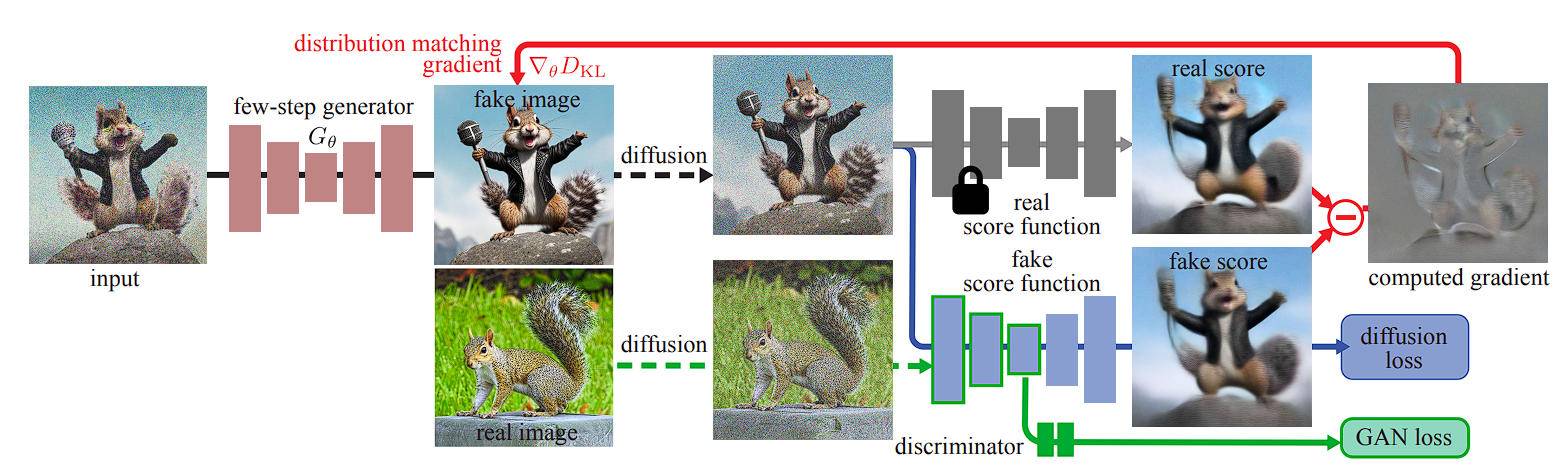
diffusion loss는 소형 모델이 자체적으로 계산하게 하고, score function과 GAN loss (between student and teacher) 만 teacher model을 활용합니다. 세가지 방법 모두 충돌없이 잘 동작하는데, 그 이유는
- diffusion loss는 어떤 모델에든 안정적으로 작동합니다.
- GAN loss를 통해 목표 생성 모델이 real image를 잘 생성하도록 유도할 수 있습니다.
- 실제 이미지와 생성된 이미지의 distribution matching score는 계산하는 데 많은 시간이 걸리지만 정확한 피드백을 줄 수 있으므로, 목표 생성 모델을 어느정도 GAN으로 학습시킨 다음 적용한다면 훨씬 효율적으로 학습 가능합니다.
다만 diffusion flow를 distillation할 경우, 학습할땐 [0, T] interval 중 샘플링하여 학습했던 반면 inference 과정에서는 0에서 T까지 쭉 process를 거쳐야 하니 서로 과정이 불일치한다는 문제가 있습니다. 때문에 입력 데이터는 어느정도 noisy한 데이터를 입력하여 diffusion process를 전반적으로 이해할 수 있게끔 합니다.
활용방안 및 향후 연구(개인적 의견) : 여러 방법론을 합쳐서 제안하는 연구는 일명 CVPR style 페이퍼인데, CVPR에 치팅 사건이 있었어서 그런지 NeurIPS로 많이 옮겨온것 같습니다. 당연히 제안 방법들은 모두 합리적으로 작동하고, 아키텍쳐도 좋지만 뭔가 그렇게 intuitive하다기보다 복잡한 코딩 문제를 풀어낸 느낌이긴 합니다.
MetaLA: Unified Optimal Linear Approximation to Softmax Attention Map
트렌드 배경 : transformer는 입력 길이에 대해 exponential하게 계산량과 메모리가 증가한다는 문제가 있습니다. 그래서 SSM 등 transformer를 대체하려는 시도는 계속되고 있지만, 아직까지는 성공적인 모델이 나오지 않았습니다.
기존 문제 : attention matrix가 분명 뭔가 불필요하게 너무 많은 연산량을 갖고있기는 한데, 이를 일반화한 형태로 표현하기는 무척 어렵습니다. 그나마 (1) 학습 데이터에서 long distance dependency가 없으면 추론 시에도 영향을 끼친다거나, (2) state를 정의하고 ODE로 계산 가능하다면 크게 경량화할 수 있다는 연구들이 어느정도 단서를 준다고 생각됩니다.
빌드업

위와 같이 다양한 transformer 대체재 제안 모델들을 정리하고 가중치들의 역할을 다음과 같이 정리했습니다.
-
Memorizing information : K, V cache가 제일 중요한 정보를 기억할 수 있는지
-
Modeling relationships : 임의의 입력에 대해 attention score를 바로 계산해낼 수 있는지
-
Transformers와 같이 문맥을 모두 고려한 attention에 approximate 할 수 있는지
-
Highlight Figure
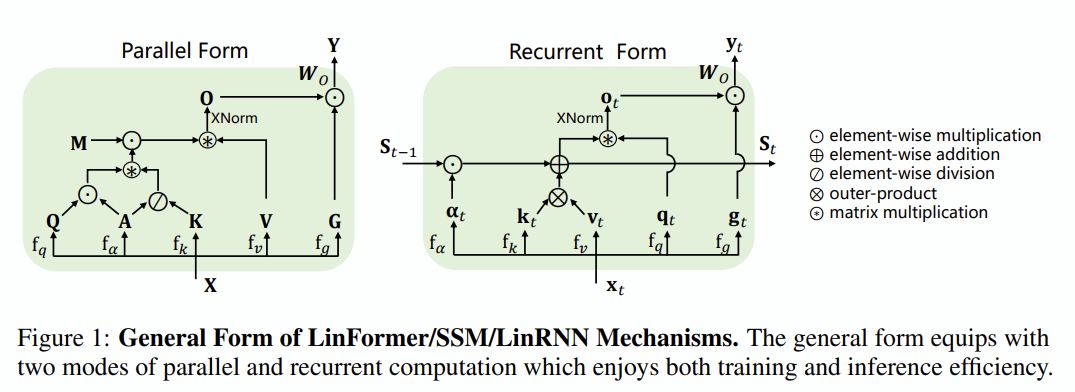
직관적으로는, Q는 이전 문맥들에 대해 연산을 요청하고, K는 어떤 단어에 얼마나 집중해야 하는지에 대한 정보를 전달합니다. 모든 문맥을 잘 기억하고 있다면 당연히 K를 잘 계산해낼 수 있지만, 현재 문맥이 어떤 ‘상태’(state)에 있다고 가정한다면, K를 Q에 대한 nonlinear 연산 함수 f로 대체할 수도 있을 것입니다.
제안 방법
입력 시점 t를 가정 할 때, 아래와 같이 이전 상태에서 기억해야 하는 정보 가중치 α와 1-α를 K로 사용합니다. (diag(α) ∈ R^t)
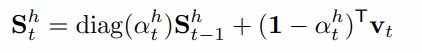
또한 output을 위한 learnable weight w_aug를 사용합니다. 약간 LM head가 생각나기도 하는 구조네요.
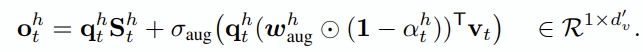
활용방안 및 향후 연구(개인적 의견) : 실험 결과야 기존 모델들보다 성능이 좋다고는 주장하고 있는데, 사실 이런 linear LLM들이 반박해야 하는 포인트는 다음과 같습니다.
- 모델이 task data에 특화되면, state 정보가 매우 단순하더라도 해당 task에 대해 어느정도 성능을 달성할 수 있다. 기존 연구 실험에서는 transformer를 task에 바로 train 시켜 성능을 비교했지만, pre-trained된 transformer를 사용했을 때는 기존 linear LLM들과 성능 차이가 거의 발생하지 않는다. (Amos et al., 2024)
- 모델이 pre-train이나 fine-tuning 시 학습하는 데이터가 long range dependency를 요구하는 데이터인지 등 데이터의 특성에 따라 같은 구조의 모델이더라도 long range dependency를 이해하는 정도가 다를 수 있다.
Maximum Entropy Inverse Reinforcement Learning of Diffusion Models with Energy-Based Models
트렌드 배경 : diffusion process는 state에서 주어진 action에 대한 policy, reward 등 RL로 문제전환할 여지가 많습니다. 특히 state step (원래는 timestep)을 discretize하더라도 꽤 그럴듯하게 성능이 나오니 기존에는 적용하기 어려웠던 여러 직관을 도입하는 시도가 이어지고 있습니다.
기존 문제 :
p(x) 실세계의 데이터 x에 대한 pdf
π(x_t | x_t-1)는 transition probability distribution, π(x)는 model이 학습한 데이터의 pdf
q(x)는 Energy-based model로 놓는다면,
KL(p||q) 를 minimize하는 문제를 다음과 같이 조금 쉽게 re-form할 수 있는데,
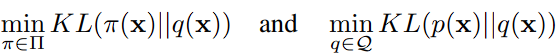
이 때 Ideal한 상태는 π(x) = p(x) = q(x)로, π와 q는 실제 데이터의 distribution을 완벽하게 학습한 모델이 됩니다. 그런데 그렇게 간단히 KL(p || q)를 계산하긴 어렵습니다.
빌드업
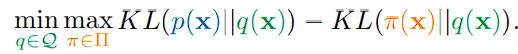
objective는 굳이 분리될 필요 없이 minimax problem으로 전환할 수 있습니다. 위 수식은 순서상으로야 diffusion model → Energy-based model 순으로 학습하지만, 반대로도 놓을 수 있습니다.
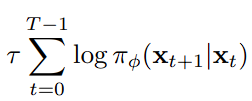
transition probability function π을 일종의 given state x_t에서의 action을 결정하는 모델로 놓습니다. RL 문제로 전환할 수 있는데, policy model을 학습하는 방법론을 적용해볼 수 있겠습니다.
제안 방법
diffusion process를 policy 모델로 문제전환한다면, 모델들의 역할을 정리할 수 있습니다.
Diffusion model → Policy(action) model π
Energy-based model → Cost function V* → Policy evaluator
Cost function V는 t 시점에서의 x가 t+1로 transition 될 때의 cost를 계산합니다.
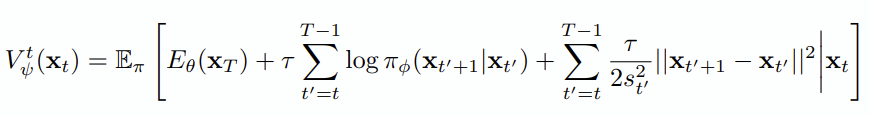
이 때 Cost function은 0에서 T까지 모든 스텝에 대해 계산하고 업데이트합니다. 이를 통해 단일 step이든 여러 step이든 아직 해당 step을 관측하지 못한 policy model이나 energy가 어떻게 설정되어야 하는지 evaluator 역할을 할 수 있습니다. 구체적인 evaluation 과정은,
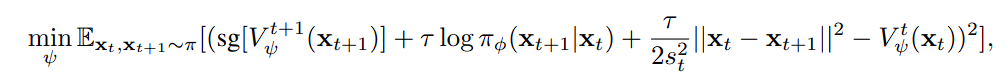
학습하기 전 단계의 cost function이 평가한 t+1 시점과 t 시점의 cost를 비교합니다. 이러면 0에서 T까지 모든 스텝을 거친 다음 순서대로 gradient를 계산하는 것이 아닌, 랜덤하게 두 스텝의 데이터를 샘플링하여 cost function을 학습할 수 있습니다.
cost function을 활용한 Policy model π의 objective는,
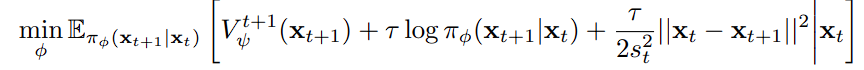
cost function + transition performance + regularizer 세가지 term으로 정리됩니다.
*. 본문에서는 future cost를 estimate하는 value function이라 했는데, 오히려 헷갈릴것 같아 그냥 cost function이라 서술했습니다.
4. Applications / Best practice
✨NeuroClips: Towards High-fidelity and Smooth fMRI-to-Video Reconstruction
“딥러닝과 뇌의 공통적인 추론 양상을 포착하고, 이를 활용하면 뇌파 해석 능력을 현저히 높게 끌어올릴 수 있습니다.”
문제 배경 : fMRI를 통한 뇌파 기반 인식 내용 해석은 “완전 몰입 가상현실”, “소드 아트 온라인”, 등 직접 의식을 가상현실에 띄우려는 시도의 첫 발걸음 정도입니다. 특히 video reconstruction은 중요하지만 아직까지 상당히 어려운 부분입니다.
domain-specific knowledge : 시각에 대한 뇌파정보는 사람에 따라 잔존 형태가 달라지거나 인식된 이미지의 해상도를 반영하지 않기 때문에 뇌파로부터 직접 인식된 이미지를 재현하기는 매우 어렵습니다. 하지만 이미지로부터 영상을 재현하는 것은 뇌의 인지기능과 동일한 매커니즘이므로, video reconstruction task로 모델을 학습하는 방법을 떠올릴 수 있습니다. 물론 시각 영역에 가까운 부분의 뇌파(low-level)와 인지 영역에 가까운 뇌파(High-level)의 형태가 다르다는 문제가 있지만, 이는 실제 딥러닝 모델의 low, high level layer로 해석할 수 있습니다.
빌드업 : 위에서 언급한 뇌과학적 지식을 모델에 반영하기 위해 Low-level perceptron과 High-level perceptron에 대한 representation learning을 수행합니다.
-
Perception reconstruction : 비디오를 보며 인식하는 fMRI 정보를 video reconstruction 합니다. fMRI 정보에 대한 representation learning이 목적입니다.
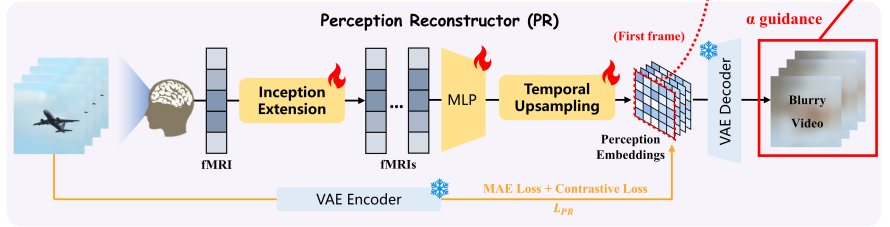
-
Semantics reconstruction : 비디오를 보며 인식하는 fMRI 정보 중 랜덤 키프레임 사진을 reconstruction 합니다. fMRI 정보중에서도 High-level perceptron representation learning이 목적입니다.
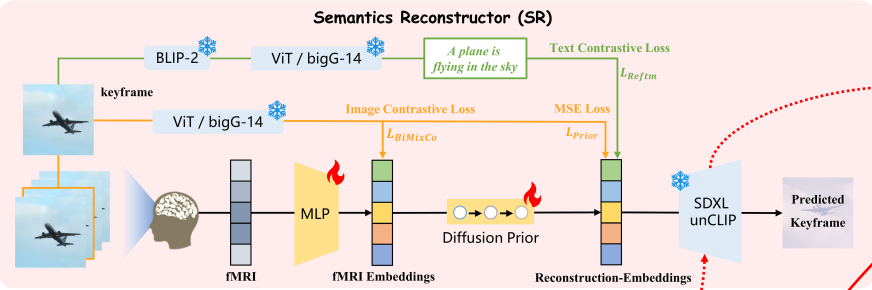
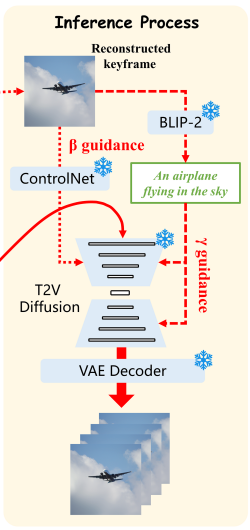
논문의 제안 방법
low-level representation을 각 키프레임에 대한 guidance로 지정하여 reconstructed keyframe을 입력으로 video generation을 수행합니다.
특히 생성가능한 비디오의 프레임을 늘리기 위해, 입력 비디오의 랜덤 앞부분과 뒷부분의 representation이 유사하다면 뒷부분의 키프레임을 입력하여 영상을 생성토록 합니다. 이를 통해 어텐션 없이 static한 영상과 dynamic한 영상을 구분하여 생성할 수 있습니다.
-
Highlights
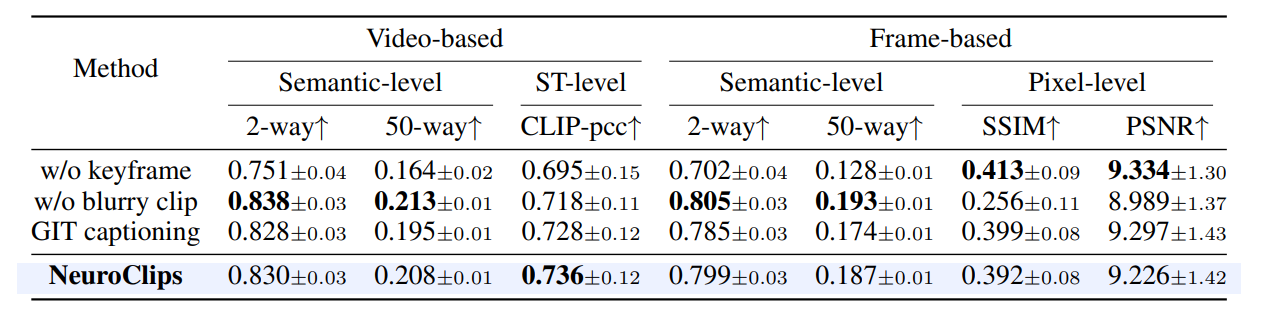
ablation study에서 low-level representation이 없을 때 성능과 high-level representation이 없을 때 성능은 각각 장단점이 뚜렷하게 나타나 hypothesis에 대해 empirical한 검증을 해냈습니다.
활용방안 및 향후 연구(개인적 의견) : 당연히 뇌과학 관련 연구는 어떻게든 진전이 되면 좋다고 생각합니다만, 딥러닝 모델을 활용하기에는 두 분야에 전문가 수준의 지식이 필요하니 상당한 시간이 걸릴 것으로 생각했습니다. 하지만 딥러닝과 fMRI 뇌파 분석을 각각 상세하게 분석하기보다, 직관적 원리를 기반으로 모델링 방법론을 제안한 연구입니다. 그럼에도 매우 뛰어난 성능을 보이고, 이후 ablation study에서도 비록 empirical하긴 하지만 가정에 대한 검증을 깔끔하게 해냈습니다. 다양한 필드의 도메인 지식을 직관화하는 능력이 핵심이었다 생각합니다.
Aligner: Efficient Alignment by Learning to Correct
트렌드 배경 : hallucination이든 toxic response이든 어떻게든 LLM에 윤리적 규제를 적용하기 위해 입출력, 추론양상 등을 통제하려는 시도는 계속해서 이루어지고 있습니다.
기존 문제 : LLM의 추론 양상은 너무너무 복잡해서 도저히 이론으로 설명하기도 어렵고, 어떤 지식을 가지고 어떤 추론을 해내는지도 아직까지 분석하기 어려운 상황입니다.
빌드업: 출력 결과가 toxic하지 않게 보정하는 방법이 필요한데, 기존 LLM의 학습방법으로는 helpfulness, harmlessness와 같은 추상적인 평가기준을 직접적으로 학습하기 어렵습니다. 이는 본질적으로 LLM이 학습한 확률분포와는 이질적인 분포를 따라야 하기 때문입니다.
-
Highlight Figure
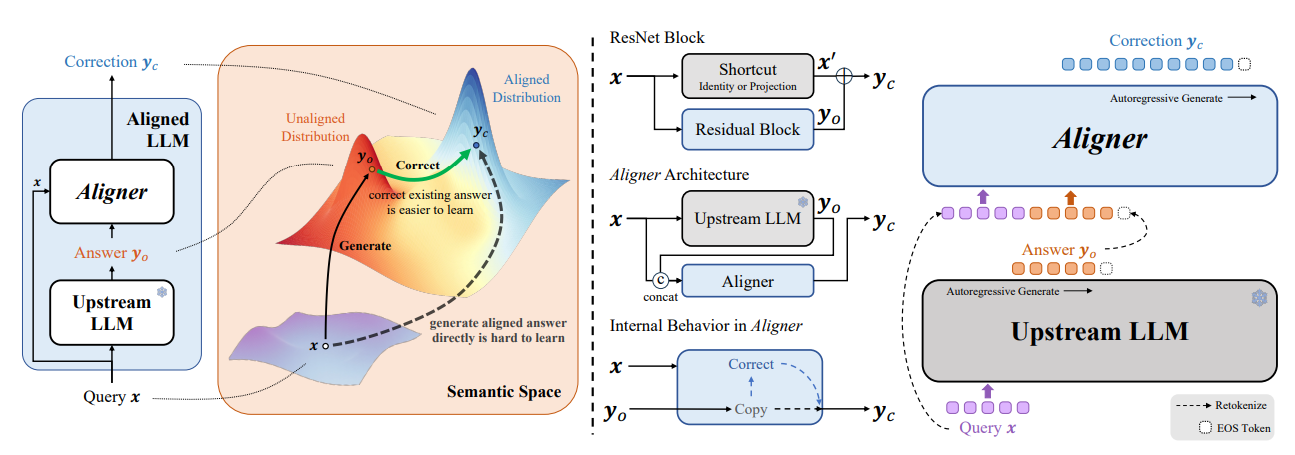
논문이 이끌어낸 직관 : LLM의 입출력 내용을 전달받아 이를 보정하는 소형 모델 ‘Aligner’를 제안했습니다. 해당 방법론은 helpfulness, harmlessness와 같은 추상적인 평가기준에 부합하도록 효과적으로 모델을 보정할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 아이디어 자체는 매우 심플하고 혁신적이랄것도 없지만, 다양한 적용안 (automatic toxicity metric, 모델의 출력 양상 분석, multi-round RLHF 등) 을 제시하고, 기존 방법 대비 효율적이라는 점도 좋은 포인트이기는 합니다.
Bayesian-Guided Label Mapping for Visual Reprogramming
Task 소개 : Visual reprogramming이란 학습된 모델을 바꾸지 않고 model이 수행할 task를 변경하는 방법입니다. “특정 downstream task를 풀기 쉽게 바꾸는 noise”를 입력 데이터에 입힌다던가, 출력 레이블을 기존에 예측하도록 학습한 레이블로 1:1 매핑하여 task에서 요구하는 label로 바꾸는 방법입니다. representation learning이 잘 되어있다면 zero-shot classification과 유사한 매커니즘으로 동작하리라 예측할 수 있고, 모델 가중치를 공개하지 않으면서 유저가 요구하는 task에 빠르게 adapt 시킬 수 있다는 장점이 있습니다.
기존 문제 : 당연하게도 학습된 모델의 label set과 유저가 요구하는 label set이 다르면 그에 따른 오차가 발생할 것입니다. 특히 본문에서는 1:1 매핑 방법의 문제로, 본래 모델의 uncertainty, probability distribution 정보의 손실을 지적합니다. 베이지안 방법을 사용한다면 원래 모델의 uncertainty를 어느정도는 반영할 수 있습니다.
제안 방법 : 본래 모델의 입력 데이터 X_s 예측 레이블값이 Y_s, downstream task 데이터 X_t, 레이블 Y_t일 때, 변환된 데이터 X_t에 대한 두 종류의 레이블 Y_s, Y_t 모두에 대해 계산합니다. summation을 통해 레이블 {{y_s, y_t} | y_s ∈ Y_s, y_t ∈ Y_t} 에 대해 계산하고 나면, X_s를 X_t로 변환하는 visual reprogramming 방법에 더 풍부한 정보를 propagate할 수 있습니다.
-
Highlight Figure
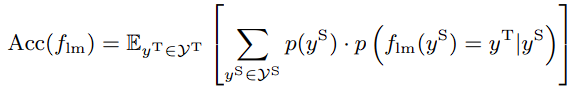
활용방안 및 향후 연구(개인적 의견) : 워낙 새로운 분야여서 그런건지 단순한 방법도 발표세션에 실리긴 하네요. 다만 본문에서 소개하는 task는 서비스를 제공하는/제공받는 입장에서 워낙 안전성도 좋고 즉각적으로 PaaS, SaaS에 탑재해 활용할 수 있는 방법이기는 합니다. 나아가서는 입력 데이터의 변화에 따른 representation의 변화 분석이나 representation 해석 연구에 단서로 작용될수 있지 않을까 싶습니다.
Stylus: Automatic Adapter Selection for Diffusion Models
트렌드 배경 : 스테이블 디퓨전의 등장을 계기로 이미지 생성 모델이 점점 보편화되고 있고, 태그나 interpolation 등 직관적인 수정 도구 또한 자주 사용되고 있습니다.
기존 문제 : 모델이 보편화되려면 가벼워져야 하는데, 당연히 가벼워질수록 생성 퀄리티는 낮아집니다. 클라우드 서비스를 고려하더라도 하나의 엄청나게 큰 모델에 요청하는 것보다 생성 주제에 따라 적절한 소형 모델에 요청을 흘려주는 것이 좋습니다.
빌드업 : 기본적으로 사용자는 문장 형태의 질의문을 제시하고, 그에 대응하는 adapter set이 있다고 가정합니다. 만약 adapter 여러 개를 골라 생성할 때 interpolation이 잘 작동한다면, <LLM - adapter set - image generator> 구조로 이미지 생성 시스템을 구현할 수 있습니다.
- Highlight Figure
제안 방법 : 총 세 단계로 나뉩니다.
- Refiner : 어댑터들의 [모델 카드, 프롬프트, 설명] 을 임베딩하여 어댑터와 pair시킵니다.
- Retriever : 어댑터 설명 임베딩을 기반으로 어댑터를 검색합니다.
- Composer : 사용자의 질의문을 task로 정형화하고, 이에 맞는 어댑터를 재선택합니다.
이후 model merge의 원리를 인용하여 아래와 같이 최종 가중치를 계산합니다.
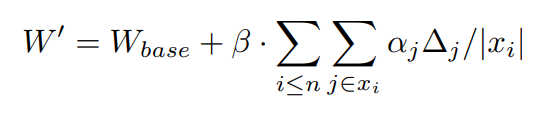
활용방안 및 향후 연구(개인적 의견) : interpolation이나 여러 복잡한 부작용을 해결하는 대단한 방법이 있을 줄 알았는데, model merge 연구를 인용했네요. 저자들도 이해가 안 가는 방법론으로 알고 있었는데, 시간내서 아예 논문을 읽어봐야겠습니다.
Do Finetti: On Causal Effects for Exchangeable Data
트렌드 배경 : LLM에게 있어 가장 취약한 부분은 학습 데이터의 전반적 Causality를 파악하기 어렵다는 것입니다. 때문에 오래전부터 계속해서 연구되고 있는 영역이고, 특히 의학 분야에서는 더 활발하게 연구되고 있습니다.
-
Highlight Figure
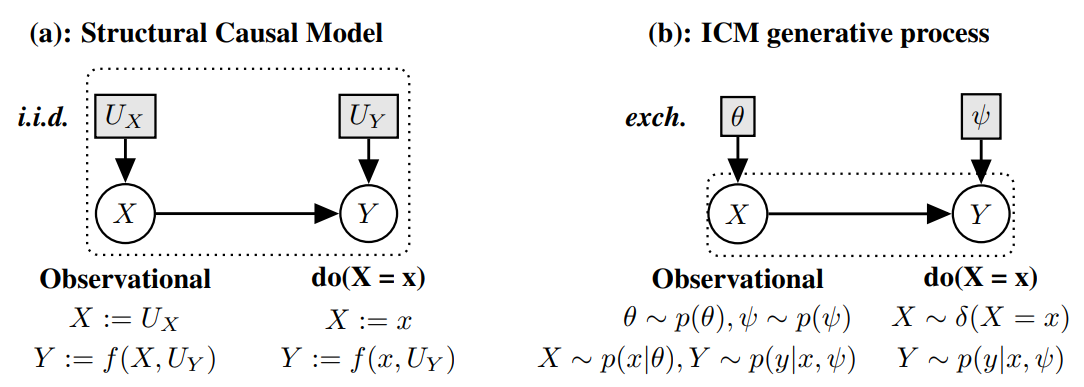
제안 방법 : iid assumption 대신 ICM assumption을 제안합니다.
활용방안 및 향후 연구(개인적 의견) : 기존 causality 관련 연구들에 비해 수식 표현 등 읽기는 좀 더 쉬워졌고, 아이디어도 pdf에 condition을 고려하자는 intuition으로 간략화하여 applicability도 챙긴 느낌인데, 여전히 ‘그래서 어떻게 데이터를 얻어야 할까’ 라는 문제점이 있습니다. 물론 given data에 대한 assumption으로 활용할 수도 있겠지만, theta로 표현된 condition이 신경망 내부에서 전부 설명될 수도 있으며, LLM의 interpretability 문제로 직결되기 때문에 아직까지 여러모로 한계점이 많습니다.
Enhancing Preference-based Linear Bandits via Human Response Time
“광고 클릭률 등 대부분의 레이블이 편중되고 mode의 density가 매우 작은 분포를 추산해야 하는 경우, 반응 시간을 고려하면 더 유익한 정보를 얻을 수 있고, 그와 반대인 경우에는 반응 시간을 제외하는 것이 더 유익한 정보를 얻을 수 있습니다.”
트렌드 배경 : RLHF가 인기를 얻으며 사람에게서 어떻게 더 효율적으로 높은 퀄리티의 데이터를 얻을 수 있는지 하는 방법론들이 계속해서 나오고 있습니다. 그러다보니 심리학과, 의과 등 다양한 분야의 이학계열 이론들이 활용되고 있습니다.
기존 문제 설정 : 특정 사람의 성향 θ*가 질문 x를 받았을 때의 응답 c는, 일정 랜덤성(Brownian motion) 을 추가적으로 고려하면 아래와 같이 표현됩니다.
추천 알고리즘이나 일반적인 선택 방법론에서 자주 사용되는 수식인데, 사람의 성향 θ을 분석하기 위해 준비된 질문 x와 그에 대한 응답 c를 linear regression 방법으로 θ를 역산하게 됩니다. 문제는 대부분의 응답이 한쪽으로 편중되어 있을 경우, θ*의 일부 차원이 과장되어 역산됩니다. 이를테면 광고 추천 알고리즘에 야한 광고만 계속 나오는 문제 등이 있습니다.
가정 제시 및 분석 : c를 결정하는 데 있어 추론 정보량 a가 필요하고, a를 모으는 데 시간 t_x가 소요된다고 가정하면, a가 클 수록 결정을 내리는 데 많은 시간이 걸립니다.
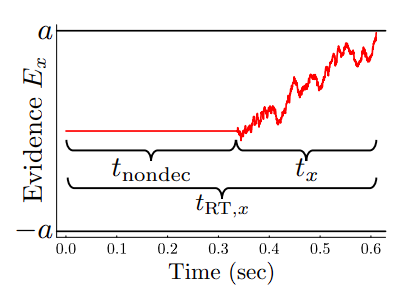
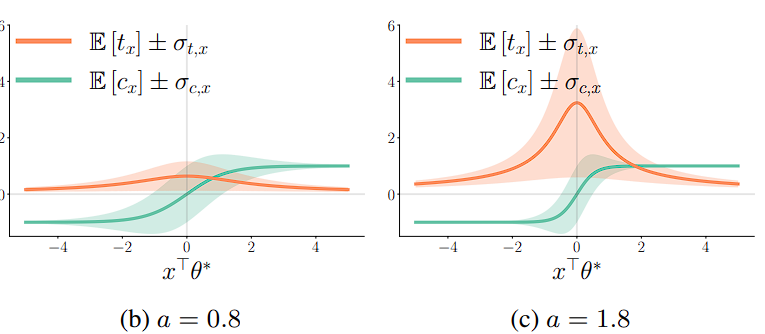
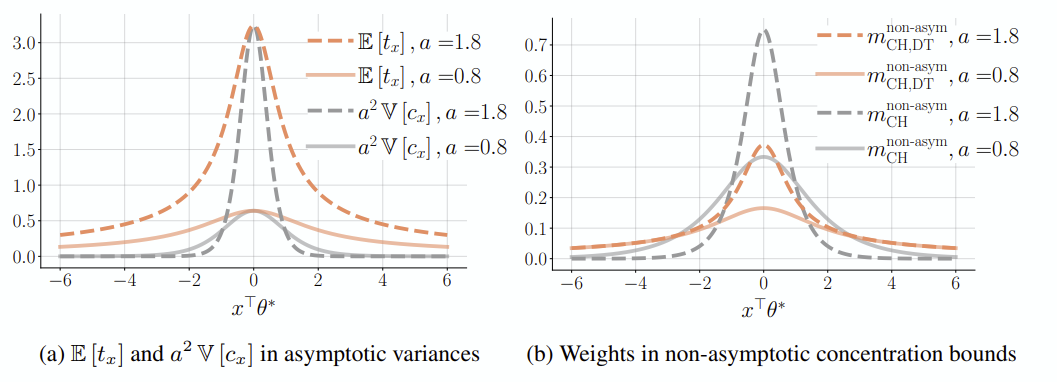
기존 문제 설정에서 c의 평균이 0이라고 가정한다면, MLE로 L(θ*)를 찾는 것이 사람의 성향을 추측하는 데 있어 핵심이 됩니다.
- a의 평균이 작아질수록 L(θ*)는 smooth해지므로 uncertainty가 너무 커집니다. 하지만 t_x를 활용한다면, 이따금씩 발생하는 ‘추론에 오랜 시간이 걸리는, 정보량이 풍부한 query 혹은 θ*’ 를 잘 포착할 수 있습니다.
- 반면 a가 커질수록 t_x의 평균에 비해 분산이 낮을 가능성이 크므로, t_x를 고려하면 오히려 특정 평균으로 수렴해버립니다. 따라서 t_x를 사용하지 않는 쪽이 오히려 더 풍부한 정보를 얻을 수 있습니다.
제안 방법 : 총 선택 시간을 budget으로 놓습니다. 그리고 기존 문제 설정과 제안 문제 설정으로 θ를 유추했을 때, 실제 참가자의 성향을 얼마나 잘 예측했는지 평가합니다.
선택 시간을 예측하는 선형 모델을 만들고, OLS로 전개 가능한 linear regression 문제로 풀 때, 다음과 같은 correlation을 formulize할 수 있습니다.
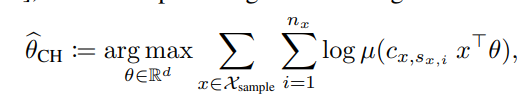
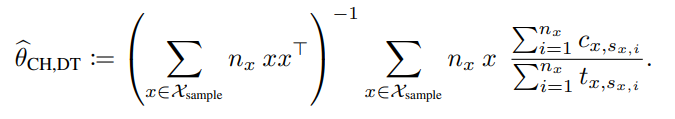
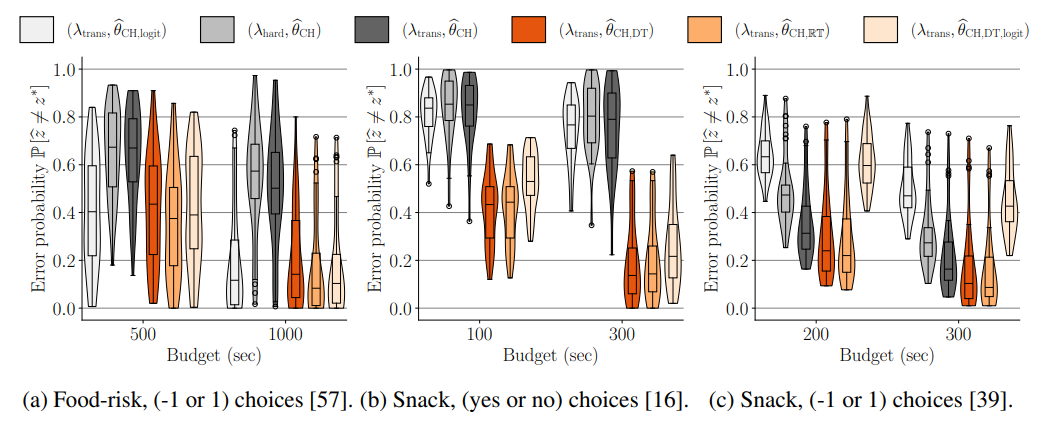
활용방안 및 향후 연구(개인적 의견) : 처음 봤을 때는 ‘당연히 추가적인 정보가 있으면 좋지’ 라고 생각했는데, 다른 분야의 연구/실험은 cs 분야처럼 자유롭게 데이터를 얻을 수 없으니, budget 대비 최대한 많은 정보를 얻는 것이 중요하겠다는 생각이 들었습니다. 다만 딥러닝이라기보다 통계에 가까운 페이퍼같다곤 생각합니다.
5. Cost-efficient methods
✨DapperFL: Domain Adaptive Federated Learning with Model Fusion Pruning for Edge Devices
트렌드 배경 : Federated learning이란 휴대폰 등과 같이 많은 사용자들이 제각각의 데이터를 가진 상황에서, 일괄적으로 서버에서 배포하는 ‘글로벌 모델’ 을 다양한 디바이스와 데이터로 오류 정도를 계산한 뒤 글로벌 모델이 이를 취합하여 주기적 학습을 가능케 하는 방법론입니다. 엣지 디바이스가 점점 발전함에 따라 사용자 디바이스에서도 소형 학습이 가능해지자, 이제는 gradient를 서버로 전송하는 방법으로 발전하고 있습니다.
기존 문제 : Federated learning에는 치명적인 문제 두가지가 존재합니다. (1) 모든 디바이스가 같은 사양을 갖지 않으면 gradient의 정확도, 형태 등이 달라지고, (2) 사용자 성향에 따라 특정 도메인에 집중해버릴 우려가 있습니다. Federated learning의 궁극적인 장점인 “가성비 높은 다양한 도메인의 데이터” 가 오히려 반대로 적용할 수 있다는 것입니다.
-
Highlight Figure
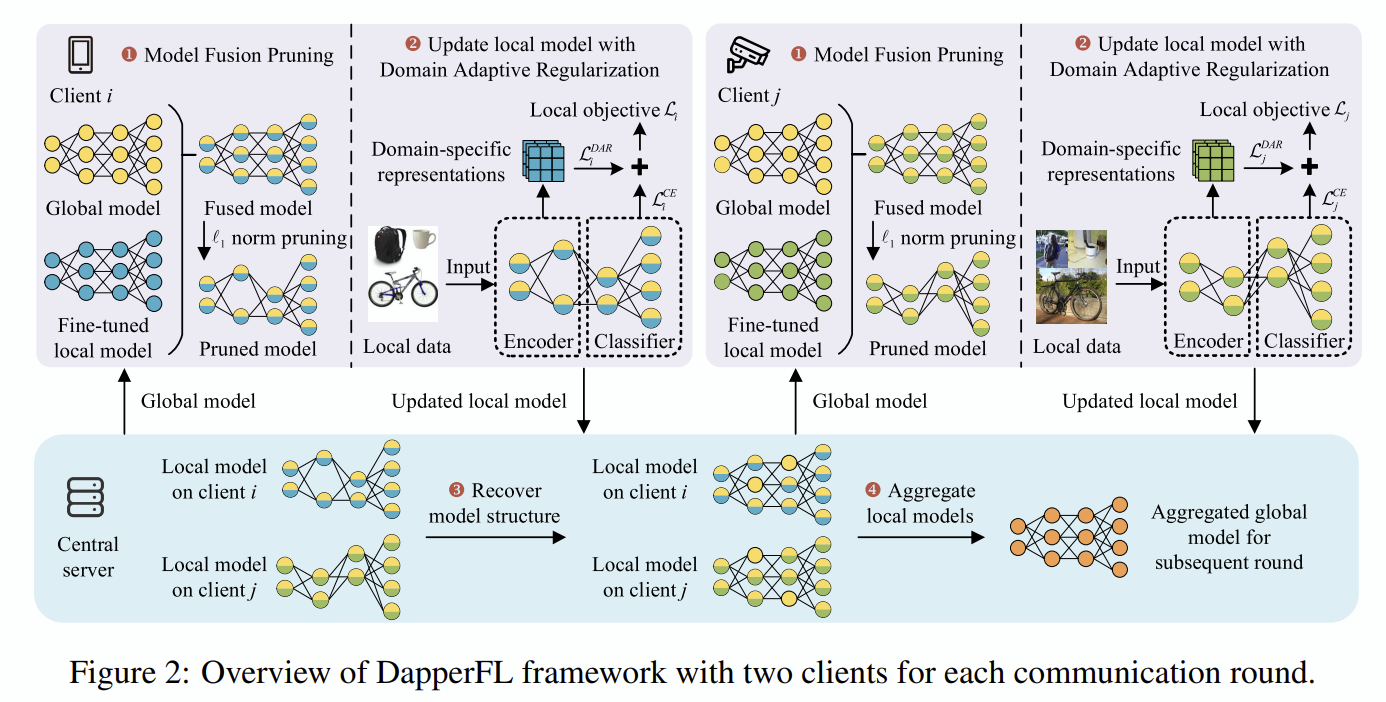
제안 방법 : 로컬 모델을 pruning하고 domain-specific objective에 맞춰 학습시킵니다. 이들을 취합하면 자연스럽게 글로벌 모델은 pruning 이전의 구조와 동일해지는데, 이는 dropout 학습과 거의 유사한 형태이므로 stability와 generalizability 모두 확보 가능합니다.
활용방안 및 향후 연구(개인적 의견) : model pruning을 200% 활용한 방법이라 아이디어가 대단하다고는 생각하지만, model merge와 같은 최신 연구를 다루지 않아 좀 의아한 부분은 있습니다. model merge에서의 dynamics를 고려해본다면 추가적인 성능 개선의 여지가 있어 보입니다.
Not All Tokens Are What You Need for Pretraining
트렌드 배경 : 너도나도 LLM pretrain에 뛰어들게 되면서 raw corpus를 어떻게 얻는지, 데이터 품질은 어떤지 등 데이터에 집중한 연구가 쭉 쏟아져나오고 있습니다.
기존 문제 : LLM이 학습할 데이터가 noisy하다면 모델 성능이 저하되기도 합니다.
빌드업 : LLM 학습 체크포인트별로 evaluation loss가 작았던 토큰 (L), 높았던 토큰 (H) 그루핑한다면, 전자쪽은 loss가 더 빨리 떨어지지 않을까~ 라고 예측해볼 수 있지만 실제로는 토큰 종류와 상관 없이 학습 과정 중 loss는 fluctuate합니다.
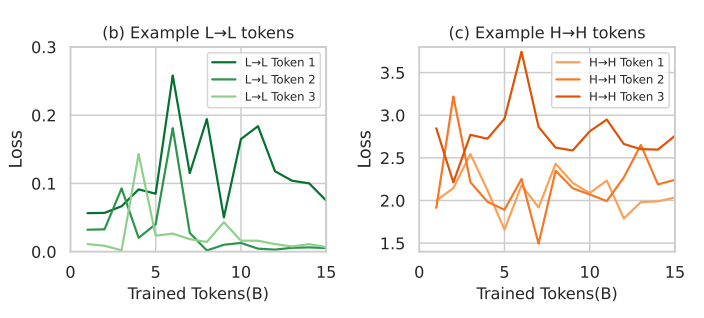
제안 방법 : 따라서 high-quality corpus에 대해 language modeling 된 Reference Model 대비 Loss 차이가 큰 토큰들을 우선적으로 학습합니다.
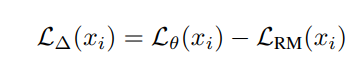
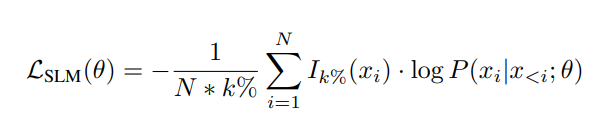
활용방안 및 향후 연구(개인적 의견) : 학습할 부분을 효율적으로 개선해야 한다는 말은 중요한 이슈이기는 하지만, 이렇게 어처구니없게 나이브한 연구가 NeurIPS oral에 나온 건 좀 실망이네요. distillation, active learning이란 키워드를 들어봤다면 노벨티를 인정하기 어려울텐데, 다소 의문이 드네요.
HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-Tuning
트렌드 배경 : 경량화 학습 방법(PEFT) 은 나오면 나올수록 좋습니다.
기존 문제 : LoRA는 특정 도메인이나 자주 발생하는 데이터에 집중된다는 점이 문제입니다.
Analyses
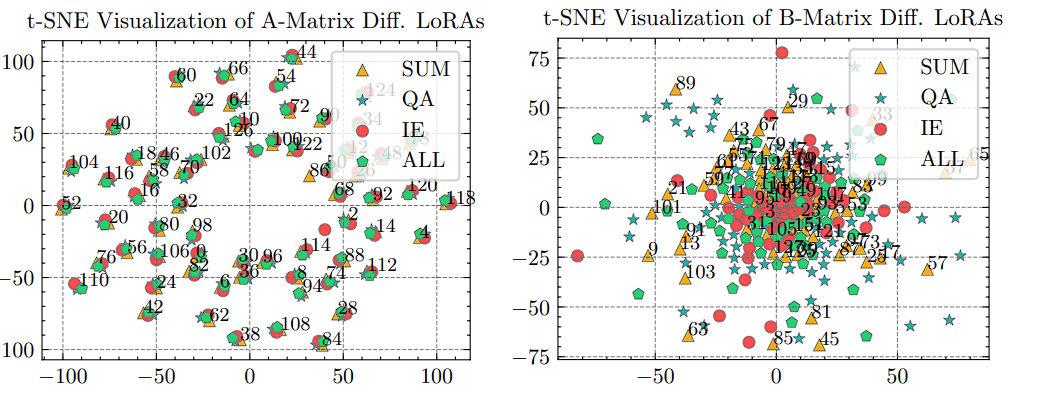
LoRA가 y + ∆y = Wx + BAx 라고 할 때, matrix A는 입력정보를 목표 차원에 맞게 잘 분해해주는 한편 B는 collapse되는 경향을 보입니다. 따라서 B를 분리하는 approach를 생각해볼 수 있습니다.
제안 방법 : 기존의 BAx를 다음과 같이 바꿉니다.
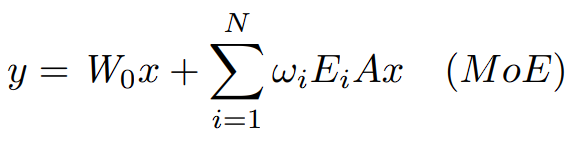
where \omega_i = softmax(Wx), hence Σ\omega_i = 1
이 때 \omega_i 는 element-wise multiplication이라 보면 되는데, \omega_i 의 계수는 empirical하게 정합니다.
활용방안 및 향후 연구(개인적 의견) : 이번 NeurIPS oral에 한정하면 이 논문이 최악이지 않을까 싶네요. naive한데다 empirical하게 설정되는 hyperparameter가 있고, 심지어 그에 대한 실험이나 분석도 제대로 이루어지지 않았습니다. MoE에 대한 연구나 분석 기법도 꽤 많이 나온걸로 아는데 이 논문이 도대체 왜 NeurIPS oral인지는 이해가 가질 않네요.
-
Reviewed after 2024
-
Rethinking LLM Memorization through the Lens of Adversarial Compression
제안 방법: y = f(x) 일 때 pair (x, y)가 학습되었는지 확인하기 위해
subject to
인 x’을 찾습니다. 즉, y를 답하게 하는 최소 길이의 x’를 찾는 방법입니다.

이게 왜 제안 방법이냐 하면, 의도치 않게 수집된 데이터는 대부분 이걸 까뒤집어 찾기 어렵게 랜덤 패턴 뒤에 이어붙인 경우가 많기 때문에, 역으로 말도 안되게 짧고 이상한 입력문에 대해 고품질의 텍스트를 답한다는 것은 이에 대한 반증이기 때문입니다.
알고리즘은 더더욱 황당한데, 맨 먼저 최소 길이로 y를 생성할 수 있는 x’를 찾고, 그게 안되면 +5 토큰을 더한 조건으로 x’를 찾습니다. 이렇게 길이 x보다 작은 x’을 찾지 못하면 실패, 아니면 성공입니다.
물론 알고리즘이 문제가 아니라 이 제안 방법으로 여러 흥미로운 결과를 얻었는데,
-
system message 등으로 response denial 등을 학습케 해도, 본 방법으로 찾은 x’은 여전히 유효합니다. 즉,
이더라도 이 가능합니다.
-
본 방법으로 data augmentation을 하면 unlearning에 더 많은 step이 필요합니다.
-
모델이 클수록 본 방법의 성공률이 높아집니다.
-
데이터가 랜덤 패턴에 가까워질수록 본 방법의 성공률이 낮아집니다.
-
Ex Uno Pluria: Insights on Ensembling in Low Precision Number Systems