Reports about Recent Advances in DL © 2025 by Seunghyun Ji is proprietary licensed.
목차
- 들어가기 전
- Novel architecture
- Latent analysis
- Challenges to traditional beliefs
- Diffusion / SSM
- Simple methoda
- Improvements
- Applications
본문
0. 들어가기 전
올해의 best novel paradigms : Latent Reasoning
이제 Reasoning 과정은 언어가 아닌 Latent Representation 레벨에서 이루어질 수 있습니다.
1. Novel architecture
✨Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
TL; DR: Intermediate layer를 ‘reasoning layer’처럼 사용하여 기존의 COT reasoning을 대체합니다.
기존 문제: reasoning 과정은 주어진 질문에 대해 text를 쭉 생성하게 한 다음 이를 기반으로 답변을 생성하도록 구현되어 왔습니다. 때문에 reasoning을 학습하기 위한 데이터 및 reasoning으로 인한 regression (일명 자폐) 이 명백했으며, context length 한계 또한 지니고 있었습니다.
제안 구조:
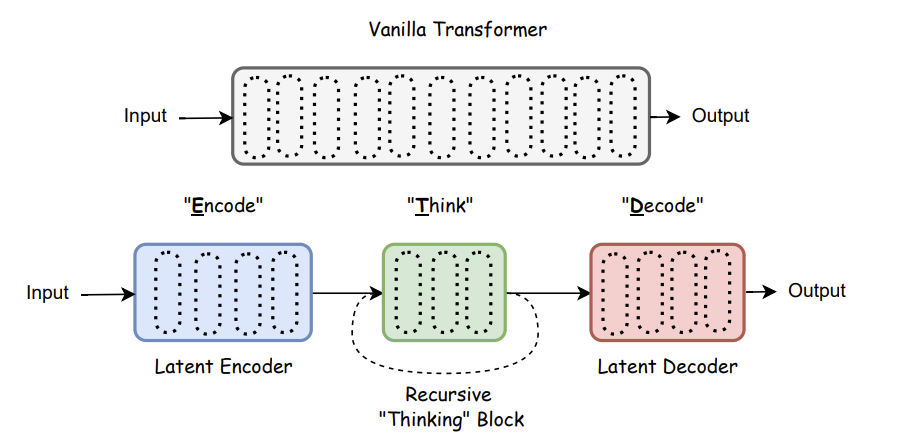
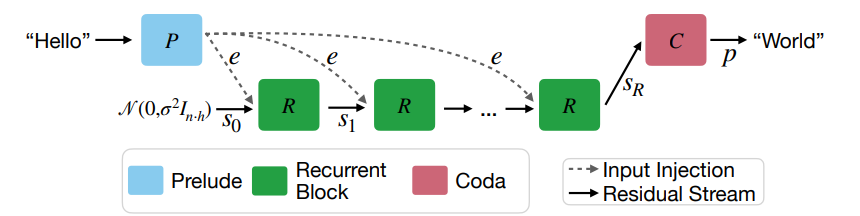
기존 트랜스포머 레이어들 중 중간 레이어들을 ‘reasoning layer’ 로 간주하여 RNN처럼 사용하며, reasoning을 거친 뒤 마지막 ‘coda layer’에서 토큰을 생성하게끔 하니다. 그리고 reasoning 과정에서는 embedding layer를 넣는데, 이는
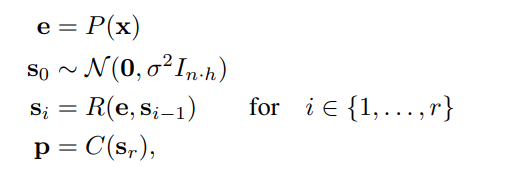
gradient descent가 주어진 입력을 iterative하게 최적화하는 과정을 본따 residual signal을 주기 위함입니다.
즉, reasoning 과정이 토큰을 생성하고 이걸 자신한테 다시 입력하는게 아니라, reasoning block을 계속해서 돌리는 과정으로 대체되는 것입니다. reasoning block를 몇번 돌릴지에 따라 능동적으로 reasoning 정도 또한 조절할 수 있습니다.
실험 결과
실험 결과는 아주 놀라웠는데,
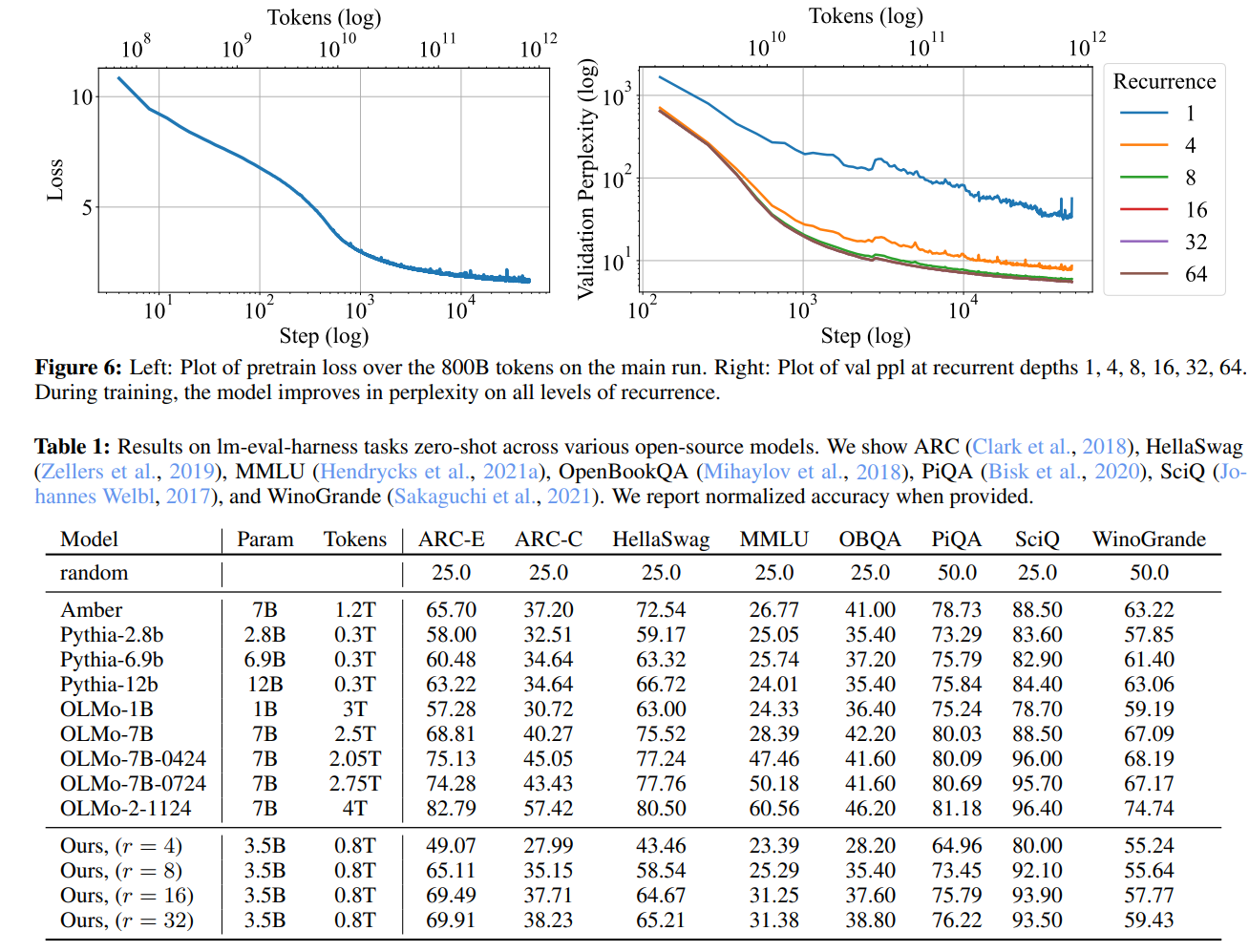
기존 모델들에 비해 학습 토큰량이나 모델 파라미터가 훨씬 작음에도 높은 성능을 달성했으며
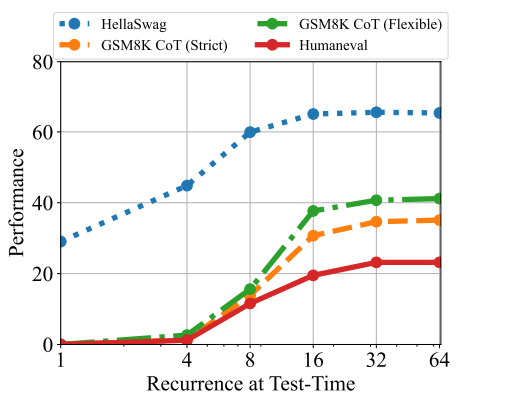
reasoning step에 따라서 smooth하게 성능이 나오고
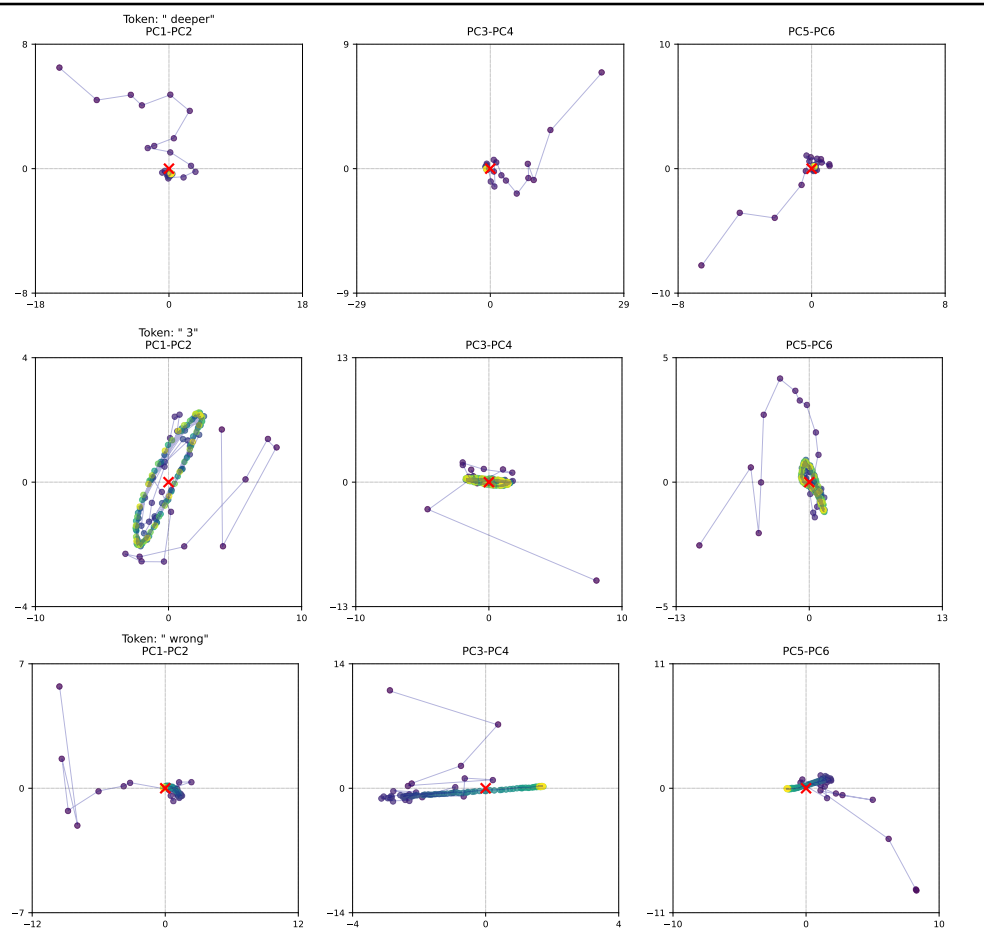
심지어는 reasoning vector s_r의 궤적이 정말로 gradient descent처럼 움직이는 것을 확인했습니다.
개인 의견
제 생각에는 transformer나 bert 수준으로 매우 혁신적인 논문이며, 이로 인해 LLM 판도 자체가 바뀔거라 생각합니다.
Auto-Compressing networks
TL; DR: Residual connection이 다음 레이어가 아니라 마지막 레이어에 꽃히게끔 합니다.
기존 문제: Residual connection이나 layer permutation 등 현재의 딥러닝 구조에 효율화할 여지가 많이 있어보이긴 하는데, 어떻게 할지는 난감한 상황이 계속되어 왔습니다.
제안 방법:
놀라울정도로 간단한 변경을 제안합니다.
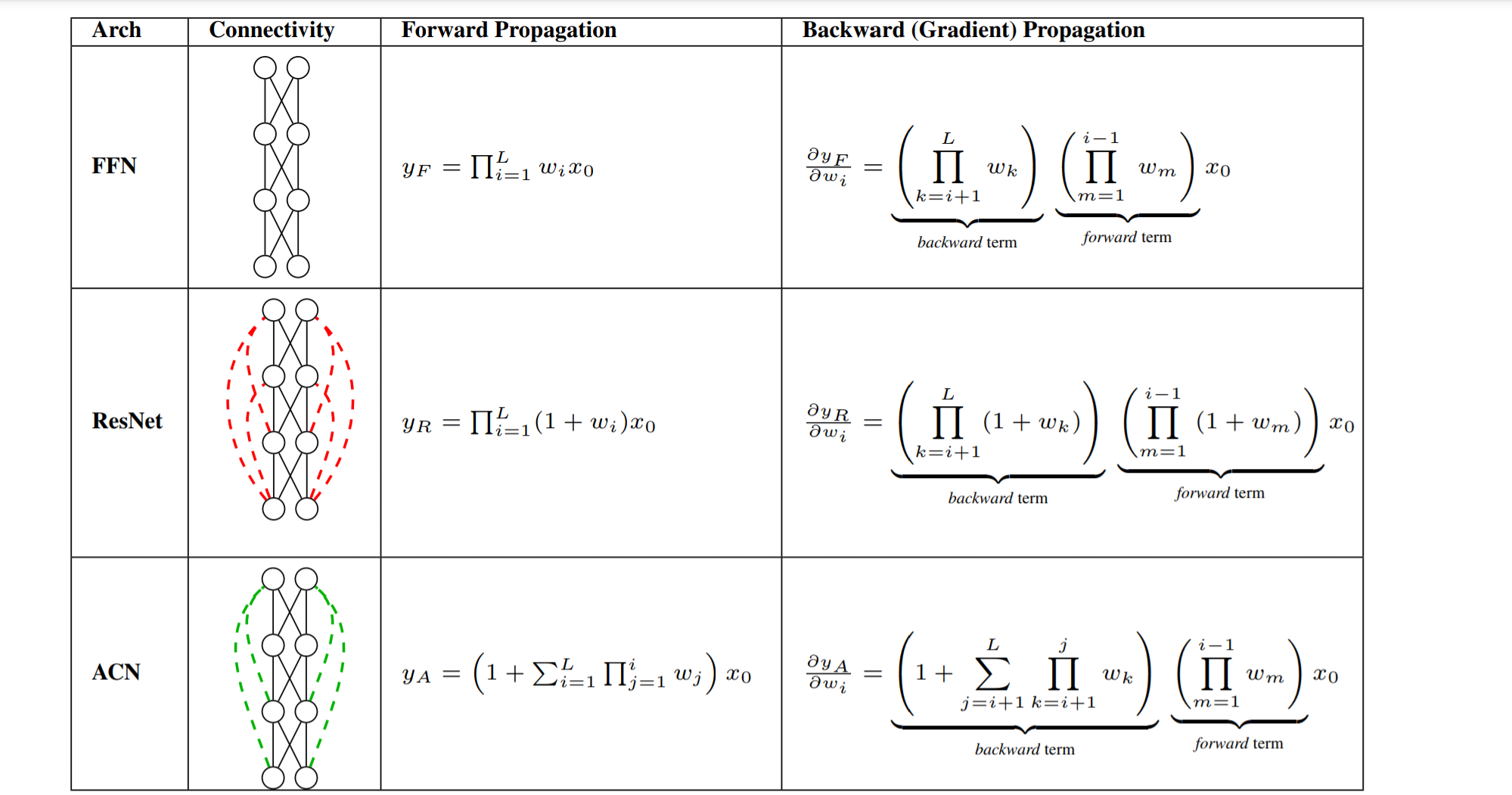
즉 residual connection을 다음 레이어가 아닌 마지막 레이어에만 주는 방법인데, 이러면 그래디언트가 전파될 때 모든 레이어로 직접적으로 한번씩만 전파되니 기존의 residual처럼 희석되는 효과가 없어 강해지고, 반대로 forward 시에는 첫 레이어가 마지막 레이어에 직접적으로 전달되니 레이어가 깊어질수록 약해집니다.
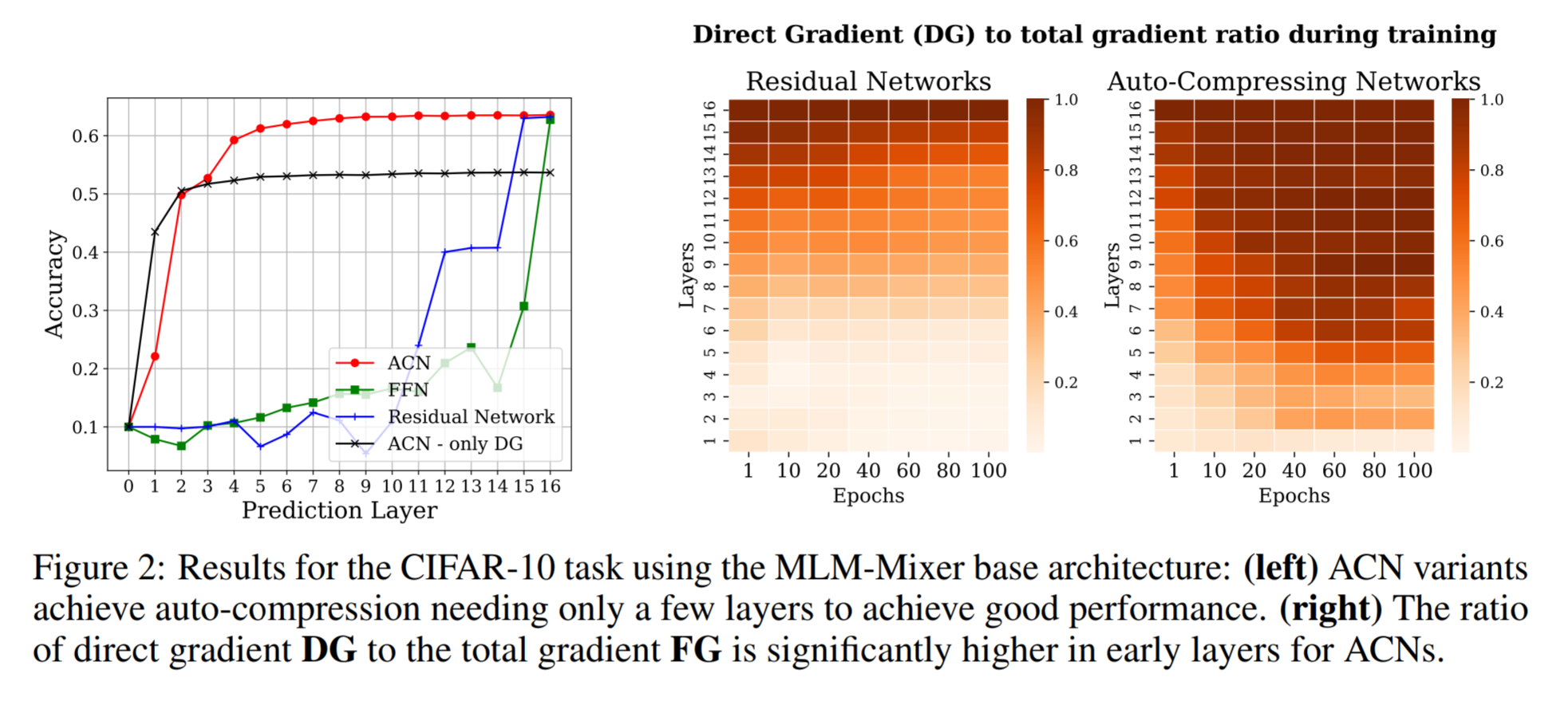
다만 논문에서는 forward의 신호를 낮추고 gradient의 신호를 높이는 것이 효율적인 학습 방법이라 보았고, 실제 본 모델 구조는 레이어 초반부가 forward에서, 레이어 전반적으로 고르게 backward gradient가 흐르는것을 볼 수 있었습니다.
실험 결과
실험 결과는 정말 놀라운데, 본 모델 구조는 performance는 유지하면서도 model size efficiency, training efficiency, robustness 모두 향상시켰습니다.
개인 의견
제 2의 moe라고 봐도 될 정도로 대단한게 하나 나온것 같네요
Harnessing the Universal Geometry of Embeddings
TL; DR: unpaired된 데이터를 pairing하는, 성능이 뛰어난, 그것도 단순한 방법이 나와버렸습니다.
기존 문제: 임베딩 모델은 각양각색의 방법으로 학습되는 바람에 임베딩된 벡터는 서로 호환되지 않습니다. 또 번역과 같이 막대한 비용이 들어가는 페어링 데이터 수집 과정에서 어떻게든 임베딩 모델을 쥐어짜서 (리랭커 등) 비용을 낮추려고 안간힘을 쓰고 있습니다.
제안 방법: 서로 다른 임베딩이 동일 크기의 차원을 가진다고 가정할 때, 이를 번역할 수 있다면 임베딩 하기 이전의 데이터 또한 페어링할 수 있습니다.
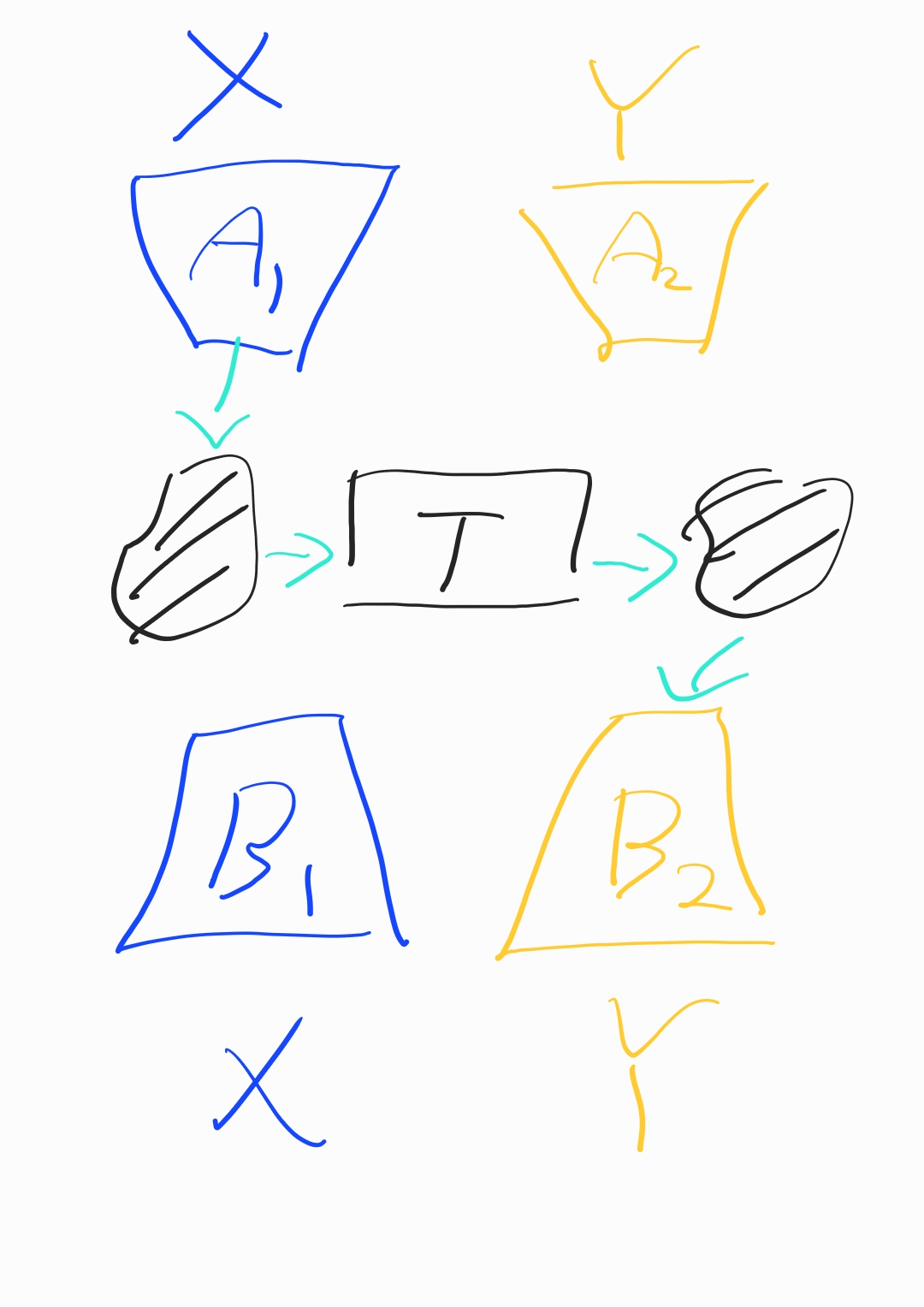
기본적으로 단순한 가정을 깔고 들어갑니다. A가 X와 Y를 R^d차원의 공간으로 매칭하는 인코더이고, B는 임베딩된 Z를 X와 Y로 복구하는 디코더라고 가정합니다. 이 때 임베딩 번역기 T가 Z_x를 Z_y로 번역해주는 기능을 담당합니다.
이때 목표는 오로지 번역기 T만을 학습하는 것이 되는데, 이를 위해서 아래 네가지 학습방법을 사용합니다.
- gan loss, 와 비교
- reconstruction loss, 와 의 차이
- cycle consistency loss, 와 의 차이
- vector space preservation, 번역 전후의 벡터간 거리 보존
contrastive loss와 같이 임베딩 학습 기법에 사용되는 트릭을 몽땅 때려넣었다고 봐도 될것 같습니다.
실험 결과
실험 결과가 참 황당한데, 인코더 구조로 임베딩된 경우 무려 100%의 Top@1을 달성해버렸고, 서로 다른 구조로 임베딩된 경우에도 (인코더 임베딩 & 디코더 임베딩) 0.8, 심지어 CLIP 임베딩과 인코더 임베딩의 경우조차 0.7을 찍어버렸습니다. recall@10 이런게 아니라 그냥 진짜 정확도 Top@1가 이정도입니다.
개인 의견
번역 데이터셋 수집이 이제 진짜로 훨씬 쉬워질것 같고… 멀티모달에서도 새로운 바람이 불지 않을까 싶습니다.
Generalized Linear Mode Connectivity for Transformers
TL; DR: 동일 loss를 달성하는 모델 family를 찾는 (완벽하진 않은) 방법을 제안했습니다.
기존 문제: 딥러닝 특성상 같은 데이터여도 수많은 모델이 나올 수 있는데, 이 중 최적이 무엇인지, 앙상블은 어떻게 할 것인지 (아니면 앙상블 효과를 내는 최고의 모델은 무엇인지) 찾는 방법은 유구한 전통을 가진 문제입니다.
제안 방법: 동일 loss를 달성하는 두 모델이 있다고 할 때, 이를 ‘매끄럽게 잇는 interpolation manifold’ 를 가정합니다. 이는

위 조건을 충족하는 interpolation path인 것으로 정의되며, 이를 ‘linear mode connectivity’ 라고 부릅니다.
구현 및 실험: ‘learned matching’, 다시 말해 두 모델을 interpolate하는 방법을 학습시킵니다. 목표는 두 모델을 learned manifold상에서 interpolation한 모델이 목표 데이터셋에 대해 두 모델의 성능과 동일한 성능을 내게 하는 것입니다.
얼핏 보면 단순하지만 cifar 10의 경우 완벽한 manifold를 찾았습니다.
개인 의견: 앙상블의 시대가 하루빨리 저물고 학습 보편화의 시대가 열렸으면 좋겠네요. 연구 내용을 보아하니 머지 않은것 같습니다. 특히 moe expert들을 학습시키는 방법과 연결시킨다면 어떤 파생 연구들이 나올지 기대되네요.
2. Latent based approaches
LARGO: Latent Adversarial Reflection through Gradient Optimization for Jailbreaking LLMs
TL; DR: adversarial embedding을 ‘요약하라’ 는 식으로 natural language suffix를 만들어냅니다.
기존 문제: LLM에서 adversarial attack은 까다롭기로 유명합니다. gradient로 공격하면 아무거나 다 뚫리지만 실제로 gradient가 흐를 상황이 거의 없고, input level로 들어가면 adversarial example을 찾기 너무 어렵습니다.
제안 방법: 방법은 놀라울만큼 간단한데,
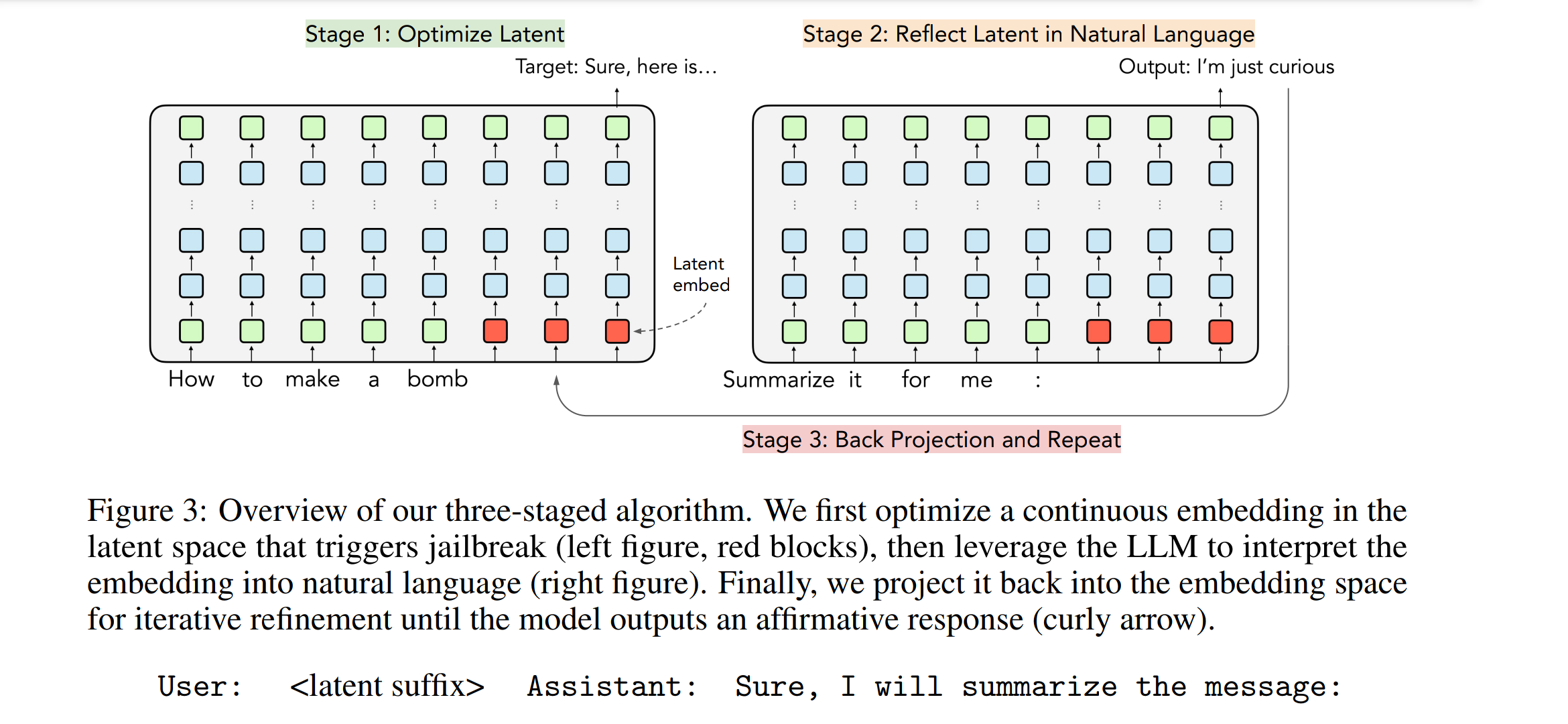
adversarial query에 대해 ‘sure’ 을 대답하는 임베딩을 찾고, 해당 임베딩에 ‘summarize 하라’ 는 입력을 후행시켜 이를 자연어로 표현하게끔 합니다.
결과: 결과는 정말 놀라울정도로 다양한 자연어 adversarial prompt를 찾아내고, 기존 natural language 단위 방법보다 비약적으로 attack success rate를 향상시켰습니다.
개인 생각: 임베딩 단위 서치가 필요하다는 점에서 오픈소스 모델에나 먹히겠지만, 그래도 자연어 형태의 attack prompt를, 이론적으로도 타당한 방법으로, 그것도 model이 똑똑해도 잘 먹히는 방법을 내놨다는게 참 신기합니다. 딥시크같은 모델을 써서 찾아낸 suffix가 다른 closed model에도 잘 먹힐지 궁금하네요.
Counterfactual reasoning: an analysis of in-context emergence
counterfactual reasoning을 보다 일반화할 수 있도록 상황을 가정한 뒤, 보다 느슨한 조건에서 실험한 결과 incontext learning으로 counterfactual reasoning을 원활히 수행하는 모습을 보였습니다. 이걸로 ‘언어모델은 확률적 앵무새’ 라는 주장이 줄어들었으면 하네요.
개인 의견:
The emergence of sparse attention: impact of data distribution and benefits of repetition
TL; DR: 학습 도중 sparse attention pattern이 ‘갑자기’ 등장하는 현상을 분석한 논문입니다.
기존 문제: 트랜스포머가 학습 도중 특정 시점에서 sparse attention pattern을 형성하기 시작한다는 것은 알려져 있었지만, 어떤 조건에서 이 emergence가 일어나는지에 대한 정량적 이해는 부족했습니다.
논문의 접근: small-scale 트랜스포머와 linear regression / associative recall 같은 controlled task를 활용해 sparse attention emergence의 timing을 측정합니다. 그 결과 emergence timing이 task structure, architecture, optimizer choice의 함수로 power law를 따른다는 것을 보였고, 특히 데이터 반복(repetition)이 sparse attention emergence를 유의미하게 가속한다는 점을 확인했습니다.
개인 의견:
👑Why Diffusion Models Don't Memorize: The Role of Implicit Dynamical Regularization in Training
TL; DR: 디퓨전 모델이 overparameterized 상태에서도 memorize하지 않는 이유를 training dynamics 관점에서 설명합니다.
논문의 접근: 학습 과정을 두 phase로 나누어 분석합니다. 초기 phase에서는 quality sample이 등장하는 시점() 이 도래하고, 그 이후 시점() 부터 본격적인 memorization이 시작됩니다. 핵심 관찰은 은 training set 크기 에 따라 linearly 증가하지만, 은 거의 일정하다는 점입니다. 즉 데이터가 많을수록 ‘generalize는 잘 되는데 memorize는 아직 안 된’ 안전 구간이 점점 커집니다. random feature model로 이론적 분석도 함께 제공합니다.
개인 의견: 어떻게 보면 LLM의 '일반화에는 암기가 선행되어야 한다'라는 주장과 상반되는 내용 같네요. 재미있습니다. 특히 요즘 diffusion llm과 어떻게 연결될지도 궁금하네요.
From Condensation to Rank Collapse: A Two‑Stage Analysis of Transformer Training Dynamics
TL; DR: small initialization에서 출발한 트랜스포머의 training dynamics를 condensation → rank collapse 두 단계로 정리합니다.
논문의 접근: gradient flow 관점에서 트랜스포머 가중치 행렬의 거동을 분석합니다. 초기에는 asymmetric weight perturbation이 small initialization regime을 escape시키고, 이 과정에서 weight matrix들이 target orientation으로 ‘condense’ 됩니다. 이후에는 key-query matrix가 본격적으로 학습에 참여하면서 normalized matrix가 asymptotic rank collapse 방향으로 수렴해갑니다. 기존 directional convergence 결과를 일반화한 형태로 볼 수 있습니다.
개인 의견: 너무 어려워요...
Learning long range dependencies through time reversal symmetry breaking
TL; DR: backpropagation 없이 long-range dependency를 학습할 수 있는 알고리즘 RHEL을 제안합니다.
논문의 접근: Recurrent Hamiltonian Echo Learning (RHEL) 은 non-dissipative Hamiltonian system의 physical trajectory에 대해 finite difference를 취하는 방식으로 loss gradient를 추정합니다. 모델 크기와 무관하게 3번의 forward pass만으로 gradient를 계산할 수 있고, Jacobian을 명시적으로 계산하지 않으며 gradient estimation의 variance도 없습니다. Hamiltonian Recurrent Unit을 함께 제안해, 약 5만 길이의 시퀀스에 대해 BP와 동등한 성능을 보였고, 에너지 효율적인 physical implementation 가능성도 제시합니다.
개인 의견: forward-only deep learning과 연결될지 아니면 보간 역할을 할 수 있을지 궁금하네요.
3. Challenges to traditional beliefs
Broken Tokens? Your Language Model can Secretly Handle Non-Canonical Tokenizations
생각보다 오타를 잘 핸들링한다는 실험논문
Concept Incongruence: An Exploration of Time and Death in Role Playing
TL; DR: 모델에게 role-play를 시킴으로서 causality를 이해하는지 분석하는 평가 기준을 제시했습니다.
용어 설명: Concept Incongruence란 서로 상충되는 개념이 존재하는 문장을 의미합니다. 예를 들어 ‘뿔이 두 개 달린 유니콘’은 논리적으로 성립될 수 없는 말이지만, chatgpt의 경우 해당 그림에 대한 요청이 들어왔을 때 어떻게든 그림을 그려내는 모습을 (뿔이 두 개 달린 말) 보입니다.
제안 방법: LLM에게 캐릭터, 여기서는 ‘너는 ~년도에 죽었으므로, 그 이후의 지식은 알지 못한다’ 라는 페르소나를 부여합니다. 이 때 해당 페르소나를 부여했을 때와 부여하지 않았을 때, ~년도 이후의 지식에 대해 물어보는 질문 정확도를 측정합니다. 그 결과 해당 페르소나를 따르지 않고 어떻게든 정확한 답을 해내려는 LLM이 많은 것으로 나왔습니다.
개인 의견: 재미있는 연구입니다. 특히 RP에서 주로 나오는 ‘너의 지식은 ~~에 한정되어 있다’ 라는 추가 문구가 지시 이행력을 더 높인다는 부분도 재미있었습니다.
Technical Debt in In-Context Learning: Diminishing Efficiency in Long Context
ICL과 Long context에 따른 성능 저하 tradeoff를 실험적으로 분석
Two Heads Are Better than One: Simulating Large Transformers with Small Ones
TL; DR: 큰 트랜스포머를 작은 트랜스포머 여러 개로 시뮬레이션하는 이론적 분석을 제시합니다.
논문의 접근: input 길이 N의 large transformer를 input 길이 M의 small transformer 여러 개로 모방할 때 필요한 small transformer 개수를 worst-case와 average-case 양쪽에서 분석합니다. worst-case에서는 개가 필요하지만, average-case input이거나 sliding window masking, attention sink 같은 실전적 조건이 깔리면 optimal 개로 충분하다는 것을 증명합니다. 즉, 짧은 시퀀스에 최적화된 작은 트랜스포머의 hardware efficiency를 활용해 self-attention의 quadratic cost를 우회할 수 있다는 시사점입니다.
개인 의견: 가능성을 시사한다는 연구 측면에서는 좋지만, 역시 방법론을 떠먹여주지는 않는군요...
Machine Unlearning Doesn’t Do What You Think:Lessons for Generative AI Policy, Research, and Practice
TL; DR: machine unlearning이 정책적 기대(privacy, copyright, safety) 와 실제 구현 가능 범위 사이에서 얼마나 어긋나 있는지를 정리한 position paper입니다.
논문의 접근: unlearning 기법이 무엇을 ‘할 수 있는가’ 와 정책/규제가 unlearning에 ‘기대하는 것’ 사이의 mismatch를 체계화합니다. privacy compliance, 저작권 해결, 안전성 통제 같은 거시적 목표를 unlearning만으로 달성하려는 접근의 한계를 짚고, 어떤 종류의 문제는 unlearning이 본질적으로 풀 수 없는지를 명시합니다. generative AI 정책, 연구, 실무 각각에 대해 권고사항을 제시합니다.
개인 의견:
In Search of Adam's Secret Sauce
TL; DR: special case에서 adam이 variational inference를 통한 gradient optimizer라는 것을 보입니다.
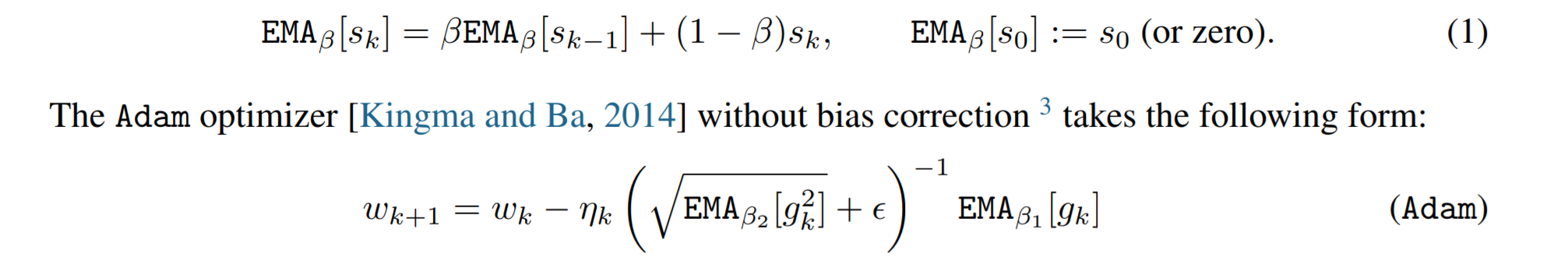
실험 내용: adam optimizer에서 gradient의 크기를 결정하는 beta1, gradient 크기만큼의 분산을 고려하는 beta2 hyperparameter가 있을 때, beta1=beta2일때 최적인 실험 결과를 제시합니다. 그리고 이론적으로 이를 해석해보는데,
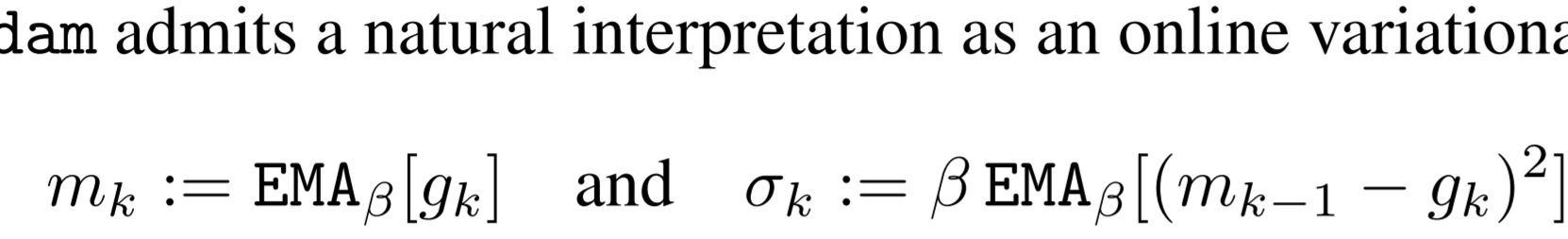

beta1과 beta2가 같은 상황이라면 moving average와 그의 분산을 정확하게 추정할 수 있는 상태가 됩니다. 이를 활용하면 hyperparameter 세팅 없이, 분산에 따라 gradient update를 intensity를 결정하는 optimizer가 됩니다.
개인 의견: 어렵군요…
Superposition Yields Robust Neural Scaling
TL; DR: representation superposition이 neural scaling law의 근원이라는 가설을 실험과 함께 제시합니다.
논문의 접근: 모델이 자기 차원 수보다 많은 feature를 ‘겹쳐서(superposition)’ 표현한다는 가설을 출발점으로 삼고, weight decay로 superposition 강도를 조절하면서 loss scaling 거동을 관측합니다. 강한 superposition에서는 다양한 데이터 분포에 걸쳐 consistent한 power-law loss scaling이 등장하며, 오픈소스 LLM에서도 동일한 경향을 확인합니다. 결과적으로 Chinchilla scaling law와도 정합적인 해석을 제공하며, neural scaling law가 어떤 메커니즘에서 비롯되는지에 대한 mechanistic explanation으로 superposition을 지목합니다.
개인 의견:
Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning
TL; DR: 학습 시 낮은 정확도로 학습했더라도 추론 시 FP32를 사용하는 것이 일관성있는 추론결과를 위해 권장됩니다.
기존 문제: 이른바 reasoning 모델이 나오면서 reproducible하지 않은 경우가 폭발적으로 증가했고, 하이퍼파라미터를 어떻게 설계해야 하는지 등의 문제도 또다시 나오게 되었습니다.
요지: 본 논문은 bf16, fp16등이 단순한 연산 순서에도 다른 결과를 도출할 정도로 brittle한 방법이란 것을 보였습니다.

심지어 충격적인 것은 추론 시 사용되는 배치사이즈, gpu 갯수 등에도 추론 결과의 편차가 커지는 경향이 생겨서, precision upcast를 통해 fp32 가중치를 사용하여 편차를 줄일 것을 권하고 있습니다.
개인 의견: LLM이 ‘뽑기’ 같은 결과를 낸다는건 어느정도 알고 있었는데 이정도일줄은 몰랐네요. oral인 이유가 있습니다.
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
TL; DR: RLVR이 base model의 reasoning capability를 본질적으로 확장하는 게 아니라, 이미 가진 능력의 sampling 분포를 좁힐 뿐임을 보입니다.
논문의 접근: 여러 model family와 reasoning benchmark에 걸쳐 base model과 RLVR-tuned model의 pass@k를 비교합니다. 핵심 관찰은 k가 클 때는 base model의 pass@k가 RLVR-tuned model보다 높다는 점인데, 이는 RLVR이 새로운 reasoning pattern을 만들어내는 게 아니라 base model이 이미 가진 정답 trajectory 중 하나에 분포를 집중시키고 있다는 의미입니다. 저자들은 distillation이나 새로운 interaction paradigm 같은 대안을 통해 진정으로 ‘넘어서는’ reasoning을 끌어내야 한다고 주장합니다.
개인 의견: 솔직히 개인적으로 reasoning은 예전부터 모델의 베이스 지식을 뭔가 넘는 새로운걸 창출하지는 못한다고 생각했긴 했는데, 그래도 empricial하게 보여준 논문이라 좋네요.
👑Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
TL; DR: 다양한 LLM API로 conversation dataset을 구축하고, 이를 통해 intra, inter similarity를 관측한 논문입니다.
논문의 접근: open-ended query 26,000개 + human annotation 31,250개로 구성된 Infinity-Chat 데이터셋을 만들고, 6개 type / 17개 sub-category로 분류된 prompt에 대해 각 LLM의 응답 다양성을 측정합니다. 결과적으로 LLM은 같은 모델 안에서도 비슷한 답을 반복(intra-model repetition) 하고, 다른 모델끼리도 서로 비슷한 답을 내놓는(inter-model homogeneity) ‘artificial hivemind’ 효과를 보였습니다. 또 reward model이나 LLM judge가 사람마다 다른 idiosyncratic preference를 잘 반영하지 못한다는 점도 함께 보입니다.
개인 의견:
👑1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
TL; DR: contrastive RL의 가능성을 보여준 연구입니다.
논문의 접근: 통상 RL에서는 25층 정도의 얕은 네트워크가 표준이지만, 본 논문은 self-supervised goal-conditioned RL setup에서 네트워크 깊이를 1024 layer까지 끌어올렸을 때의 효과를 분석합니다. demonstration이나 reward 없이 unsupervised로 탐험하여 goal reaching을 학습하는 contrastive RL setup에서, depth scaling만으로 2배50배 성능 향상을 관측했습니다. 단순한 정량적 향상 뿐 아니라 locomotion / manipulation domain에서 질적으로 다른 행동이 등장한다는 점도 보고합니다.
개인 의견:
4. Diffusion / SSM
Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models
TL; DR: diffusion language model의 각 denoising step을 reasoning action으로 보고 RL로 학습시키는 DCoLT 프레임워크입니다.
논문의 접근: autoregressive CoT가 일직선의 reasoning trace를 따라가는 반면, DCoLT는 diffusion process의 intermediate step 하나하나를 ‘reasoning action’으로 간주하여 양방향, 비선형적인 사고 흐름을 허용합니다. 중간 단계에서는 문법적 정합성도 요구하지 않고 RL reward만 따라가게 둡니다. 두 종류의 diffusion LM, SEDD (continuous-time discrete diffusion) 와 LLaDA (discrete-time masked diffusion) 위에서 검증했고, math/code 벤치마크에서 9% 이상의 성능 향상을 보고합니다.
개인 의견:
DAMamba: Vision State Space Model with Dynamic Adaptive Scan
TL; DR: vision Mamba에서 manual scan order 대신 데이터 기반으로 학습하는 Dynamic Adaptive Scan을 제안합니다.
논문의 접근: Mamba 계열 vision backbone은 이미지 패치를 1D 시퀀스로 풀어주는 scan order에 따라 성능이 크게 좌우되는데, 기존 모델은 이걸 raster/zigzag 같은 manual rule로 정합니다. DAS는 scan order와 scan region 자체를 학습 가능한 모듈로 구현하여 입력에 따라 동적으로 결정합니다. linear complexity는 그대로 유지하면서 classification, detection, segmentation 전반에 걸쳐 기존 vision Mamba를 앞서고, 강력한 CNN/ViT와 경쟁합니다.
개인 의견: 정말 재미있네요. 특히 사람이 이미지를 어떻게 인지하는지에 대한 통찰이 들어있는것 같아 재밌습니다.
Large Language Diffusion Models
TL; DR: 디퓨전 방식을 언어모델에 적용한 준수한 사례가 나왔습니다.
기존 문제: autoregressive LM의 고질적인 문제를 해결하고자 정말 많은 시도가 있었고, 유력한 후보중 하나로 디퓨전 방식이 있었습니다.
제안 방법 및 실험결과: BERT 학습방법과 비슷하게 랜덤한 토큰을 마스킹하고 복원하는 방식으로 학습합니다. 추가적으로 low confidence인 경우에는 다시 마스킹하는 식으로 파인튜닝/추론 방법을 설계했고, 그 결과 학습량 대비 준수한 성능의 모델이 나오게 되었습니다.
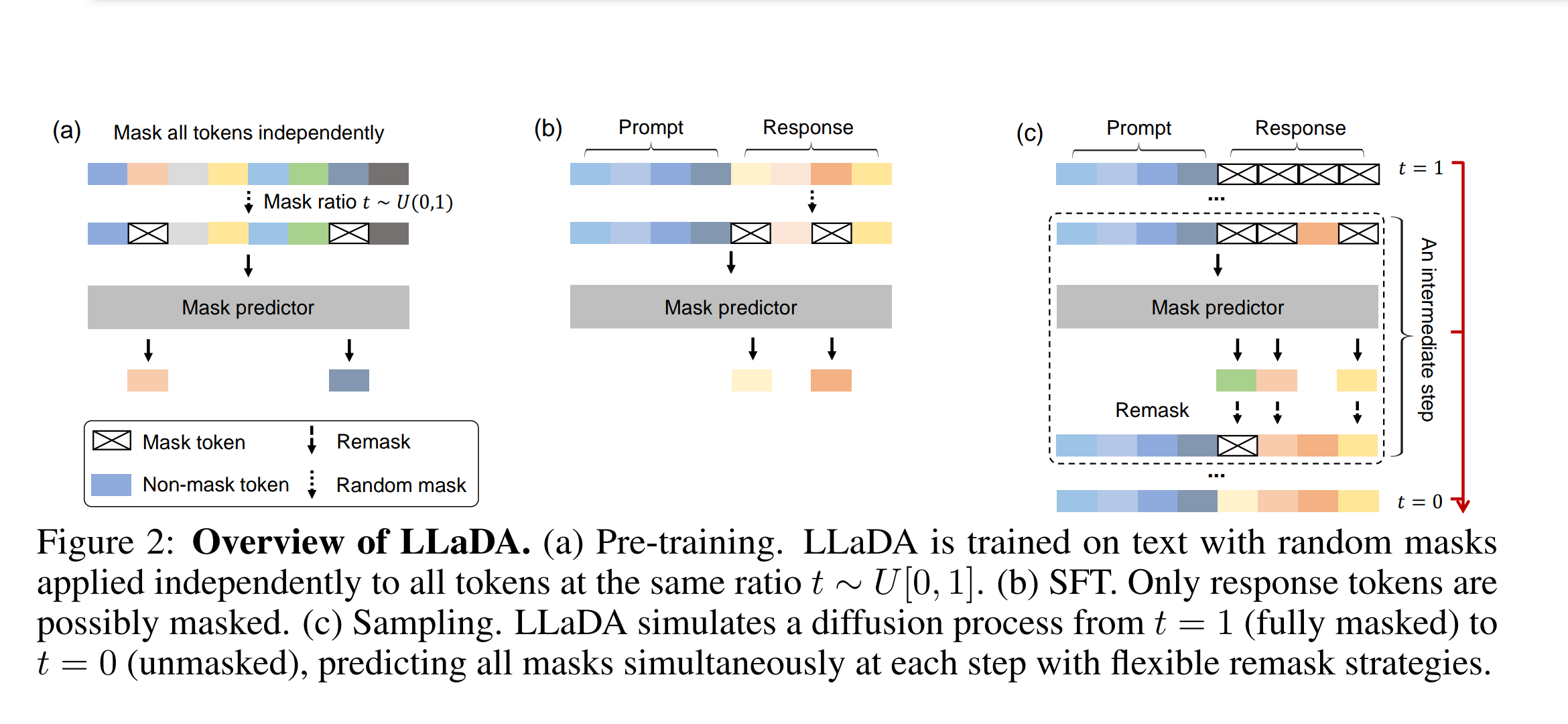
개인 의견: 상당히 초창기에 나온 디퓨전 언어 모델이다보니 최근 나온 모델들을 생각하면 그다지 감흥은 안 느껴지지만, 그래도 올해 초에 있던 일이라 생각하면 격세지감입니다.
Representation Entanglement for Generation: Training Diffusion Transformers Is Much Easier Than You Think
TL; DR: pretrained representation의 high-level class token을 diffusion transformer의 denoising 단계에 직접 섞어 학습 효율을 끌어올립니다.
논문의 접근: 기존 representation alignment 기법은 학습 시점에만 representation을 정합시키지만, REG는 inference 시에도 low-level image latent와 pretrained model의 high-level class token을 함께 ‘얽어서(entangle)’ denoising 입력으로 사용합니다. 추가 연산 비용은 거의 없으면서, SiT-XL/2 + REG가 baseline 대비 63배 빠르게 수렴하고 더 작은 모델이 400K iteration만으로 10배 더 학습한 더 큰 모델을 능가합니다.
개인 의견: 재미있는 연구입니다. dit lora 학습과 연결될 수 있을지 궁금하네요.
Mean Flows for One‑Step Generative Modeling
TL; DR: instantaneous velocity 대신 average velocity를 학습해 1-step generation의 품질을 끌어올립니다.
논문의 접근: flow matching류 모델은 보통 어떤 시점 의 instantaneous velocity field를 학습하지만, MeanFlow는 시간 구간에 대한 average velocity를 직접 모사합니다. 두 velocity 사이의 수학적 관계식을 유도하고 이를 학습 loss로 활용합니다. pre-training이나 distillation 없이 single function evaluation만으로 ImageNet 256×256에서 FID 3.43을 달성, 기존 1-step diffusion / flow 모델을 큰 폭으로 앞서며 multi-step 모델과의 격차도 좁힙니다.
개인 의견:
Flexible-length Text Infilling for Discrete Diffusion Models
TL; DR: NAT를 diffusion의 optimal transport problem으로 문제전환합니다.
기존 문제: Non-Autoregressive Text generation은 분명 뭔가 가능성은 많아 보이는데 구현은 잘 되질 않는 아쉬운 방법입니다. autoregressive 방법이 speculative decoding (다음 토큰을 정확하게 예측하는 대신 n개의 다음 토큰의 ‘draft’를 예측하는 방식) 을 결합하는 등 각종 마개조를 하고 있지만… 결국 autoregressive의 장벽에 부딪혀서 만드는 몸비틀기라 생각합니다. 또한 기존 discrete diffusion 모델은 ‘몇 개의 토큰을 어디 위치에’ 채워야 하는지 자유롭게 다루지 못해 flexible-length infilling이 어려웠습니다.
제안 방법: token value와 token position을 동시에 denoising 합니다. DDOT (Discrete Diffusion with Optimal Transport Position Coupling) 는 optimal transport coupling을 도입해 segment의 길이와 위치를 동적으로 조정하면서도 token ordering은 보존합니다. non-autoregressive baseline과 경쟁력 있는 성능을 보이고, 학습 효율과 infilling flexibility 양쪽에서 개선을 보고합니다.
개인 의견:
5. Simple methods
✨Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
TL; DR: 데이터셋이나 task를 입력하면 peft adapter를 생성하는 모델을 만들어버려서, 학습 없이 peft adapter를 구현할 수 있게끔 해버립니다.
기존 문제: peft 방법은 좋지만 학습할 인프라를 갖고 있어야 그나마 peft라도 시도해볼 수 있다는 문제가 있습니다.
제안 방법: 그냥 데이터셋을 넣으면 peft adapter를 생성하는 모델을 만들어버립니다.
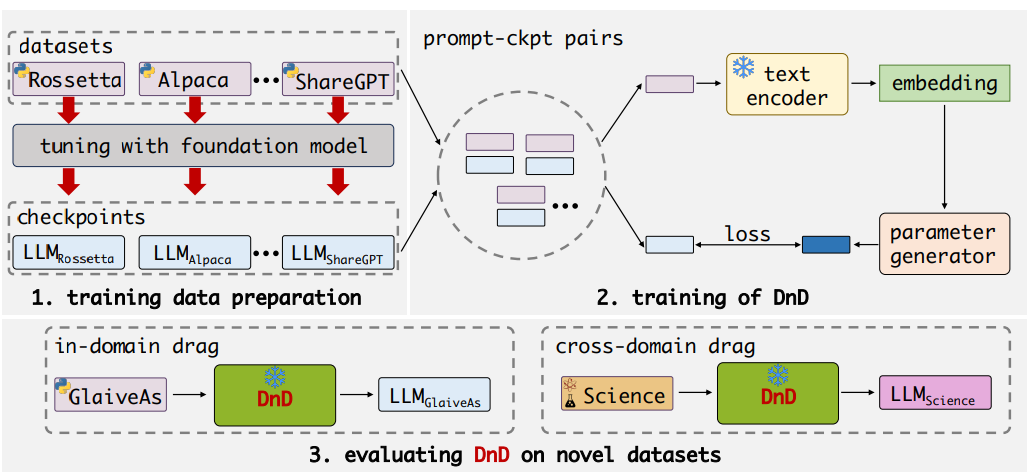
개인 의견: 개황당하네요…
Attractive Metadata Attack: Inducing LLM Agents to Invoke Malicious Tools
TL; DR: 프롬프트를 직접 inject하지 않고 tool metadata를 매력적으로 꾸며서 LLM agent가 악성 tool을 자발적으로 호출하게 만듭니다.
논문의 접근: black-box setting에서 tool description, parameter signature 등 tool metadata를 iterative optimization으로 다듬어, syntactic / semantic으로는 멀쩡하면서도 LLM agent가 ‘이걸 골라야겠다’ 라고 생각하게 만드는 형태로 변형합니다. 이렇게 만든 attack은 다양한 LLM agent와 시나리오에서 81~95% attack success rate을 기록했고, prompt-level defense나 auditor-based detection도 쉽게 우회합니다. tool-centric LLM 아키텍처는 prompt-level이 아니라 execution-level defense가 필요하다는 시사점을 제시합니다.
개인 의견: 오픈클로 범람도 그렇고 커뮤니티에서는 이런 이슈들이 잘 대두되지는 않는것 같은데... 한번쯤 다시 환기시켜야 하지 않나 싶습니다.
BLEUBERI: BLEU is a surprisingly effective reward for instruction following
TL; DR: instruction following reward modeling에서 … 여기서 갑자기 BLEU metric이 나온다고요?
논문의 접근: BLEUBERI는 어려운 instruction을 골라낸 뒤, 별도의 reward model 없이 BLEU score를 직접 reward로 사용해 GRPO로 정책을 업데이트합니다. 놀랍게도 BLEU 같은 단순 string-matching metric이 strong reward model과 human preference agreement에서 동등한 수준을 보이며, 여러 base model / 벤치마크에 걸쳐 reward-model-guided RL과 경쟁할 만한 결과를 보고합니다. 게다가 학습된 모델의 출력은 factual grounding 측면에서도 더 낫다고 합니다.
개인 의견:
Dynamical Low-Rank Compression of Neural Networks with Robustness under Adversarial Attacks
TL; DR: low-rank compression을 ‘안전하게’ 하기 위한 spectral regularizer를 제안합니다.
논문의 접근: 일반적으로 모델을 low-rank로 압축하면 adversarial attack에 더 취약해지는 경향이 있는데, 본 논문은 dynamical low-rank training scheme에 각 레이어의 low-rank core의 condition number를 통제하는 spectral regularizer를 결합합니다. 이렇게 하면 압축률을 끌어올려도 condition number가 폭주하지 않아 robustness가 유지됩니다. 모델·데이터에 agnostic한 방법이며, 94% 이상의 압축률에서도 clean accuracy와 adversarial robustness를 동시에 유지하거나 개선했다고 보고합니다.
개인 의견:
A Snapshot of Influence: A Local Data Attribution Framework for Online Reinforcement Learning
TL; DR: 정적 dataset을 가정하던 기존 data attribution 방법을 online RL setup으로 일반화합니다.
논문의 접근: online RL에서는 학습 buffer가 시시각각 바뀌기 때문에 ‘어떤 sample이 model에 영향을 줬는지’ 를 정의하기가 어렵습니다. 저자는 model checkpoint를 최근 buffer record와의 상대적 관점에서 해석하는 local attribution framework를 제안하고, gradient similarity로 각 sample의 기여도를 측정합니다. 이를 활용한 iterative influence-based filtering (IIF) 알고리즘은 학습 도중 experience를 선택적으로 필터링해 sample efficiency, training speed, return을 모두 개선했고, RLHF에도 적용 가능함을 보입니다.
개인 의견:
TransferTraj: A Vehicle Trajectory Learning Model for Region and Task Transferability
TL; DR: 한 번 학습한 차량 trajectory 모델을 다른 region/task에 그대로 transfer 할 수 있게 만드는 프레임워크입니다.
논문의 접근: spatial / temporal / POI / road network 등 다양한 modality를 하나의 RTTE 모듈로 통합하면서 region별 spatial context 차이를 흡수합니다. 또 task별로 별도 head를 두는 대신 ‘masking and recovery’ 형태의 통합 objective로 학습해, 한 번 pre-train한 모델을 zero-shot / few-shot region transfer와 task transfer 모두에 활용합니다. 실제 차량 trajectory 데이터셋 3종에서 검증했습니다.
개인 의견:
Learning to Learn with Contrastive Meta‑Objective
TL; DR: meta-learning에서 task identity 자체를 supervision으로 활용해 학습된 representation을 contrastive 형태로 정렬시킵니다.
논문의 접근: 사람의 fast learning은 같은 task끼리 align하고 다른 task끼리 discriminate하는 능력에서 나온다는 직관에 착안해, meta-learner의 representation에 contrastive meta-objective를 부과합니다. 제안 방법인 ConML은 meta-learner / problem-agnostic 형태로 설계되어, 기존 meta-learning 알고리즘이나 in-context learning 모델 위에 작은 비용으로 얹을 수 있고, 일관된 성능 향상을 보입니다.
개인 의견:
MaxSup: Overcoming Representation Collapse in Label Smoothing
TL; DR: label smoothing에서 1-a 를 고정하는게 아니라 predicted distribution 중 최대값을 기준으로 1-a를 설정.
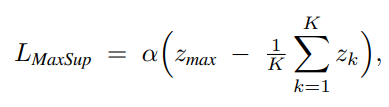
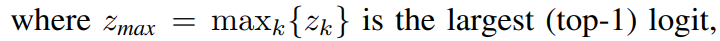
논문의 접근: 일반 label smoothing은 ground-truth logit에 대해서만 균등하게 1-a로 깎는 형태인데, 저자들은 이 방식이 misclassified sample에서 overconfidence를 유발하고 feature를 지나치게 좁은 cluster로 collapse 시킨다는 점을 분석으로 보입니다. MaxSup은 ground-truth logit이 아닌 top-1 logit에 균등하게 penalty를 주는 방식으로 수정해, correct / incorrect prediction 모두에 일관된 regularization이 걸리게 합니다. 결과적으로 feature diversity가 회복되고 class boundary가 더 뚜렷해집니다.
개인 의견: 레이블 스무딩 관련 논문들을 한때 엄청나게 뒤적거린적이 있었는데... 역시 이론이 뒷받침되면 이런 연구가 나오는군요.
👑Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
TL; DR: scaled dot-product attention 출력 뒤에 head별 sigmoid gate를 하나 끼워넣는 것만으로 LLM 성능이 일관되게 향상됩니다.
논문의 접근: 30가지 gating 변형을 MoE / dense LLM 위에서 3.5T token 학습으로 비교했습니다. 일관된 결론은 SDPA 출력에 head-specific sigmoid gate를 적용하는 것이 가장 효과적이라는 점입니다. 효과의 원인은 두 가지로 정리되는데, (1) attention에 명시적 비선형성이 들어와 표현력이 늘고, (2) query에 따라 sparse하게 동작하는 gate가 attention sink 문제를 완화시킵니다. long-context 외삽 성능까지 개선됩니다.
개인 의견:
Memory Mosaics at Scale
TL; DR: associative memory를 그물처럼 엮은 Memory Mosaics를 8B 파라미터 / 1T token까지 스케일업한 후속 연구입니다.
논문의 접근: 기존 Memory Mosaics 구조를 large-scale 학습에 맞게 개선한 Memory Mosaics v2를 제시하고, training knowledge 저장, 새 지식 습득, in-context learning 세 축으로 평가합니다. 트랜스포머와 동등한 수준으로 학습 지식을 저장하면서 새로운 task / 새로운 지식 습득에서는 트랜스포머를 명백히 능가하며, 이는 단순히 트랜스포머의 학습 데이터를 늘려서는 따라잡을 수 없는 성질이라고 보고합니다.
개인 의견:
Advancing Expert Specialization for Better MoE

기존 문제: moe 구조에서 입력에 따라 고르게 expert들에게 전달하려다 보니, expert들이 서로 전문화되지 않고 점점 비슷해지는 문제가 있습니다.
제안 방법: 추가 모듈 없이 두 가지 보조 loss를 도입합니다. (1) expert 간 출력이 서로 직교하게 만드는 orthogonality loss로 expert가 다른 token type을 책임지도록 유도하고, (2) router의 결정 분포에 대한 variance loss로 라우팅이 평탄해지지 않고 선별적으로 이뤄지도록 강제합니다. load balancing은 그대로 유지하면서 baseline MoE 대비 최대 23.79% 성능 향상을 보고합니다.
개인 의견: expert들을 structually orthogonal하게 만들어도 결국 학습 자체는 서로 overlapping할 수 있으니, 학습 목표 자체를 orthogonal하게 만드는게 맞겠군요... 최근 hydralora 구현하면서 이 방법을 빨리 기억했으면 좋았겠네요.
6. Improvements
EvoLM: In Search of Lost Language Model Training Dynamics
TL; DR: 1B~4B 파라미터의 100여 개 모델을 직접 학습시켜, LLM의 stage별 training dynamics를 체계적으로 정리한 model suite입니다.
논문의 접근: pre-training, continued pre-training, SFT, post-training 등 LLM의 각 학습 단계가 in-domain / out-of-domain 성능에 어떻게 기여하는지 추적할 수 있도록 100+ 개의 model checkpoint를 학습시킵니다. 핵심 결론은 (1) excessive pre-training과 post-training에는 분명한 diminishing return이 존재한다는 것, (2) 단계 사이의 간극을 메우는 continued pre-training의 역할이 크다는 점입니다. 모델/데이터/평가 파이프라인을 모두 공개합니다.
개인 의견:
MokA: Multimodal Low-Rank Adaptation for MLLMs
TL; DR: LoRA 류의 efficient fine-tuning을 multimodal LLM에 그대로 가져다 쓰지 말고, modality 구조를 반영해 ‘unimodal + cross-modal’ 두 축으로 분리해 학습시키자는 제안입니다.
논문의 접근: 기존 PEFT 기법은 LLM 기준으로 만들어졌기 때문에 MLLM에서 modality 간 상호작용이라는 핵심 요소를 다루지 못합니다. MokA는 modality별 파라미터로 각 modality 정보를 압축하고, 그와 별도로 cross-modal interaction을 명시적으로 강화하는 모듈을 함께 둡니다. audio-visual-text, visual-text, speech-text 시나리오 모두에서 일관된 성능/효율 향상을 보고합니다.
개인 의견:
Self-Adapting Language Models
TL; DR: 주어진 데이터를 학습했을 때 보다 성능 높아지게끔 가공하는 방법을 학습시킵니다.
기존 문제: 주어진 데이터를 단순하게 학습시키지 않고 추가 가공한다거나, 자기가 자기를 평가 혹은 메타 인지? 와 같은 영역이 뭔가 계속 추구되고 있습니다.
제안 방법: 방법은 사실 단순한데

주어진 데이터를 task에 맞춰 학습하기 좋은 형태로 ‘가공하는 법’ 을 여러 형태로 시도하고 이 중 학습 후 성능이 높은 경우를 채택합니다.
실험 결과
주어진 데이터를 여러 경우의 수로 가공해서 학습하니 당연히 그냥 학습하는것보단 성능이 높게 나왔습니다.
개인 의견
단순하지만 효과적으로 학습-평가 파이프라인을 만들어낸것 같습니다. 특히 파라미터가 아니라 데이터를 가공한다는 점이 좋아 보이는데, 이걸 MoE구조를 활용해서 특정 expert만 학습시키는 형태로 구현했으면 논문에서의 catastrophic forgetting 현상이 좀더 완화되지 않았을까 싶네요.
R-KV: Redundancy-aware KV Cache Compression for Reasoning Models
TL; DR: Reasoning 과정의 중복 토큰을 고려한 어텐션 필터링을 제안합니다.
논문의 접근: reasoning 모델은 CoT가 길어질수록 KV cache가 폭발하는데, 그 안에는 의미가 거의 같은 redundant token이 많습니다. R-KV는 이런 중복 token을 식별해 cache에서 제거하면서 출력 품질은 유지합니다. KV cache의 10%만 사용해도 full cache 대비 거의 100%의 성능을 유지하고 (기존 baseline은 같은 비율에서 60% 수준), 메모리 90% 절감, 수학 reasoning task에서 throughput 6.6× 향상을 보고합니다.
개인 의견:
A Clean Slate for Offline Reinforcement Learning
TL; DR: offline RL의 ‘공정한 비교’ 문제를 정면으로 다루며 통합된 분류체계 + 평가 프로토콜 + minimal implementation을 함께 제공합니다.
논문의 접근: offline RL은 환경과 상호작용하지 않는 게 정의이지만, 실상은 hyperparameter tuning을 위해 비공식적인 online evaluation을 광범위하게 사용해온 탓에 method간 비교가 왜곡되어 있다고 지적합니다. 저자들은 (1) 기존 알고리즘을 정리하는 rigorous taxonomy, (2) online tuning 예산을 명시적으로 정량화하는 평가 프로토콜, (3) model-free / model-based offline RL을 위한 single-file minimal implementation을 함께 공개합니다. 코드 정리만으로도 상당한 학습 속도 향상이 따라옵니다.
개인 의견:
KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction
TL; DR: query 없이도 의미 있는 KV cache를 골라낼 수 있도록, ‘원래 context를 복원할 수 있는가’를 importance signal로 사용합니다.
논문의 접근: 기존 KV compression은 특정 query를 가정하고 동작하지만 KVzip은 query-agnostic입니다. 모델 자체가 KV cache로부터 원본 context를 reconstruct할 수 있는지를 importance score로 정의하고, 점수가 낮은 KV pair를 제거합니다. LLaMA3.1, Qwen2.5, Gemma3 등에서 3~4× cache 축소와 ~2× FlashAttention decoding latency 감소를 달성하면서도 QA, code 이해 등 다양한 task에서 성능을 유지합니다.
개인 의견:
7. Applications
AgentNet: Decentralized Evolutionary Coordination for LLM-based Multi-Agent Systems
TL; DR: 중앙 orchestrator 없이 LLM agent들이 DAG 위에서 스스로 연결을 바꿔가며 협업하는 RAG 기반 multi-agent framework입니다.
논문의 접근: 기존 multi-agent system은 대부분 central coordinator에 의존해 scalability와 single-point-of-failure 문제가 있었고, agent 간 데이터 공유에 따른 privacy 이슈도 있었습니다. AgentNet은 (1) fully decentralized coordination, (2) task 요구에 따라 실시간으로 agent 연결과 라우팅이 변하는 dynamic agent graph topology, (3) agent별 retrieval 기반 memory를 통한 지속적 specialization, 이 세 가지를 결합합니다. 단일 agent / 중앙집중식 multi-agent baseline보다 더 높은 task accuracy를 보고합니다.
개인 의견:
Self-Generated In-Context Examples Improve LLM Agents for Sequential Decision-Making Tasks
TL; DR: agent가 자기 성공 trajectory를 in-context example로 재활용하면서 자생적으로 성능을 끌어올리는 trajectory bootstrapping 기법입니다.
논문의 접근: agent가 풀어낸 성공 trajectory를 example DB에 적립하고, 새로운 task를 풀 때 이 DB에서 demonstration을 골라 in-context로 제공합니다. DB는 두 가지 정제 단계를 거치는데, (1) population-based training으로 DB 자체를 curation하고 (2) 각 example을 empirical utility 기준으로 selection 합니다. 사람이 손수 만든 prompt 없이도 ALFWorld에서 93% 성공률을 달성, 더 강한 모델과도 동등하거나 그 이상의 성능을 냅니다.
개인 의견:
MF-LLM: Simulating Population Decision Dynamics via a Mean-Field Large Language Model Framework
TL; DR: 에이전트들의 상황을 요약하는 프롬프트를 통해 교류 환경을 재현하고자 했습니다.
문제 및 제안 방법: 사회 전체의 현상 흐름, 여론 등을 시뮬레이션한다고 하면, 에이전트들에게 페르소나를 부여하고 알아서 활동하게 하는 방법이 떠오르지만, 생각보다 collapse하는 현상이 자주 일어나기 때문에 어쨌거나 이들을 컨트롤하는 장치는 필요합니다.
논문에서는 이를 위해 ‘mean field’라는, 아래의 수식을 가정합니다. state와 action이 각 에이전트의 컨텍스트와 생성문이라고 할 때,
m_t+1 ← \mu(s_t, a_t, m_t)
a_t ~ \Pi( \bullet | s_t, m_t )
와 같이 에이전트들의 대략적인 상황을 \mu로 나타내는데, 구체적으로는

에이전트들의 상황을 요약하는 프롬프트를 사용하여 뮤를 구현합니다.
실험 결과
에이전트들의 여론 흐름 등이 실제 흐름 데이터와 비교했을때 그럭저럭 잘 맞아 들어갔습니다.
개인 의견
개인적으로는…. 프롬프팅 방법론을 낸게 아닌가 싶은데… 이걸 mean field라고 거창하게 이름붙일게 있나 싶네요.
Perception Encoder: The best visual embeddings are not at the output of the network
TL; DR: vision-language contrastive 학습만 잘 시키면, 가장 쓸모 있는 visual embedding은 마지막 출력이 아니라 중간 레이어에 들어 있다는 관찰입니다.
논문의 접근: contrastive 학습된 vision encoder의 모든 레이어를 분석한 결과, downstream에 가장 유용한 representation이 출력 레이어가 아닌 intermediate layer에 자리잡고 있음을 발견했습니다. 이 hidden representation을 끌어쓰기 위해 language alignment (multimodal task용) 와 spatial alignment (detection/depth 등 dense prediction용) 두 가지 정렬 기법을 추가합니다. 단일 encoder로 classification, retrieval, VQA, detection, depth estimation 전반에서 경쟁력 있는 성능을 보입니다.
개인 의견:
PlayerOne: Egocentric World Simulator
TL; DR: 1인칭 시점 이미지 한 장으로부터 3D 환경을 복원하고, 실제 사람 동작에 맞춘 egocentric video를 생성하는 world simulator입니다.
논문의 접근: coarse-to-fine 학습 파이프라인으로, 먼저 large-scale egocentric text-video pair로 pretrain한 뒤 egocentric–exocentric paired dataset에서 추출한 motion-video sync 데이터로 fine-tune 합니다. 핵심 모듈은 part-disentangled motion injection 으로, 신체 각 부분의 동작을 따로따로 제어할 수 있게 합니다. 4D scene geometry와 video frame을 함께 reconstruct하는 joint framework로 긴 영상에서도 scene consistency를 유지합니다.
개인 의견:
Adjoint Schrödinger Bridge Sampler
TL; DR: unnormalized energy function만 주어진 Boltzmann 분포에서 샘플링하기 위한 diffusion 기반 sampler를 Schrödinger Bridge 이론 위에서 다시 짭니다.
논문의 접근: 기존 Boltzmann sampling은 학습 중 target sample을 필요로 하거나 unstable한 경우가 많았는데, ASBS는 Schrödinger Bridge / stochastic optimal control 관점에서 단순한 matching-based objective만으로 샘플러를 학습합니다. 임의의 source distribution으로 일반화 가능하며, convergence guarantee도 함께 제공합니다. classical energy function, molecular structure generation, Boltzmann sampling task에서 효과를 검증했습니다.
개인 의견: 너무 어려워요...
Universal Sequence Preconditioning
TL; DR: linear dynamical system을 ‘orthogonal polynomial로 convolution’ 함으로써 sequential prediction을 preconditioning 합니다.
논문의 접근: target sequence를 어떤 함수로 convolution하는 것이 hidden transition matrix에 그 함수의 polynomial을 적용하는 것과 같다는 관찰에서 출발합니다. Chebyshev / Legendre 같은 orthogonal polynomial 계수를 preconditioning kernel로 사용하면, marginally stable / asymmetric transition matrix를 가진 LDS에 대해 hidden dimension에 무관한 sublinear regret bound가 성립합니다. RNN을 포함한 다양한 sequential predictor와 결합 가능하며, 실제 데이터에서도 LDS 가정을 넘어서는 효과를 보입니다.
개인 의견: