colm 2024
ICLR 2024, Nominated as Outstanding papers
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
기존 문제 : State space models (SSMs) 가 유행하기 시작하면서, Mamba와 같이 본격적으로 이를 적용한 LLM이 등장하기 시작했습니다. 실제로 Long range arena와 같이 장문의 문맥을 이해해야 풀 수 있는 벤치마크에서는 SSM 기반 LLM들이 높은 성능을 보였습니다. 그래서 transformer 변형 구조나 장문의 문맥을 반영해야 하는 경우 SSM을 채택하는 것이 좋다는 Trend가 생겨나기 시작했습니다.
Highlight figure
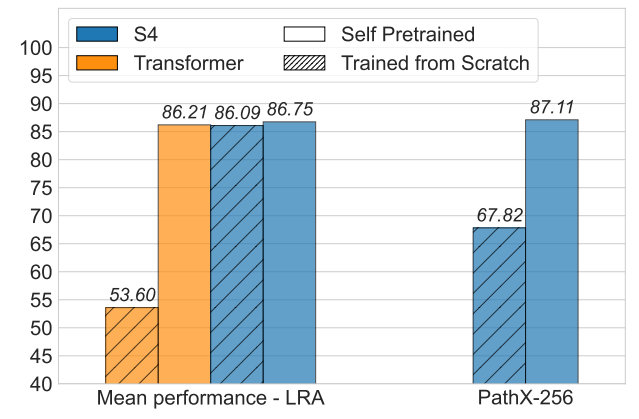
논문이 이끌어낸 직관 : SSM이 적용된 모델과 vanilla transformer를 비교했을 때, Long range arena benchmark에 대해서만 학습하는 경우에는 SSM 적용 모델의 성능이 좋지만, Pretrained 모델을 쓸수 있을 경우 transformer와 SSM 적용 모델간의 성능은 거의 차이가 없습니다. 심지어 theoretical connection이 잘 드러난 HiPPO 등 직접적인 분석비교를 해봐도, SSM이 long-range dependency를 더 잘 고려한다는 증거를 확인할 수 없고, 오히려 transformer의 self-supervised learning 형태의 pretraining은 task, data agnostic하게 성능을 향상시킨다는 증거를 더 강고히 합니다.
활용방안 및 향후 연구(개인적 의견) : LLM의 한계를 탈피하려는 시도는 굉장히 많이 이루어지고 있지만, theoretical → analyses → method proposal 이 잘 연결된 SSM 기반 모델들 (Legendre Memory Units, HiPPO, S4) 조차 기존 transformer의 성능을 깨지 못하는 것 같아서, transformer 구조 개선에는 생각보다 긴 시간이 걸릴 것 같습니다.
Generalization in diffusion models arises from geometry-adaptive harmonic representations
기존 문제 : LLM은 데이터를 암기하면서도 일반화를 잘 하는 것으로 알려져 있습니다. 하지만 학습 데이터의 순서를 바꾸는 등 데이터 전체를 입력 X로 놓는 이론적 접근은 실제와 잘 연결되지 않는 것으로 알려져 있습니다. 이는 즉 Language modeling task가 언어의 inductive bias를 고려하지 않는다고 할 수 있습니다. 반면 diffusion과 같은 방법은 워낙 빠르게 학습하는 등 특정 inductive bias를 활용하고 있다는 여러 추측이 나온 상태입니다. 그래서 이를 활용한 adversarial method도 최근 제시되고는 했습니다.
Highlight figure

논문이 이끌어낸 직관 : D에서 샘플링된 동일 크기의 데이터 d1, d2는, 데이터 크기가 충분하다면 겹치는 데이터가 없더라도 거의 동일한 모델을 만들어냅니다. 논문에서는 학습 이미지의 feature geometric에서 오는 optimal bases가 존재하고, diffusion 모델은 optimal bases를 학습하는 inductive bias가 존재한다고 설명했습니다.
활용방안 및 향후 연구(개인적 의견) : LLM에도 optimal bases가 있으면 좋겠습니다…
Vision Transformers Need Registers
기존 문제 : 이미지에서 아주 간단한 object를 약간만 이동시켜도, vision model은 이를 OOD data로 인식하여 저조한 추론 성능을 보였습니다. 이를 해결하기 위해 Slot attention의 등장과 함께 object-centric learning 연구 트렌드가 나오게 되었습니다.
최근 DINO 알고리즘이 self-supervised learning만으로 사진에서 object를 잘 detect하는 특성을 보이고, 이는 곧 vision 분야 downstream task의 혁신적 개선을 이뤄냈습니다. DINO2는 depth estimation이나 semantic segmentation과 같은 difficult downstream task를 더 높은 성능으로 수행하면서, vision 모델의 진전을 이뤄낸 듯 싶다가, 특이하게도 LOST와 같은 기존 object detection 알고리즘을 적용하면 성능이 크게 하락하는 dynamics를 보였습니다. 본 논문은 DINO2가 DINO와 다르게 동작하는 부분을 분석하였습니다.
Highlight figure
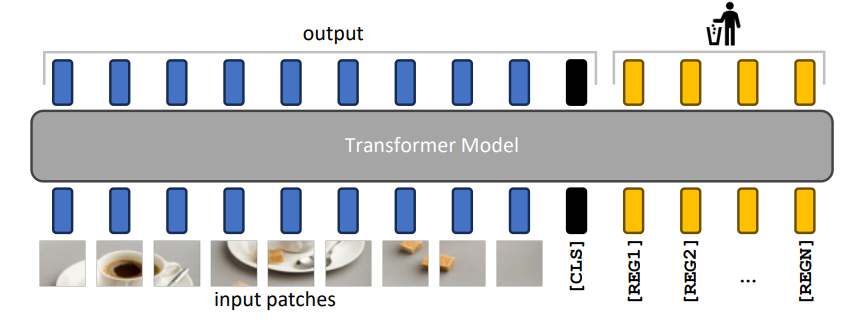

논문이 이끌어낸 직관 : DINO2 모델은 이미지 background와 같은 정보가 반복적으로 발생하는 패턴임을 인지하고, 해당 위치의 patch token을 아예 CLS와 같은 이미지 자체의 global information을 저장하는 데 사용합니다. 본 논문은 이 현상을 ‘DINO2는 global information을 따로 저장할 곳이 없으니, background 위치의 토큰이라도 대신 사용한다’ 라고 추정하여, global information을 저장할 수 있도록 ‘register’라는 dummy input 부분을 만들었습니다. 그 결과, global information이 patch output에 드러나는 현상이 사라진 것을 확인할 수 있었습니다.
활용방안 및 향후 연구(개인적 의견) : 저는 BERT-prefix와 같은 다양한 efficient training method가 나오면서도 CLS 토큰에 입력 텍스트의 특징이 전부 담길 것이라는 naive한 가정을 해왔습니다만, 본 논문의 hypothesis가 맞다면 sentence / document embedding method에도 충분히 적용할 수 있을것 같습니다.
별개로, Journal style의 정석적인 motivation - analyses - proposal 구성이 매우 잘 담겨서 정말 잘 쓰여진 논문이라고 생각했습니다.
논문에서 제시하는 근거 (via analyses) :
-
DINO2의 특징 : attention map 상에서 background 영역에 high-norm token을 발생시킵니다. 이를 artifact라고 칭합니다.
-
보조 figure

-
-
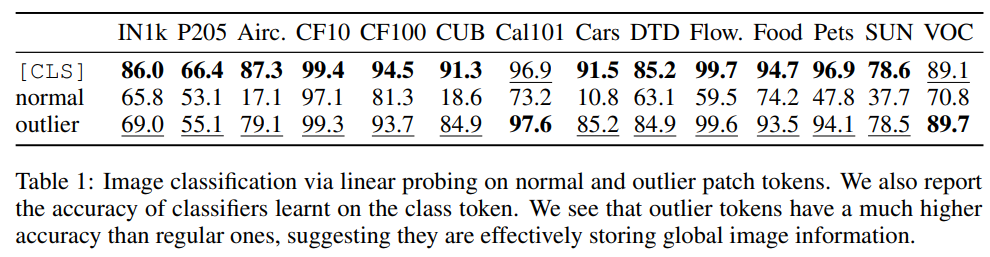
Analyses via position prediction & pixel reconstruction : patch token이 local information을 담고 있는지 확인할 수 있는 position prediction & pixel reconstruction task를 수행하자, DINO2의 high-norm token에 대해서는 특히 저조한 성능이 관측됩니다. 즉, high-norm token은 local information을 거의 가지지 않습니다.
-
So are those useless? : high-norm token은 이미지 전체적인, global information을 가집니다. 즉 이미지의 domain이 어떤지 파악하기 위한 부분이며, CLS 토큰과도 비슷한 역할을 합니다. 다만 학습 데이터가 너무 많은 나머지 CLS만으로는 global information을 담을 수 없는 것으로 사료됩니다.
-
보조 figure
-
Learning Interactive Real-World Simulators (UniSim)
기존 문제 : 언어모델은 오로지 텍스트 정보만을 활용해 지식을 학습하므로, 시각적 정보나 실제 물리적 환경을 이해하지 못한다는 문제가 있습니다. 하지만 실험적인 시도 (VLM, VQA model)는 robustness가 떨어지는 등 아쉬운 성능을 보였습니다.
Highlight figure
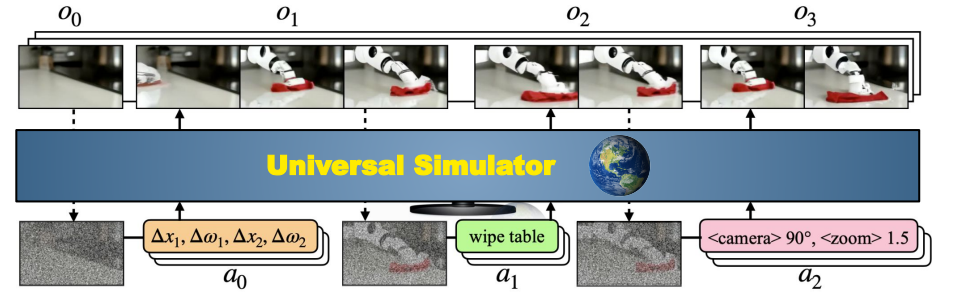
(Following figure estimates about model capability)
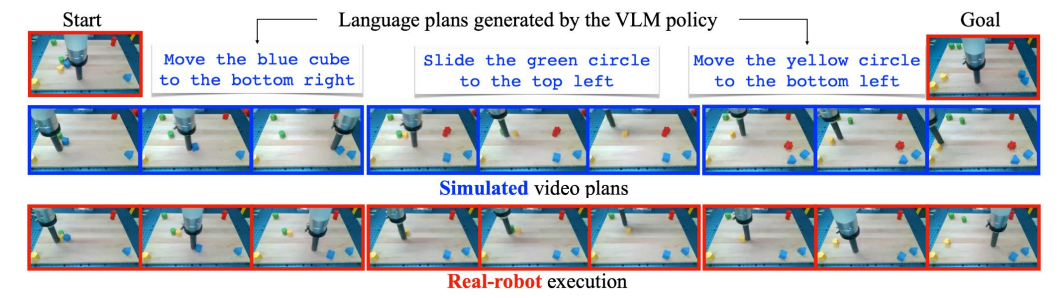
논문이 이끌어낸 직관 : 주어진 image frame t-1에 대해 실제 기기 컨트롤, 언어 명령 등을 condition으로 image frame t를 denoise(diffusion) 하는 것으로, 다양한 시각적 혹은 물리적 정보를 학습하고자 하였습니다. 놀랍게도 이렇게 학습된 모델은 텍스트 명령에 따른 다음 발생 사건을 비디오 프레임 예측을 통해 예상할 수 있습니다.
활용방안 및 향후 연구(개인적 의견) : 텍스트 정보만으로 모델을 학습시키는 것에는 다양한 한계점이 존재하고, 물리 환경을 구축하여 메타버스에서 어떤 모델을 학습시킨다는 컨셉도 나와있지만, 이와 같이 비디오 frame 예측 task로 일반화할줄은 몰랐습니다. 다만 논문에서는 매우 단순한 케이스만을 보여줘서, VQA 모델의 문제처럼 less robust하지 않을까 생각되기는 합니다.
AAAI 2024, Nominated as Outstanding papers
Reliable Conflictive Multi-view Learning
기존 문제 : 어떤 객체에 대해 view perspective를 여러개 만들고, 이에 대해 틀린 perspective가 틀렸다고 학습하거나, 그 반대로 맞는건 맞다고 학습하는 등 multi-view learning은 Vision LLM 등에 잘 활용되거나, 아예 일반화하면 SimCSE의 motivation으로도 연결될 수 있습니다. 하지만 실세계의 다양한 데이터는 각 view perspective의 opinion (혹은 레이블) 이 모두 정답이라고 할 수 없습니다. 따라서 어느정도는 uncertainty를 고려해야 할 것으로 추정되었습니다.
Highlight figure
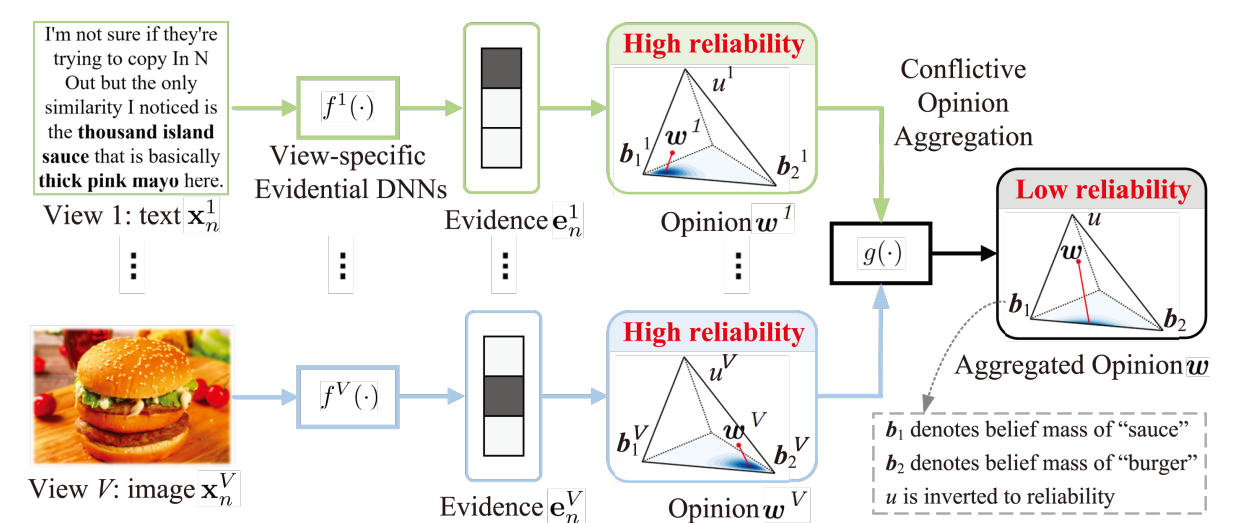
논문이 이끌어낸 직관 : 각 view perspective에 대해 ‘opinion’이라는 추상화된 representation으로 변환하는 모델을 만들고, 잘못된 opinion은 서로 상충된다는 특징을 활용해 multi-view learning을 수행합니다. 이 때 본 논문의 특별한 가정 몇가지를 볼 수 있는데,
- 처음에는 정상적인 데이터에 대해 학습함으로서, opinion representation들이 well align되도록 유도한다.
- 각 viewpoint에 대한 opinion은 uncertain할 수 있다.
- opinion representation을 직접적으로 align하지 않는다.
즉, opinion representation을 간접적으로만 사용하면서 DiffCSE와 비슷하게 representation을 학습하는 방법입니다.
활용방안 및 향후 연구(개인적 의견) : 일단 NLP 도메인에서는 prior uncertainty 등을 잘 고려하지 않고, 실제로 학습된 pretrained BERT-style 모델은 model calibration을 잘 달성하는 것으로 추정됩니다. 아마 이 방법은 주어진 paired 데이터셋을 최대한 활용하고자 하는 방법 같은데, opinion representation이 transferable한지 궁금하네요. 물론 data uncertainty를 고려하면서 multi-view learning을 제안했다는 것만으로도 좋은 발상입니다.
DISCount: Counting in Large Image Collections with Detector-Based Importance Sampling
기존 문제 : 인공위성 사진이나 개체를 특정하기 어려운 task의 경우, 레이블링 비용이 매우 높아집니다. 실제 해당 domain에 특화된 오픈모델은 거의 없기 때문에, 안그래도 비싼 데이터를 자체적으로 확보해야 한다는 문제가 있습니다.
Highlight figure
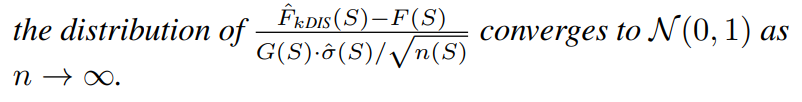
논문이 이끌어낸 직관 : 전체 지역의 사진 region S 가 n개의 sub region {s_1, s_2, … s_n} 으로 구성될 때, 랜덤하게 sub region을 뽑아 k개의 subset을 만듭니다. 이후 subset index를 i로 지칭할 때, prediction g_i와 ground truth f_i의 차이에 따라 importance weight w_i를 계산합니다. 이를 종합하여 기존 방법보다 더 정확한 counting 알고리즘을 제안했습니다.
활용방안 및 향후 연구(개인적 의견) : active learning의 느낌도 나고 Bayesian Inference의 느낌도 나는데, 실용적으로 레이블링 비용을 줄일 수 있는 방법에 해당하지만 학술적 기여가 크지는 않은 느낌입니다. importance sampling, CLT, uncertain prior 등 기초적이고 자주 등장하는 방법을 잘 조합했다고는 생각합니다.
Proportional Aggregation of Preferences for Sequential Decision Making(작성예정)
(작성예정)
ACL 2024, Selected papers
-
https://arxiv.org/abs/2401.06751
기존 문제 : LLM의 주요 필요요소중 하나는 문제정의에 부합하는 데이터입니다. 쉽게 보자면 사람들에게 annotation을 시켜서 데이터를 만들면 되는 문제이지만, 어렵게 보자면 데이터의 분포, 엣지 케이스 커버 능력, task의 일반화, 사람이 보는 데이터의 난이도, LLM이 보는 데이터의 난이도 등 고려해야 할 요소가 상당히 많습니다. 그 중 본 논문은 데이터의 ‘난이도’에 주목했습니다.
-
Highlight figure
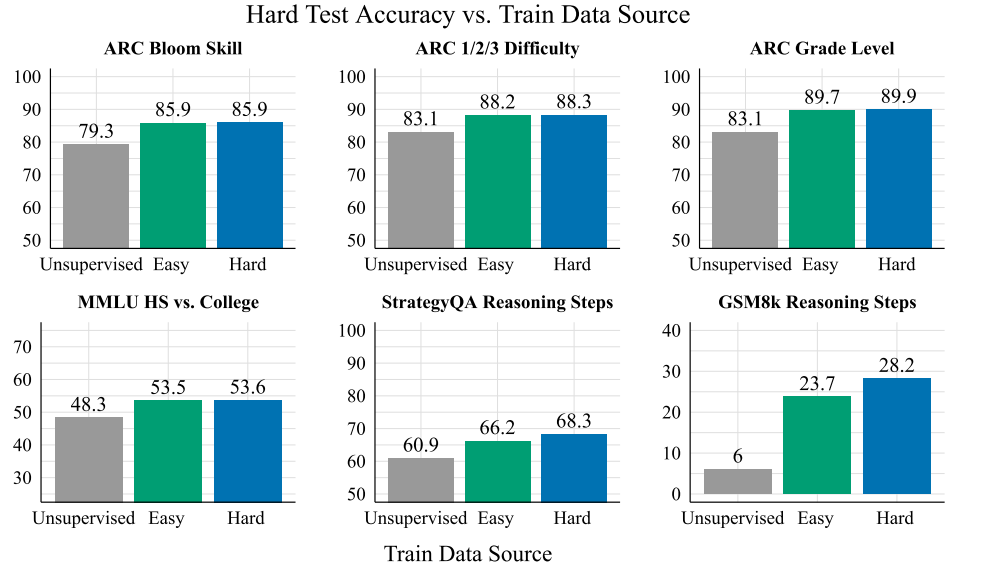
논문이 이끌어낸 직관 : 사람에게 있어서 어려운 task는 딥러닝에게도 어려운 경향이 있으며, 해결해야 할 문제가 사람에게 어렵다면, 사람에게도 어려운 데이터를 annotate 하여 학습해야 합니다. 하지만 딥러닝 모델은 쉬운 문제 데이터로 학습되더라도 어려운 문제를 일부 해결할 수 있는 능력이 있어, 데이터 annotate 가성비는 쉬운 쪽의 데이터가 훨씬 좋습니다.
활용방안 및 향후 연구(개인적 의견) : 이전에 고유명사를 활용한 특수 도메인 데이터 선택방법으로 논문을 발표한 경험이 있는데, ‘LLM에게 어렵다’라는 기준은 아직 확립되지 않은 연구분야에 해당합니다. 특히 어려운 데이터를 학습해야 복잡한 추론을 할 수 있는건지 등 학습 효율성에 있어 데이터를 어떻게 선택해야 하는지에 대해서는 거의 연구되지 않았습니다. 다만 저는 ‘번역모델이 생성해낸 고유명사 부분의 distribution entropy’ 를 기준으로 하여 효율적으로 unlabeled 데이터를 선택하는 방법을 제안한 바가 있습니다. 개인적으로는 제가 쓴 논문이 좀 더 상위호환이지 않을까 싶네요 😅
https://arxiv.org/abs/2402.19267
→ 우씨 이거 제가 쓴게 더 상위호환이에요 ㅡㅡ
-
-
https://arxiv.org/abs/2403.09490
기존 문제 : LLM이 유행하고 chatGPT가 만능인것처럼 보이지만 여전히 문장이나 문단에 대한 representation 학습 방법은 확립되지 않았습니다. 특히 단일 sentence는 대부분 어떤 문맥 조건 하에 발생했기 때문에, 진짜 sentence 정보만을 이용해서 sentence representation을 만들기는 어렵습니다.
-
Highlight figure
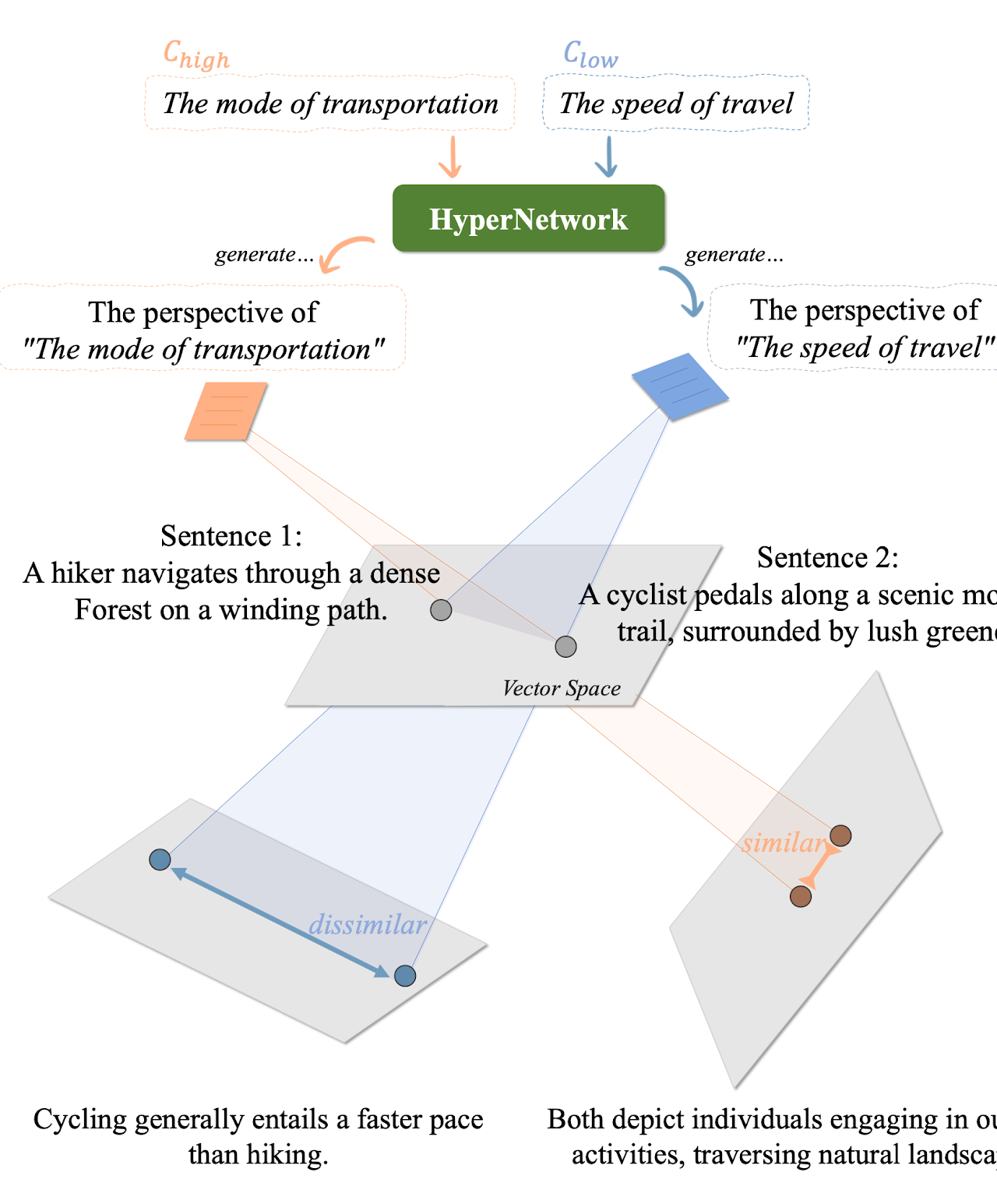
논문이 이끌어낸 직관 : 문장의 의미는 문맥에 의해 결정된다고 한다면, sentence representation을 아예 특정 ‘perspective’ 라는 condition을 통해 contrastive learning을 할 수 있습니다. 그림에서처럼 ‘hiker가 빠르게 산속을 질주한다’ 라는 문장과 ‘cyclist가 산속 잔디밭을 달린다’ 라는 문장은 언뜻 의미가 비슷하다고 판단하기 어렵지만, ‘이동수단’ 이라는 관점에서는 의미가 비슷하고, ‘질주 속도’ 라는 관점에서는 의미가 다르므로, 문장과 관점 정보를 통해 contrastive learning을 수행합니다.
활용방안 및 향후 연구(개인적 의견) : phrase representation과 같이 represent할 대상과 그에 대해 부여하는 조건을 잘 활용하는 것이 중요할 것 같습니다. 본 논문에서도 그런 점에서는 좋은 연구이긴 하지만, 문제는 ‘관점에 따른 의미 변화’ 와 같은 복잡한 추론이 담긴 데이터가 필요하므로, 실용적이라고 판단하긴 어려울것 같습니다.
-
-
https://arxiv.org/abs/2402.18281
기존 문제 : Sentence representation은 아직 확립된 metric이 없습니다. MTEB과 같이 representation의 task performance를 측정하는 벤치마크가 있기는 하지만, representation의 fine-tuning transferability (즉 BERT와 같이 일반적인 모델 대비 각 작업에 fine-tuning한 이후의 성능 향상 정도)를 비교관측하는 것보다는 차라리 LLM을 쓰는 것이 훨씬 비용절감이 됩니다. 게다가 기존에 representation에 대한 direct metric이라 할 수 있는 STS(semantic similarity via vector) 가 non-train transferability(frozen representation + single MLP로 학습했을 때 성능, linear probing이라고도 함)와 연결되지 않는, 즉 STS에서 성능이 낮은 임베딩도 non-train transferability는 높을 수 있다는 연구가 나와서 direct metric이 절실한 상황입니다.
-
Highlight figure

논문이 이끌어낸 직관 : sentence representation 학습 방법을 ‘gradient dissipation’, ‘weight’, ‘ratio’ 라는 세 가지 기준으로 잡아 학습방법을 서로 비교하였습니다. 그 결과 학습 방법마다 제각각의 condition for optimization이 있다는 것을 관측하였고, 기존에 STS task 성능이 낮았던 학습방법들에 제안 기준을 적용하여, 성능을 향상시켰습니다.
활용방안 및 향후 연구(개인적 의견) : STS, non-train transferability, 그리고 fine-tuning transferability 이 세가지를 연결할 방법이 필요할 것 같습니다. 그런 점에서 본 논문의 접근은 나쁘지 않지만 STS와 non-train transferability가 어떻게 연결되는지 설명이 거의 없어서, 거창하게 기준을 검증하고 설정하기 위해 사용된 페이지들이 좀 아쉽습니다. Vision 연구처럼 object-centric이나 제가 했던 고유명사를 활용하는 방법 등이 있지 않을까 싶기는 합니다.
-
-
https://arxiv.org/abs/2401.06416
기존 문제 : 딥러닝 모델의 경우 ImageNet과 같은 이미지 데이터셋의 레이블을 아예 랜덤으로 바꾸더라도 train error는 0을 달성할 수 있습니다. 이때를 기점으로 memorization과 generalization의 상관관계에 대한 연구가 나오기 시작했는데, 최근에는 알파뱃 체계를 뒤섞어서 언어모델을 학습한다던가, 동일한 데이터를 1000개 더 넣어서 학습했을 때 학습능력을 확인하는 등 여러 재미있는 연구로 응용되었습니다. (연구 1, 연구 2)
-
Highlight figure
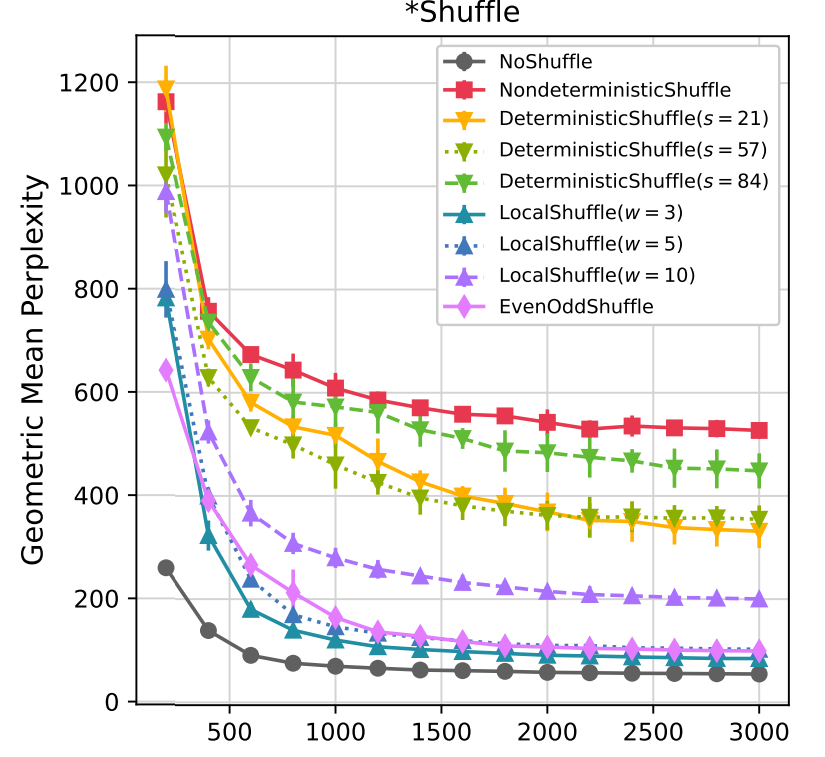
논문이 이끌어낸 직관 : LLM은 일정 언어 체계가 있어야 언어를 학습할 수 있습니다. 이를테면 단어를 완전히 랜덤으로 뒤섞어서 학습을 시킬 경우, 사람이 이를 이해할 수 없듯이 LLM도 이를 이해할 수 없습니다.
활용방안 및 향후 연구(개인적 의견) : 이런 연구는 겉으로 보기엔 큰 의미가 없어보이지만, 개인적으로는 인간과 LLM의 추론, 학습 방법이 어떻게 다른지 분석하는 연구로도 해석할 수 있어서, 다양한 아이디어를 줄 수 있다고 생각합니다.
-
(리뷰예정)
-
https://arxiv.org/abs/2403.10381
기존 문제 : 딥러닝 모델의 경우 ImageNet과 같은 이미지 데이터셋의 레이블을 아예 랜덤으로 바꾸더라도 train error는 0을 달성할 수 있습니다. 이때를 기점으로 memorization과 generalization의 상관관계에 대한 연구가 나오기 시작했는데, 최근에는 알파뱃 체계를 뒤섞어서 언어모델을 학습한다던가, 동일한 데이터를 1000개 더 넣어서 학습했을 때 학습능력을 확인하는 등 여러 재미있는 연구로 응용되었습니다. (연구 1, 연구 2)
-
Highlight figure
논문이 이끌어낸 직관 : LLM은 일정 언어 체계가 있어야 언어를 학습할 수 있습니다. 이를테면 단어를 완전히 랜덤으로 뒤섞어서 학습을 시킬 경우, 사람이 이를 이해할 수 없듯이 LLM도 이를 이해할 수 없습니다.
활용방안 및 향후 연구(개인적 의견) : 이런 연구는 겉으로 보기엔 큰 의미가 없어보이지만, 개인적으로는 인간과 LLM의 추론, 학습 방법이 어떻게 다른지 분석하는 연구로도 해석할 수 있어서, 다양한 아이디어를 줄 수 있다고 생각합니다.
-