ICLR 2025 Orals
✨Unlearning-based Neural Interpretations
기존 문제: unlearning같은 방법은 Deep model safety 분야의 고전적이고 핵심적인 방법이지만, 의도치 않은 feature를 변경해버린다는 문제가 있습니다. 그래서 unlearning이 의도한 feature만 잊게 만드는지 확인하기 위해 ‘attribution’을 참고할 수 있는데, 공백의 이미지와 목표 이미지를 interpolation 해나가며 이것이 어떤 gradient를 형성하는지 관측하는 방법입니다. 이것을 Integrated Gradients라고 하고, 공백 이미지를 baseline이라고 합니다.
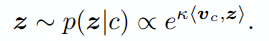
Integrated gradients는 단순하지만 효과적인 방법인데, baseline에서 조금만 목표 이미지로 보간되어도 금방 gradient map을 볼 수 있기 때문입니다. 기존에는 0.5로 보간하려다 gradient가 소멸되어서 제대로된 map을 볼 수 없었다고 하네요.
하지만 모델들은 모두 baseline에 bias가 있다는 문제가 있습니다. 검정 이미지는 전체적으로 검은 이미지를 나타내기 힘들거고, 가우시안 노이즈는 가우시안 필터링된 데이터에 취약할거고… 그 어떤 baseline을 쓰더라도 bias가 있기 때문에, 논문에서는 baseline으로 차라리 원본 이미지?를 쓰는게 낫다고 주장합니다.
논문의 직관: 하지만 baseline이 원본 이미지라니? 백번 양보해서 perturbation을 넣더라도 위 그림과 같이 엥간해서는 gradient map으로 visualize하기 위한 scaling 수치를 찾기 힘들겁니다. 그래서 논문에서는 어마어마한 발상을 해내는데,..

unlearned model은 목표 데이터 혹은 목표 클래스에 대해 잊도록 학습하는데, 처음에는 매우 뾰족한 probability density를 보이다가, 나중에는 처음부터 학습되지 않은 데이터마냥 representation space상에서 smooth한 지평선을 그리도록 학습됩니다. 이 때 unlearning gradient를 활용하기 어려운 이유는, 위 그림과 마찬가지로 어느 순간 probability density가 확 꺾여서 gradient scale도 확 꺾이기 때문입니다.
여기서 착안하여, 원본 모델 및 step 를 거쳐 unlearn되는 모델 를 가정할 때, 여기에 원본 데이터 x와 perturbed 데이터 를 넣을 때 KL divergence를 minimize 하는 를 찾습니다. 그 다음, 를 baseline으로 삼습니다. 이러면 unlearning을 일으키는 듯한 perturbation을 찾을 수 있고, 이는 곧 attack vulnerable이라고도 할 수 있습니다. 그러면 반대로도 말할 수 있겠죠? 주어진 모델이 robust한지 아닌지, 내가 입력한 데이터가 학습되었는지 아닌지 perturbation까지 고려해서 확인할 수 있다는 것입니다.
개인 의견: ICLR oral 퀄리티가 작년부터 너무 처참하게 무너졌나 싶었더니 그래도 하나 나오네요. 이 방법은 AI safety area에선 혁명과도 같은 연구가 아닐까 싶습니다. 게다가 attack method에도 agnostic하게 적용할 수 있는 방법이어서, 당분간은 모델, attack, defense 광범위한 분야의 metric으로 사용되지 않을까 싶네요.
Attention as a Hypernetwork
기존 문제 : attention이 효과적인 토큰 참조 도구는 맞지만, dense attention의 성능과 sparse attention의 효율이 계속해서 tradeoff로 작용해오고 있습니다.
논문의 접근 : multi-head attention의 head index t를 상정할 때,
어텐션에서
어텐션을 사용합니다.
qko와 qkv를 미리 계산해놓을 수 있기 때문에, 더 효율적인 병렬화를 할 수 있다는 장점이 있을까 싶기도 하지만, 반대로 새로운 레이어가 추가되니 갸우뚱한 면도 없잖아 있습니다.
가설 및 결과: qkvx는 x를 주변 맥락에 따라 어떻게 해석하느냐의 역할을 맡게 되는데, 여기에 o를 바로 matmul하는 대신 Relu를 써서 필요한 부분만 활성화한다고 해석할 수 있습니다. 그러면 자연스럽게 multihead의 sparsity를 기대할 수 있을것입니다.
-
Highlight figure
실제 가설대로 multihead가 sparse해져서 여러 task에 generalize 되는 모습을 볼 수 있습니다.
개인 의견: 음… hypernetwork라고 칭하는건 약파는것 같네요.
Cross-Entropy Is All You Need To Invert the Data Generating Process
기존 문제 : 이론적으로만 따지자면, representation은 주어진 데이터를 특정 관점에 따라 이해한 ‘내용’으로 해석할 수 있습니다. VAE가 이 관점을 활용하여 representation을 학습함과 동시에 generation도 가능함을 보였습니다. 혹은 압축으로도 해석할 수 있어서, 해당 관점을 안다는 가정 하에서라면 원래 데이터로 복원할 수 있습니다. 하지만 당연히 여기에는 다양한 난관이 있기 때문에 (entangle, collapse, interpolate-ability, expressibility 등) diffusion 모델과 같이 거대한 representation을 사용하는 모델이 주류를 차지하고 있습니다.
논문의 접근 : classification으로는 너무 도메인 지엽적인 representation이 나와버린다는게 문제고, 그렇다고 contrastive learning으로는 hyperparameter를 조절하기 어렵다는 문제가 있습니다. 그래서 일단은 시중에 나와있는 representation learning 방법을 정리했습니다.
본문에서는 DIET라는 방법을 중심으로 다루는데, 이는 representation z와 data index vector (randomly initialized) (\in R^d) 에 대해 contrastive learning을 수행하는 방법입니다.
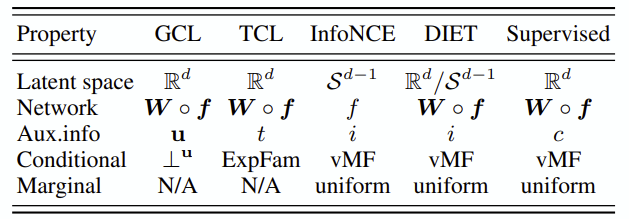
u는 representation itself, t는 time-step scalar, i는 data index, c는 class입니다.
논문의 해석: 기존의 DIET라는 학습 방법이 InfoNCE와 Supervised 방법을 잘 보간하고, high expressibility를 가진 representation을 형성한다고 해석합니다. 왜냐하면,
말 그대로 , where 이기 때문입니다. (뭐지?)
본 논문은 infoNCE와 TCL을 Supervised와의 보간-보완을 하고자 했습니다. 간략히 설명드리자면,
TCL-Supervised간에는 representation-classification 과정이 특정 class c로 수렴하느냐, augmented data끼리 수렴시키느냐의 차이가 있습니다.
InfoNCE-Supervised간에는 data index로 수렴시키느냐, class c로 수렴시키느냐의 차이가 있습니다.
개인 의견: 좀 다소 황당한 내용이라 생각하는데, 왜냐하면 representation간의 interpolation이 data interpolation으로 이어지는지에 대한 설명을 할 수 없기 때문입니다. 입력했던 데이터를 ‘구분’할 수 있다는것 만으로 representation이 invertible 할만큼 expressibility가 높아진다면, 그 반대로 generalizability는 담보할수 있을까요? autoencoder 때로 회귀하는 논문 같습니다.
The Geometry of Categorical and Hierarchical Concepts in Large Language Models
기존 문제: LLM의 representation을 이해하려는 시도는 계속되고 있습니다.
-
첫 그림
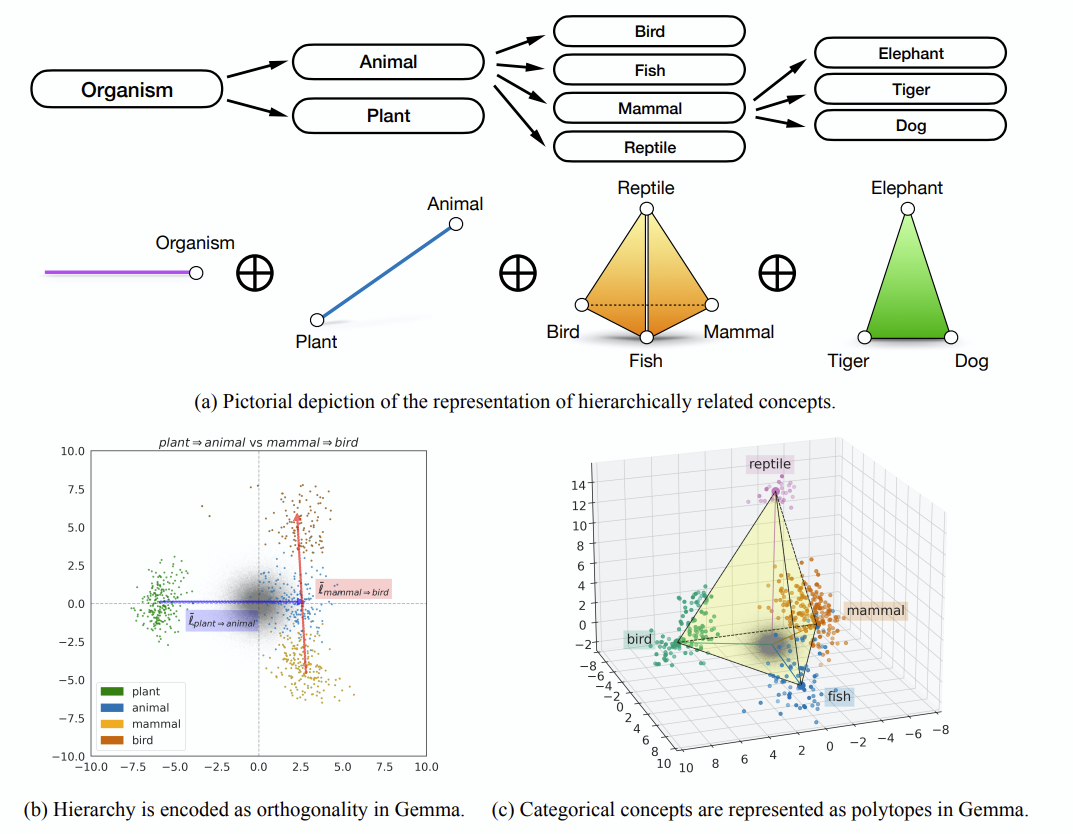
논문의 해석: LLM이 입력 x에 대해 출력 y를 내놓는다고 할 때, representation h와, LM head를 거쳐 vocabulary v차원이 되기 직전!! MLP를 한번 거친, h와 동일 사이즈 벡터 h+를 생각해볼 수 있습니다. h+도 일종의 representation은 맞지만, self-attention 등 다양한 과정을 거치지 않고 LM head로 forward 되기 직전의 상태이므로 vocabulary embedding에 가까운 형태라고 볼 순 있습니다.
그러면 여기서 어떤 weight A가 있다고 할 때,
라고 한다면, A가 embedding/unembedding을 수행한다고 볼 수 있겠죠? 이 때 C는 normalize를 위한 constant vector입니다.
분석 방법 및 결과: 매우 이상적으로 생각해서, disentangled representation을 학습한 LLM이 있더라도, 이 모델이 만든 word representation이 우리가 생각하는 feature와 align되지는 않습니다. 예를 들어 dog, tiger 둘 다 animal의 한 종류이지만 tiger는 맥주도 있고 게임 브랜드도 있으므로, animal이란 feature는 dog보다 좀 더 낮을 것입니다. 즉, 둘 다 정확하게 동일한 크기나 방향의 ‘animal’이란 feature를 가지지는 않을 것입니다.
그러면, 평균적인 vector 차이를 사용해볼 수 있겠죠? 어떤 온톨로지 체계에 plant와 animal이 있다고 칠 때, 각각의 단어 벡터들을 취합하고, 이들의 차이를 ‘linear representation’이라고 가정해 봅시다. 그러면 이 linear representation이 plant와 animal을 아우르는 ‘organism’ representation에 대해 orthogonal이라면, 역으로 plant와 animal의 representation을 distinguish 한 것으로 해석할 수 있습니다.
그림의 재해석
자, 이제 그림을 다시 볼까요?
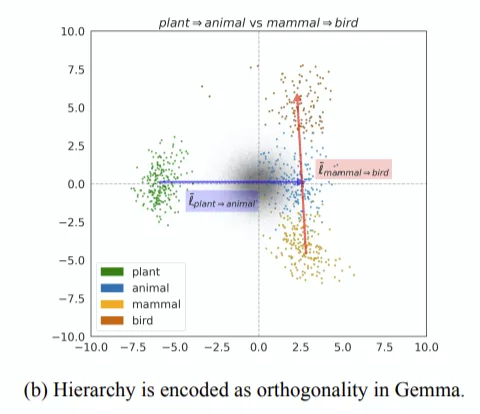
이 그림은 organism에 대해 orthogonal한 feature plant와 animal을 visualize 한 것입니다. 다시 말해, organism이라는 linear representation은 3차원상에 존재한다고 보시면 됩니다. 이를 통해 hierarchical category 체계가 존재하는지 관측하기 위한, word representation을 visualize하는 방법론을 제시했습니다.
개인 의견: 고전적이고 당연한 얘기일수도 있지만, 제일 많이 오해할 수도 있는 내용이고 실제로 구현하는 데 있어 많은 실수를 낳는 부분이기도 합니다. 이걸 명확히 해줬다는 점에 있어 그래도 좋은 논문이라고는 생각합니다.
Accelerated Training through Iterative Gradient Propagation Along the Residual Path
기존 문제: deep transformer는 residual connection을 따라 정보를 흘려보내고, backward에서도 같은 residual path를 따라 gradient가 흐릅니다. layer 수가 많아질수록 backward 의존성 chain이 길어져 학습 wall-clock이 layer 깊이에 비례해 늘어나는 구조적 한계가 있습니다.
논문의 접근: residual path를 따라 흐르는 gradient를 layer-wise sequential 방식으로 풀지 않고, iterative한 propagation으로 근사하여 layer 간 backward 의존성을 약화시킵니다. 이렇게 하면 forward와 backward의 일부를 병렬화할 수 있고, 동일한 수렴 품질을 유지하면서 학습 wall-clock을 단축시킬 수 있다는 주장입니다.
개인 의견:
ACL 2025, Selected papers
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
기존 문제: long context attention의 sparse 구현은 대부분 inference 단계에서만 적용되어, training-inference 간 mismatch가 누적되거나 학습 자체가 unstable한 문제가 있었습니다. 또한 sparse pattern이 hardware에 friendly하지 않으면 이론상의 speedup이 실제 wall-clock 개선으로 이어지지 못한다는 한계도 있었습니다.
논문의 접근: 세 가지 attention pathway를 병렬로 두고, 각 pathway가 서로 다른 granularity를 담당하도록 설계했습니다.
- Compression: 멀리 떨어진 토큰들을 block 단위로 압축한 coarse summary token을 만들어 attention 대상에 포함합니다.
- Selection: block-level importance score를 기반으로 중요한 block만 골라 dense attention 대상에 포함합니다.
- Sliding window: 가장 최근 토큰들에 대해 dense local attention을 수행합니다.
세 pathway의 결과를 학습 가능한 gate로 weighted sum 합니다. 이 구조는 학습 단계부터 end-to-end로 sparse하게 학습되기 때문에 training-inference mismatch가 발생하지 않습니다.
Hardware-aligned implementation: Triton 기반 GPU kernel을 작성하여, GQA 환경에서 KV가 head 그룹 내에서 공유된다는 점을 활용해 blockwise memory access를 최적화했습니다. 이론상 speedup을 실제 latency 개선으로 옮기는 것이 핵심 목표입니다.
실험 결과: 64k context length 기준 forward/backward에서 최대 9×, decoding에서 최대 11.6× speedup을 보고합니다. MMLU/GSM8K/code 등 short benchmark에서는 full attention 대비 성능 손실이 거의 없고, LongBench와 long-CoT 평가에서는 오히려 더 좋은 성능을 보입니다. 27B parameter model까지 학습 검증을 했습니다.
개인 의견:
A Theory of Response Sampling in LLMs: Part Descriptive and Part Prescriptive
연구 배경: LLM으로 데이터를 생성하고 그걸 통해 학습하는 방법은 이제 전형적인 방법이 되었을 정도로, LLM의 퀄리티는 크게 개선되고 실제 인터넷에도 LLM이 생성한 데이터로 가득합니다. 심지어 사람이 쓴 글과 구분하기 어려울 정도로 퀄리티가 개선되었는데, 그러면 정말 LLM이 생성한 데이터로 LLM을 학습시켜도 되는지에 대한 의문이 남습니다.
제안 가설: LLM은 ‘이상적인 내용을 자주 답하도록’ 학습되었기 때문에, 이를 통계취합할 경우 실세계의 통계와 달라지므로, LLM으로 생성된 데이터는 통계적 편향을 가지게 됩니다.
실험 내용
질문 하나에 대해 다양한 맥락을 제시하면, 대답에 대한 평균과 분산을 얻을 수 있습니다. 예를 들어 ‘사람이 일주일에 평균적으로 소비하는 가당 음료의 수’ 를 생각해보면, 통계 설문자료를 통해 바로 평균 값과 분산을 얻을 수 있습니다. 하지만, ‘이상적으로’ 생각해본다면, 가당 음료는 건강에 좋지 않으므로, ‘이상적인 평균 소비 가당 음료의 수는 몇이야?’라고 물어볼 때 ‘0’이라는 답을 얻을 수 있습니다.
만약 LLM이 ‘일반적인 통계’ 데이터와 ‘이상적인 답변’을 헷갈리지 않는다면, 같은 질문이라도 각기 다른 맥락에 따라 적당한 답을 낼 것이고, 이를 통계적으로 취합하더라도 실제 설문 통계와 동일한 결과가 나올 것입니다. 예를 들어 ‘설탕을 자주 소비하는 가족에서 평균적으로 소비하는 가당 음료의 수는?’ 이라는 답에는 평균보다 많이, 그렇지 않다면 평균보다 적게 답할 것입니다.
실험 결과
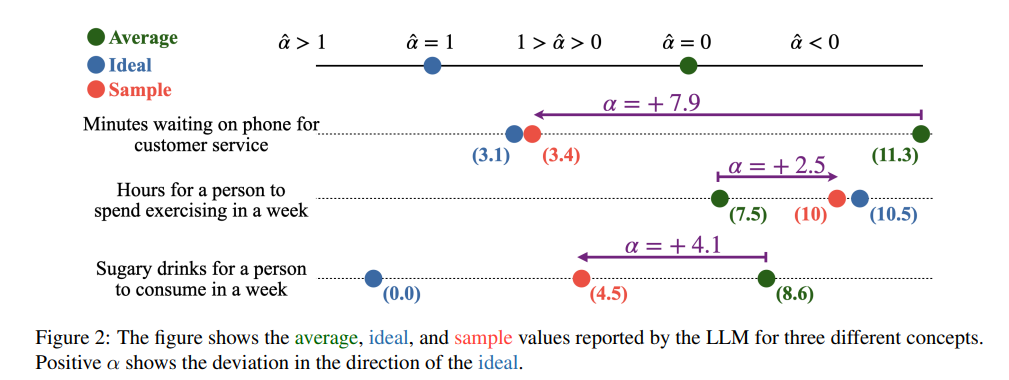
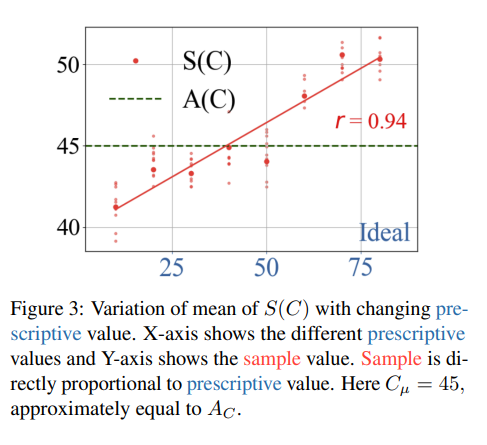
실험 결과 gpt4를 비롯한 대부분의 LLM은 이상적인 내용과 통계적인 내용을 헷갈려해, 이를 취합한 통계 결과와 실세계의 통계 결과는 유의미하게 다른 것으로 나왔습니다. 즉, 이상적인 내용으로 편향돼버리는 결과가 나왔습니다.
개인 의견
상당히 자명한 내용이면서도 오래전부터 대두돼온 주제이지만, GAN이 생성한 결과를 되풀이하는 등 명시적인 실험 이외에 LLM이 생성한 결과를 기반으로 실험한 경우는 그렇게 다양하지는 않았습니다. 있더라도 글의 특성상 explicit하게 그 결과가 나타나는 경우는 크게 없었는데, 이걸 explicit하게 드러낸 연구라는 데 의의가 있는것 같습니다.
Fairness through Difference Awareness: Measuring Desired Group Discrimination in LLMs
연구 배경: 학습 데이터에 의해 LLM이 편향을 가질 수 있다는건 상당히 오랜, 유명한 얘기인데, 이 편향 때문에 LLM의 추론 성능이 더 나빠진다는 얘기 또한 유명한 얘기입니다. 다만, 이게 실제로 실험으로 입증되지는 않고 있습니다.
실험 내용
흑인/백인 등 일부로 편향이 지워질 수 있는 주제를 포함하여 다양한 질문을 LLM에게 던집니다. 기존 연구 등 다양한 결과들을 감안하면 추론 결과가 그다지 좋지 않을 것이라 쉽게 떠올릴 수 있는데, 반대로 ‘remove your bias and answer’이라고 한다면, 정말로 bias가 지워지고 더 정확한 추론이 가능한지 의문이 듭니다. 본 연구는 이를 직접적으로 구현하고 실험했습니다.
실험 결과
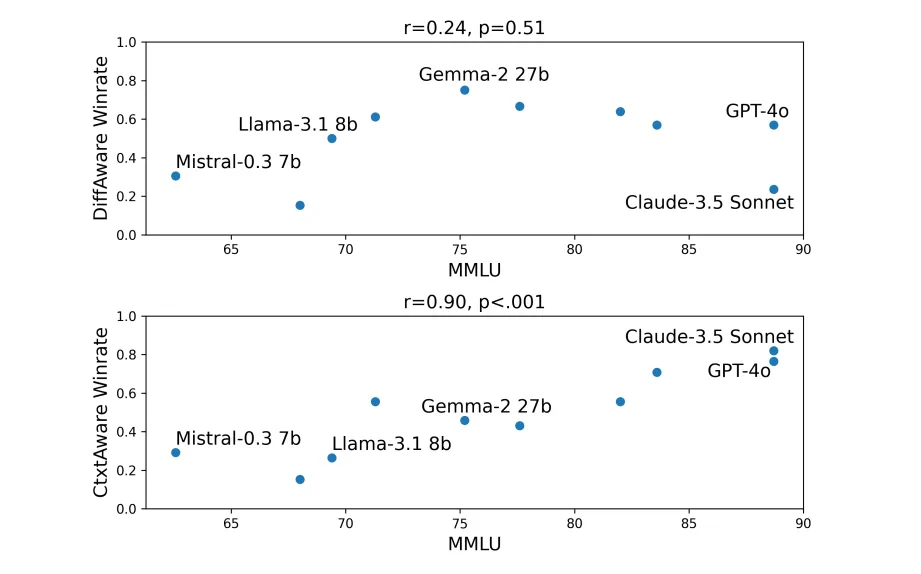
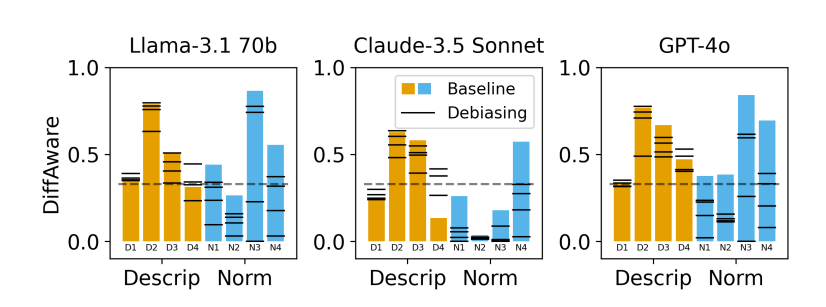
실험 결과 생각보다 끔찍한 결과가 나왔는데, 모델의 일반적인 추론 성능과 ‘차별이 아닌 차이’ 를 구분하는 능력은 관계가 없는 것으로 나왔습니다. 즉, 모델의 추론 능력이 좋은 것과 ‘차별이 아닌 차이’를 구분하는 능력은 별개이며, 심지어 ‘편향을 지우고 대답하라’ 라는 추가 지시사항을 넣으면 구분 능력이 오히려 더 저하되는 결과를 볼 수 있었습니다.
개인 의견
논문에서 저자가 ‘debiasing has gone too far’ 이라고 했는데, 그 말 그대로 편향을 강제로 완화하거나 검열하는 시도는 오히려 모델 추론 성능을 떨어뜨리다 못해, ‘debias and answer’같은 지시사항에 오히려 더 perplexed되는 황당한 상황을 야기한것 같습니다.
Language Models Resist Alignment: Evidence From Data Compression
기존 문제: LLM의 representation을 이해하려는 시도는 계속되고 있습니다. 특히 RLHF / SFT를 통한 alignment가 모델 내부 표현을 실제로 얼마나 바꾸는지에 대한 정량 분석은 부족합니다.
논문의 접근: alignment를 거친 모델과 거치지 않은 base model의 데이터 compression 능력 (perplexity 기반 description length) 을 비교하여, alignment가 모델의 내부 표현에는 거의 변화를 주지 않는다는 점을 보입니다. 즉 surface behavior는 바뀌어도, 내부에 압축되어 있는 distribution은 base model에 가깝다는 주장입니다. 이는 jailbreak처럼 alignment가 쉽게 무너지는 현상에 대한 한 가지 mechanistic 설명을 제공합니다.
개인 의견:
EMNLP 2025, AAAI 2025, COLM 2025 selected
Infini-gram mini: Exact n-gram Search at the Internet Scale with FM-Index
TL; DR: 텍스트 데이터를 인덱싱하기 위한 새로운 방법을 제안합니다.
기존 문제: 텍스트 인덱싱 알고리즘은 뭐… 좋은게 나오면 나올수록 당연히 좋습니다. 다만 trillion-token 규모의 코퍼스에서 임의 n-gram 빈도를 즉시 조회하려면, suffix array 기반 인덱스가 원본 텍스트 대비 수 배의 storage를 요구해서 실제 저장/배포 비용이 매우 큽니다.
제안 방법: suffix array 대신 FM-Index (Burrows-Wheeler Transform 기반의 succinct full-text index) 를 사용해 인덱스 크기를 원본 텍스트에 가까운 수준까지 줄였습니다. 이로써 임의 길이의 n-gram에 대해 exact frequency / occurrence position 조회를 O(query length) 시간에 수행할 수 있습니다.
Channel Merging: Preserving Specialization for Merged Experts
기존 문제: MoE 모델이 전체 파라미터 수 대비 높은 성능을 보여주기는 하지만, 여전히 전체 모델이 메모리에 올라가야 한다는 단점이 있습니다. 이를 해결하기 위해 ensemble 등 여러 merge 방법들이 시도되고는 있지만 MoE 자체가 새로 나온 구조이다 보니 아직 최적화된 merge 방법이 나오지는 않았습니다.
논문의 분석: 각 experts들이 task-specific하게 학습되고 초기화되더라도 정말로 task-disentangled 되어있지는 않습니다. codellama같은 전문화 모델에서 math task와 code task를 따로 학습시키고 expert를 ‘분리 학습’ 시켜도, 여전히 code task가 입력되면 math task specialized expert를 사용하게 됩니다. 때문에 좀더 다른 merge 방법이 필요합니다.
제안 방법:
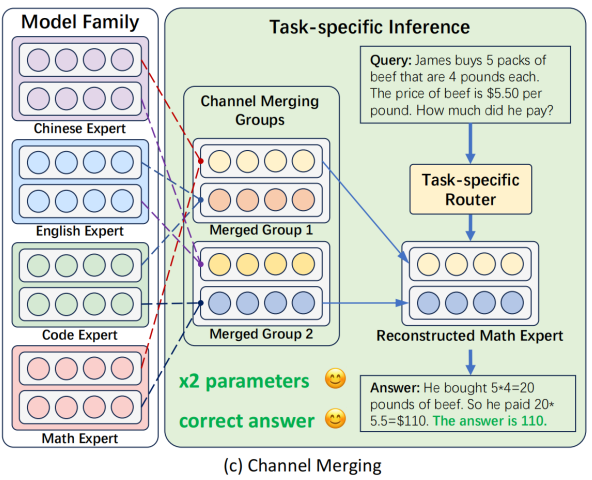
개인 의견: 저자가 expert를 channel이라고 쓰는 찐빠(혹은 LLM 안하던놈)를 내서 논문 읽는데 애좀 먹었습니다. AAAI는 정말 수준이 너무 낮아졌네요. 그래도 실용적인 방법을 제시해줘서 꽤 쓸만할것 같습니다.
AIOS: LLM Agent Operating System
기존 문제: LLM agent system은 하나의 LLM 위에서 multi-agent orchestration, tool calling, long-term memory, context window 관리 등 여러 기능을 동시에 굴려야 하지만, 이를 위한 system level abstraction은 여전히 ad-hoc하게 구성되고 있습니다.
논문의 접근: LLM 자체를 OS의 kernel처럼 두고, 그 위에 agent / context / memory / tool / scheduler 등을 OS 구성 요소처럼 추상화한 framework를 제안합니다. agent 간 자원 경합을 scheduler가 중재하고, context window는 paging / swap 비유로 다룹니다.
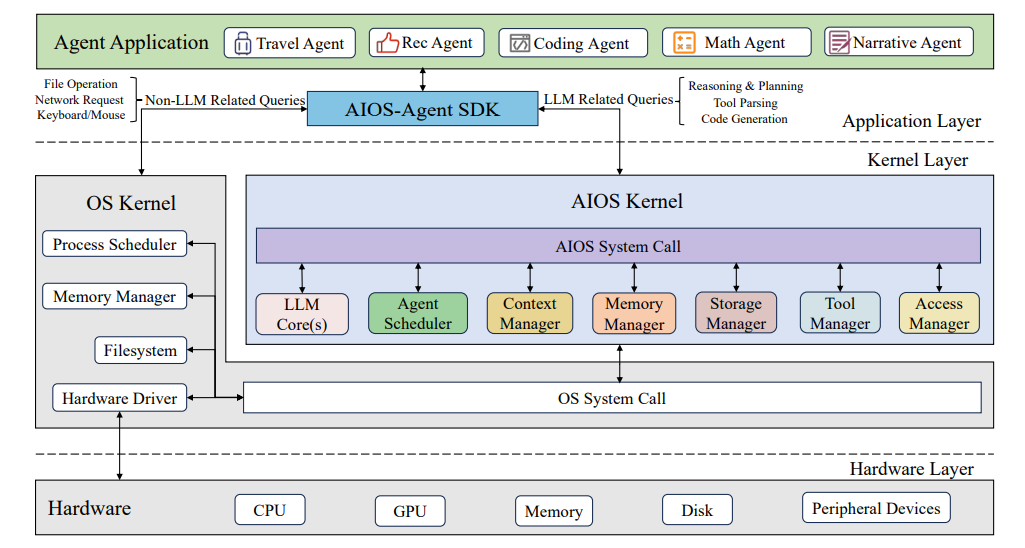
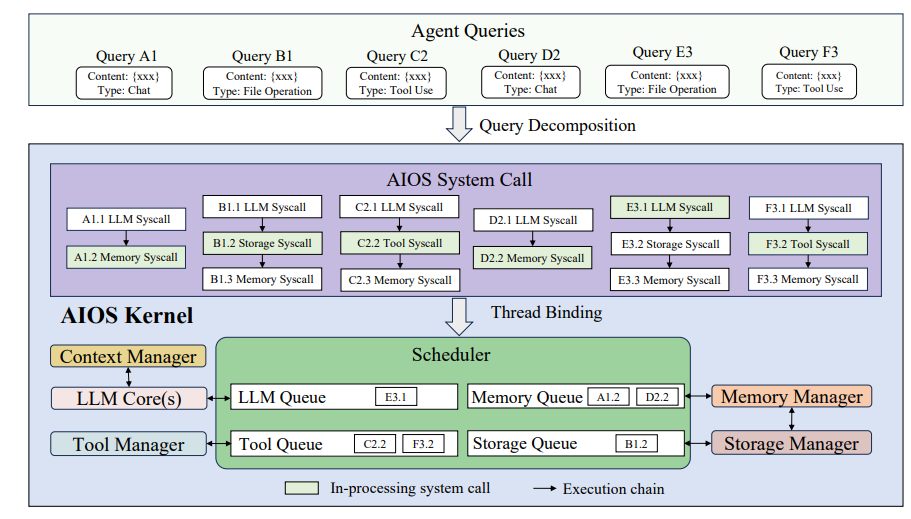
개인 의견: