ICLR 2026 selected
Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention
Motivation: 모델 배포시에는 BF16으로 하되 학습 자체는 FP32를 사용한다는게 당연한 상식 (정밀도가 떨어지므로 학습 시에라도 정밀도를 맞추자) 으로 통하고 있지만, 적어도 ‘왜 그런지’ 상세하게 파보자는 주장을 제기합니다.
주장 및 근거: high precision일 때의 query gradients와 low precision일 때의 gradient를 명시적으로 표현하고, formulize하면
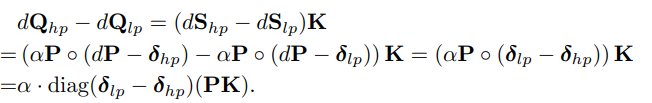
에서, PK 부분이 low precision에 의해 특정 벡터로 수렴하므로 학습이 진행되어도 유사한 형태를 띈다고 주장합니다.
개인 의견:
ACL 2026, Selected papers
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
기존 문제: long context attention의 sparse 구현은 대부분 inference 단계에서만 적용되어, training-inference 간 mismatch가 누적되거나 학습 자체가 unstable한 문제가 있었습니다. 또한 sparse pattern이 hardware에 friendly하지 않으면 이론상의 speedup이 실제 wall-clock 개선으로 이어지지 못한다는 한계도 있었습니다.
논문의 접근: 세 가지 attention pathway를 병렬로 두고, 각 pathway가 서로 다른 granularity를 담당하도록 설계했습니다.
- Compression: 멀리 떨어진 토큰들을 block 단위로 압축한 coarse summary token을 만들어 attention 대상에 포함합니다.
- Selection: block-level importance score를 기반으로 중요한 block만 골라 dense attention 대상에 포함합니다.
- Sliding window: 가장 최근 토큰들에 대해 dense local attention을 수행합니다.
세 pathway의 결과를 학습 가능한 gate로 weighted sum 합니다. 이 구조는 학습 단계부터 end-to-end로 sparse하게 학습되기 때문에 training-inference mismatch가 발생하지 않습니다.
Hardware-aligned implementation: Triton 기반 GPU kernel을 작성하여, GQA 환경에서 KV가 head 그룹 내에서 공유된다는 점을 활용해 blockwise memory access를 최적화했습니다. 이론상 speedup을 실제 latency 개선으로 옮기는 것이 핵심 목표입니다.
실험 결과: 64k context length 기준 forward/backward에서 최대 9×, decoding에서 최대 11.6× speedup을 보고합니다. MMLU/GSM8K/code 등 short benchmark에서는 full attention 대비 성능 손실이 거의 없고, LongBench와 long-CoT 평가에서는 오히려 더 좋은 성능을 보입니다. 27B parameter model까지 학습 검증을 했습니다.
개인 의견:
EMNLP 2026 Selected papers
Infini-gram mini: Exact n-gram Search at the Internet Scale with FM-Index
TL; DR: 텍스트 데이터를 인덱싱하기 위한 새로운 방법을 제안합니다.
기존 문제: 텍스트 인덱싱 알고리즘은 뭐… 좋은게 나오면 나올수록 당연히 좋습니다.
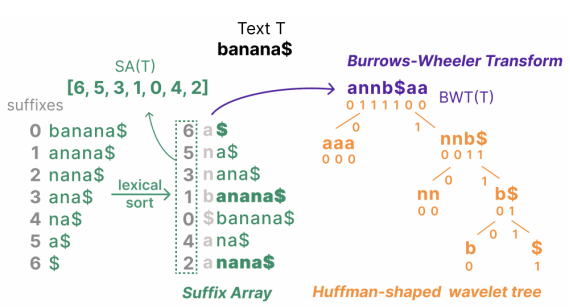
제안 방법: suffix array 대신 FM-Index (Burrows-Wheeler Transform 기반의 succinct full-text index) 를 사용해 인덱스 크기를 원본 텍스트와 비슷한 수준까지 줄였습니다. 그러면서도 임의 길이의 n-gram에 대해 exact frequency / occurrence position을 O(query length) 시간에 조회할 수 있습니다.
COLM 2026, ICLR 2026, AAAI 2026 selected
✨Unlearning-based Neural Interpretations
기존 문제: unlearning같은 방법은 Deep model safety 분야의 고전적이고 핵심적인 방법이지만, 의도치 않은 feature를 변경해버린다는 문제가 있습니다. 그래서 unlearning이 의도한 feature만 잊게 만드는지 확인하기 위해 ‘attribution’을 참고할 수 있는데, 공백의 이미지와 목표 이미지를 interpolation 해나가며 이것이 어떤 gradient를 형성하는지 관측하는 방법입니다. 이것을 Integrated Gradients라고 하고, 공백 이미지를 baseline이라고 합니다.
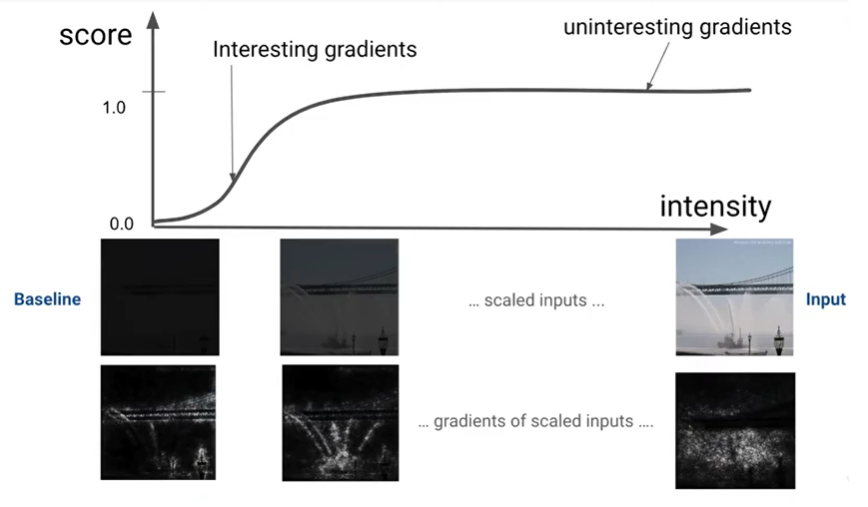
Integrated gradients는 단순하지만 효과적인 방법인데, baseline에서 조금만 목표 이미지로 보간되어도 금방 gradient map을 볼 수 있기 때문입니다. 기존에는 0.5로 보간하려다 gradient가 소멸되어서 제대로된 map을 볼 수 없었다고 하네요.
하지만 모델들은 모두 baseline에 bias가 있다는 문제가 있습니다. 검정 이미지는 전체적으로 검은 이미지를 나타내기 힘들거고, 가우시안 노이즈는 가우시안 필터링된 데이터에 취약할거고… 그 어떤 baseline을 쓰더라도 bias가 있기 때문에, 논문에서는 baseline으로 차라리 원본 이미지?를 쓰는게 낫다고 주장합니다.
논문의 직관: 하지만 baseline이 원본 이미지라니? 백번 양보해서 perturbation을 넣더라도 위 그림과 같이 엥간해서는 gradient map으로 visualize하기 위한 scaling 수치를 찾기 힘들겁니다. 그래서 논문에서는 어마어마한 발상을 해내는데,..
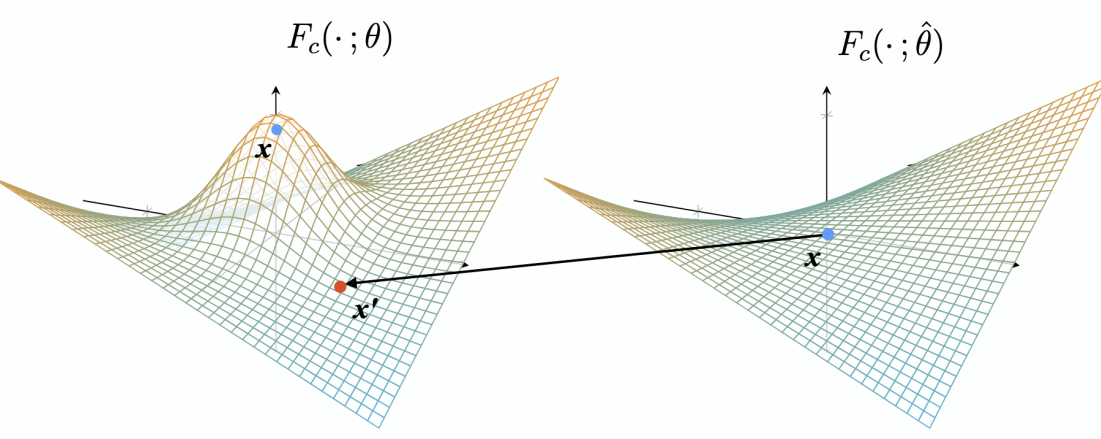
unlearned model은 목표 데이터 혹은 목표 클래스에 대해 잊도록 학습하는데, 처음에는 매우 뾰족한 probability density를 보이다가, 나중에는 처음부터 학습되지 않은 데이터마냥 representation space상에서 smooth한 지평선을 그리도록 학습됩니다. 이 때 unlearning gradient를 활용하기 어려운 이유는, 위 그림과 마찬가지로 어느 순간 probability density가 확 꺾여서 gradient scale도 확 꺾이기 때문입니다.
여기서 착안하여, 원본 모델 및 step 를 거쳐 unlearn되는 모델 를 가정할 때, 여기에 원본 데이터 x와 perturbed 데이터 를 넣을 때 KL divergence를 minimize 하는 를 찾습니다. 그 다음, 를 baseline으로 삼습니다. 이러면 unlearning을 일으키는 듯한 perturbation을 찾을 수 있고, 이는 곧 attack vulnerable이라고도 할 수 있습니다. 그러면 반대로도 말할 수 있겠죠? 주어진 모델이 robust한지 아닌지, 내가 입력한 데이터가 학습되었는지 아닌지 perturbation까지 고려해서 확인할 수 있다는 것입니다.
개인 의견: ICLR oral 퀄리티가 작년부터 너무 처참하게 무너졌나 싶었더니 그래도 하나 나오네요. 이 방법은 AI safety area에선 혁명과도 같은 연구가 아닐까 싶습니다. 게다가 attack method에도 agnostic하게 적용할 수 있는 방법이어서, 당분간은 모델, attack, defense 광범위한 분야의 metric으로 사용되지 않을까 싶네요.