2510, DeepSeek, DeepSeek-OCR: Contexts Optical Compression
TL; DR: 사진을 임베딩으로 변환 후 VLM에 입력함으로써 OCR을 수행하고, 심지어 같은 텍스트 데이터더라도 텍스트 토큰 임베딩보다 비전 패치 임베딩으로서의 효율이 더 좋을 수 있음을 시사합니다.
Pivot point: 기존 Multimodal model들이 vision embedding을 downsampling 하여 VLM에 입력한다는 점을 지적하고, 아예 downsample 없이 그대로 받을 수 있는 형태로 embedding을 전달합니다. 이는 RAE에서 지적한 부분과 상통됩니다.
실험 결과: 아주 놀라울 정도로 자연스럽게 연결되는 부분이 있는데, mode가 ‘토큰 압축률 혹은 해상도’ 에 해당한다고 한다면,
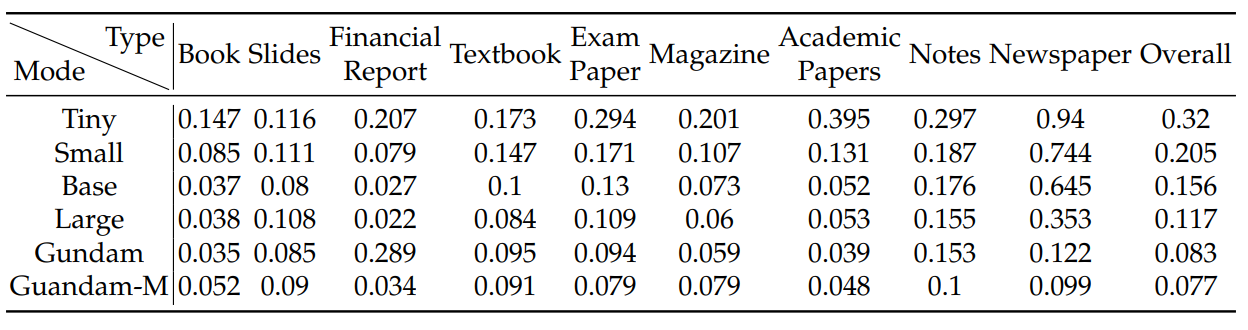
이와 같이 문서 종류에 따라 정밀도가 달라지는 모습을 볼 수 있습니다. 특히 책이나 슬라이드의 경우 base ~ gundam까지의 모델이 큰 차이가 나지 않는다는 것이 인상적입니다.
Another surprise:
‘이미지의 해상도’와 ‘텍스트 압축률’을 ‘기억의 해상도’와 연결짓는 부분을 제시하는데,
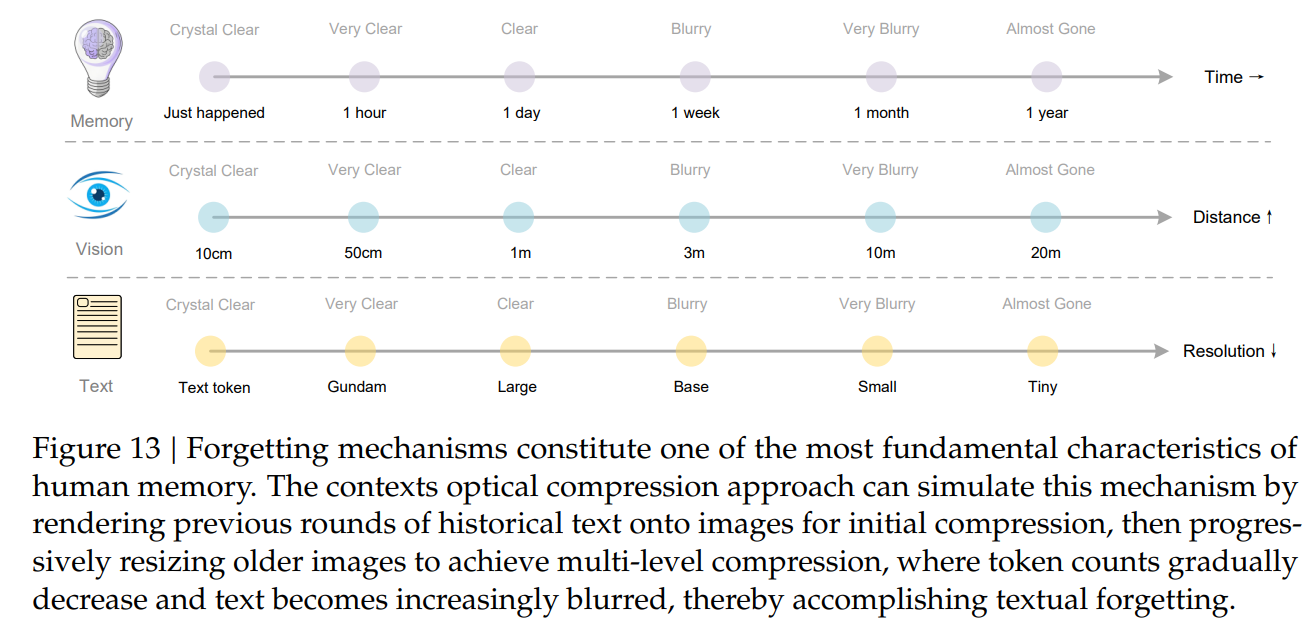
정말 놀랍습니다. 만약 이게 매끄럽게 연결될 수 있다면, attention 등을 온갖 짓을 다 해서 장기기억 문제를 해결하려던 시도들이 의외로 하나의 아키텍처만으로 해결될 수도 있겠습니다.
2508, Bytedance, DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
Core idea. DuPO reframes dual learning for LLM training: instead of inverting an entire input, it decomposes each input into known and unknown parts and defines a complementary dual task that reconstructs only the unknown part from the model’s output plus the known context. The reconstruction quality becomes a self-supervised reward for preference optimization—no human labels, no external verifiable answers. (arXiv) (arXiv)
1) Why it matters
- Breaks the supervision bottleneck. RLHF needs costly/variable human labels; RLVR needs gold answers and is limited to verifiable tasks. DuPO replaces both with intrinsic, model-generated feedback, applicable beyond strictly invertible task pairs. (arXiv)
- Generalizes dual learning. Classic dual learning assumes mutual invertibility (e.g., translation↔back-translation). DuPO formalizes a generalized duality over (known, unknown) components, mitigating non-invertibility and bidirectional skill asymmetry in LLMs. (arXiv)
- Unified training & inference utility. The same backward reconstruction signal works both during RL training and as an inference-time reranker (no finetuning), trading compute for accuracy. (arXiv)
2) How the experiments are done (and how thorough)
Setups & data.
- Models. Translation: Seed-X-7B-Instruct. Reasoning: DeepSeek-R1-Distill-Qwen-1.5B/7B, Qwen3-4B, OpenReasoning-Nemotron-7B; comparisons include ultra-large models (e.g., DeepSeek-R1, Claude-Sonnet4-Thinking, Doubao). (arXiv)
- Datasets. Translation covers 28 languages (1k prompts per language for training; 7k dev pairs from FLORES-200). Reasoning mixes public math sets; the paper details dual-question construction and filtering. (arXiv) (arXiv)
- DuPO math pipeline. From ~1.82M prompts → dedup to 318,649 primal questions → generate 1,059,671 dual questions; sample candidate answers with Qwen models; keep dual questions that are answerable and with unique correct answer among candidates. Hyperparams include 16 rollouts/prompt, batch 512, lr 1e-6. (arXiv)
Results.
- Translation. On 28-lang evaluation, DuPO lifts Seed-X-7B-Instruct by +2.13 COMET (also +BLEU, +BLEURT), averaging 64.66, competitive with strong closed or larger systems; human eval on a 14-direction challenge shows parity with GPT-4o/DeepSeek-R1 and clear margins over Google Translate. (arXiv)
- Math reasoning. Average gains of +6.4 points across AMC23, AIME24, AIME25 for multiple bases; e.g., Qwen3-4B rises to match/beat some ultra-large baselines. (arXiv)
- Training-free reranking. As an inference-time scheme, DuPO-style backward accuracy selection improves by ~+9.3 points on reasoning without any finetuning. (arXiv)
- Ablations. Removing the unknown-component selection harms performance; with it, +5–7 point improvements persist across model sizes—evidence that the generalized duality (and its filtering) is the key ingredient. (arXiv)
Thoroughness assessment.
- Cross-domain (translation + math), cross-scale (1.5B→7B), automatic + human eval for MT, clear ablations, and transparent RL details—overall solid empirical coverage. (arXiv)
3) Likely impact—plus a critical take on current research flows
Impact.
- A third path for alignment. Beyond RLHF (human) and RLVR (oracle), DuPO offers self-supervised preference optimization that could scale cheaply and broaden to semi-open-ended tasks (translation, code, dialogue), given an engineered complementary dual. (arXiv)
- Compute-for-quality at inference. The backward-check reranker is plug-and-play; small models can punch above their weight by paying extra sampling cost. (arXiv)
Critique of current flows (and DuPO’s weaknesses).
- Reward hacking risk moves, not vanishes. Because rewards come from model-instantiated dual questions, policies may learn to “leak” information useful for reconstruction rather than solve the primal task robustly (e.g., answer styles that ease backward inference). DuPO’s uniqueness/answerability filters help, but they’re heuristic and domain-specific. (arXiv)
- Engineering burden persists. The method still needs task-tailored unknown-component choices and dual-question generators. Section 7 shows careful templating/filters for math; extending to messy, open instruction following or safety-critical judgment tasks is non-trivial and acknowledged as future work. (arXiv)
- Compute & pipeline complexity. Building the math RL set required large-scale sampling and filtering (millions of prompts; two different Qwen passes), and training used 16 rollouts per prompt—cheaper than human labels but still significant. (arXiv)
- Scale/external validity. Most training results are on mid-scale (≤7B) open models; behavior on ≥70B frontier models and on truly open-ended creative tasks remains open, as the paper notes. (arXiv)
- MT evaluation nuances. COMET/BLEU/BLEURT and a targeted human study show gains, but broad, blind human eval at scale and robustness under distribution shift (low-resource, noisy domains) deserve scrutiny; back-translation-style duals in MT can mask adequacy/fluency trade-offs.
Bottom line
DuPO cleanly generalizes dual learning into a self-verification signal for preference optimization, delivering real gains in translation and math and a practical inference-time reranker. Its promise is high where you can construct reliable complementary duals; its limits appear where duals are hard to define, easy to game, or expensive to curate—key frontiers for follow-up work. (arXiv)
2507, Anthropic, Subliminal Learning: Language Models Transmit Behavioral Traits via Hidden Signals in Data
TL; DR: 사람이 인지 가능할 만큼 모델의 선호 경향을 바꾸는, ‘사람이 인지 불가능한 패턴’이 학습 데이터에 이식될 수 있습니다.
-
2505, Google, AlphaEvolve: A coding agent for scientific and algorithmic discovery
문제 배경 : multi agent system, orchestration 등 llm agent 개념은 이미 오래전에 나왔지만 좀처럼 실용적인 시스템이 나오지는 않았습니다. 이는 실제로 agent들을 굴리게 되면 inconsistency에서 비롯되는 다양한 문제들이 발생하기 때문입니다.
논문의 접근 : 아래와 같은 하이레벨 아키텍쳐를 제시합니다.
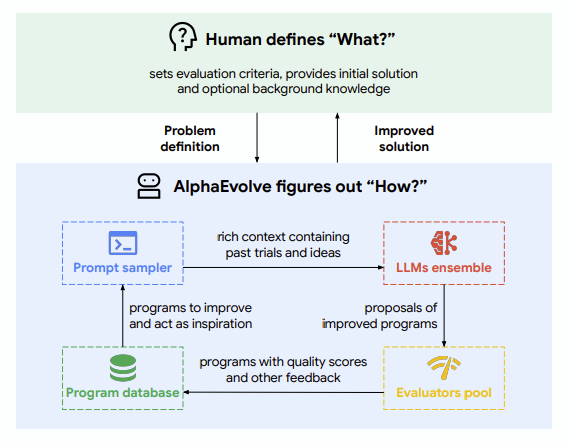
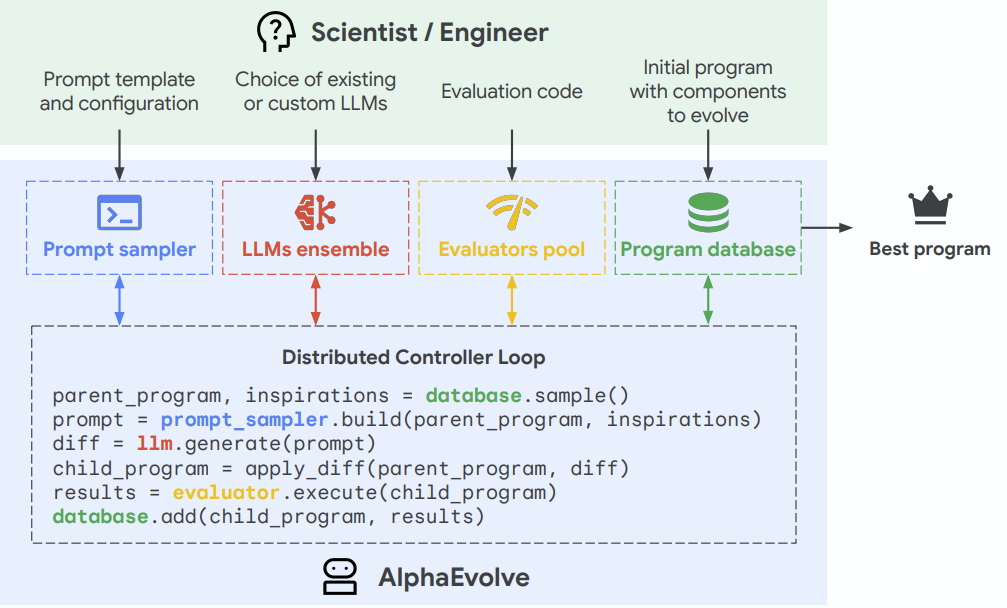
즉 기존 에이전트 시스템들과 대비해서 새롭게 제시된 방법은, 프롬프트와 프로그램을 샘플링하여 더 좋은 생성물을 채택하고 발전시킨다는 점입니다. 다만, 평가 방법은 여전히 정적인 코드나 에이전트, 사람 등에 의존합니다.
2503, Anthropic, Circuit Tracing: Revealing Computational Graphs in Language Models
문제 배경 : LLM을 해석하는 연구는 주로 input-output 레벨(자연어)거나, token distribution, 끽해야 어텐션 맵을 보는 정도였습니다. 그도 그럴 것이 그간의 locating, editing 연구들이 매우 어려운 과정을 거침에도 불구하고 싱거운 결과들만 남겨왔기도 했고, 내부 알고리즘 형태와 같이 새로운 접근법을 제시하는 연구들이 제시되어 직접적으로 transformers cell을 해석하려는 연구는 크게 눈에 띄지 않았습니다. 특히 그놈의 어텐션이 너무 큰 장해물로 작동했기 때문에, 최근에는 아예 하이퍼네트워크로써 해석해버리는 연구도 있었습니다.
논문의 접근 : residual network를 ensemble로 해석한 연구를 토대로, 보조 adapter 형태의 weight를 아래와 같이 배치합니다.
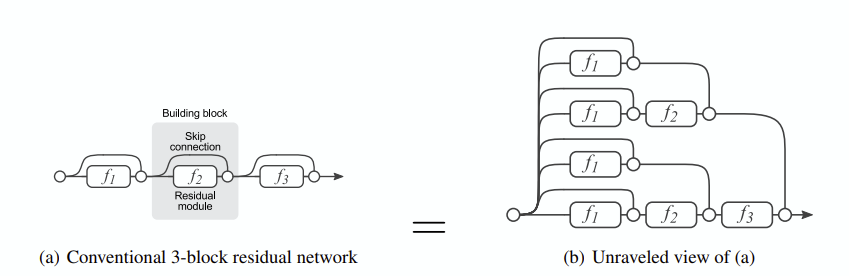
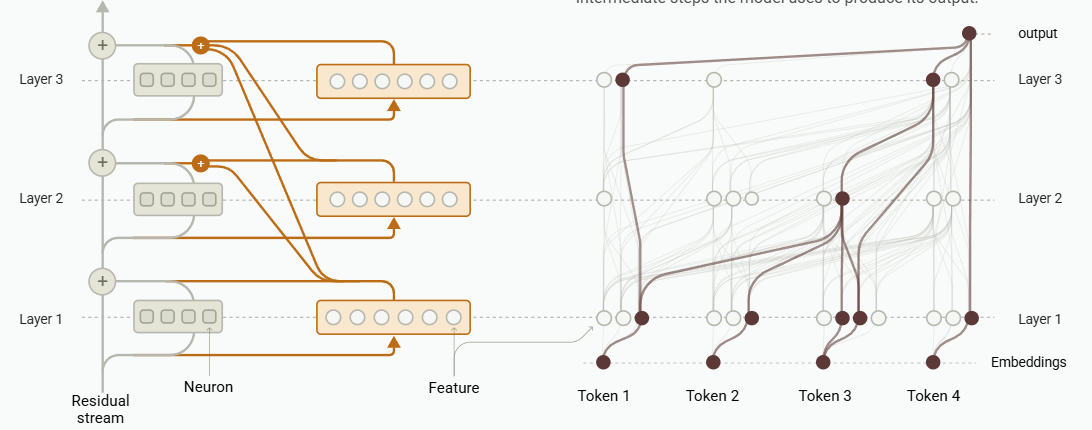
attention을 아예 배제해버린 형태라 다소 naive해 보일 수 있지만, 우측과 같이 Autoregressive model에 최적화된, “output에 기여하는” 혹은 “사고 과정” 을 해석하기에 좋은 도구임을 볼 수 있습니다. 논문에서는 이 추가 weight를 ‘CLT’라고 부릅니다.
CLT weight는 output layer의 MLP 결과값을 reconstruct하는 objective로 학습됩니다. attention 등의 상호작용을 추가 고려하기 위해 기존의 MLP보다 조금 더 큰 차원으로 구성됩니다. 이는 단순히 MLP 패턴을 파악하려고 하는게 아니라, 기존 레이어를 대체할 수 있는 능력을 갖게 하기 위함입니다. 레이어를 대체할 수 있다는 것은 곧 다양한 입력값에 대한 모델의 ‘state’를 layer 레벨에서 저장하고 재현할 수 있다는 것입니다.
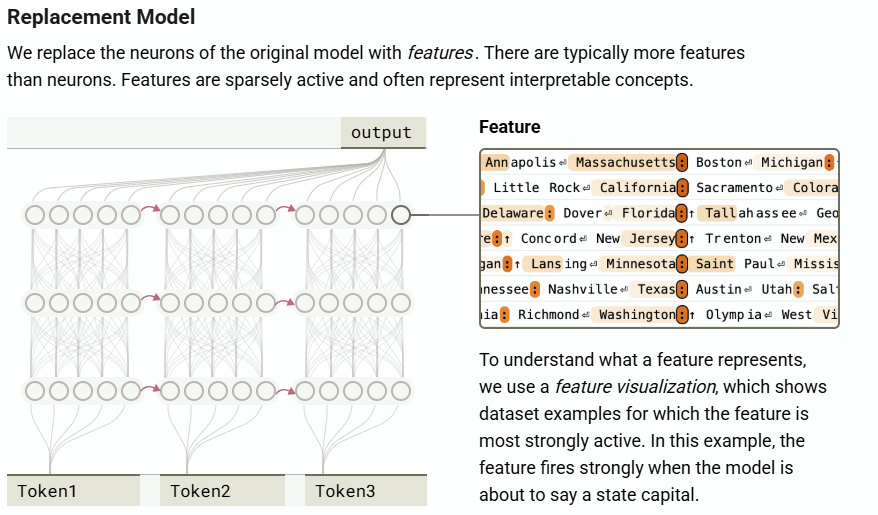
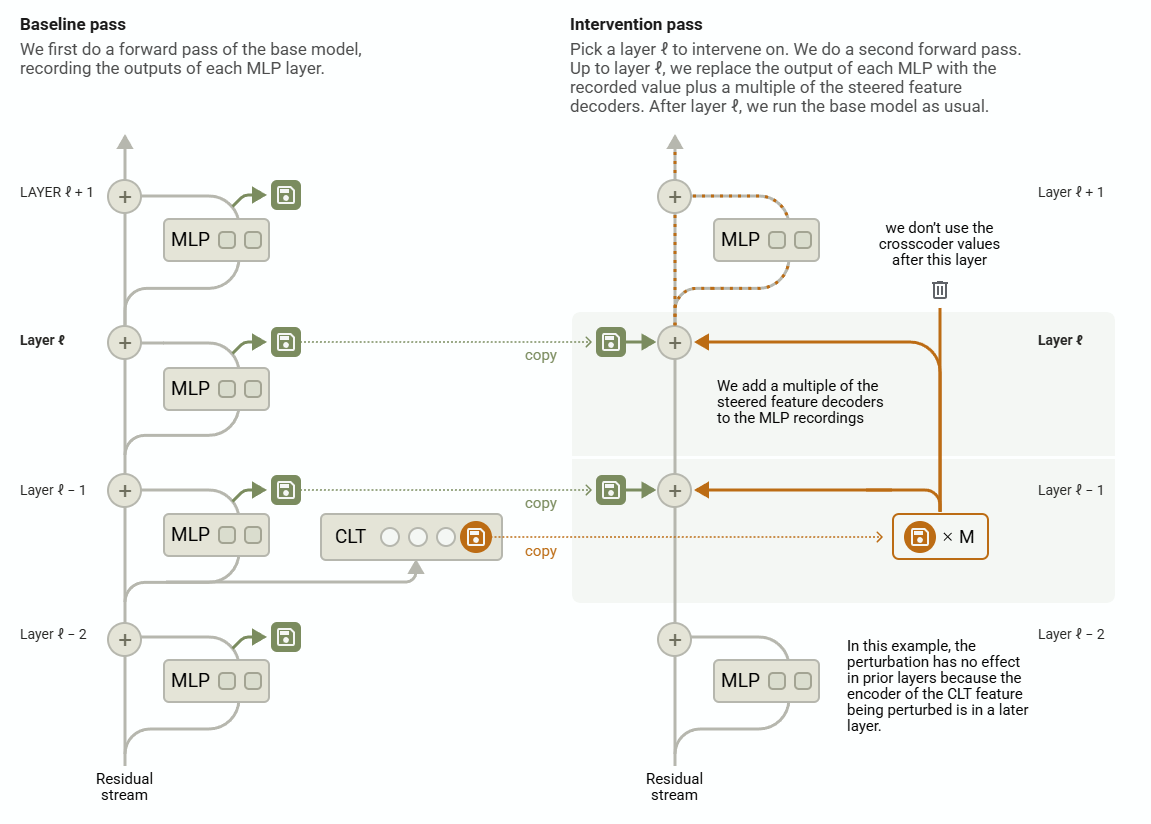
얼핏보면 어텐션을 배제한채로 트랜스포머 분석이 가능한가 싶지만, 요는 입출력 결과를 얻은 상태에서 이것저것 조작을 해보려는 목적이 선행된다는 것입니다. 따라서 어텐션 패턴만 저장해두고 feature들을 분석하는 방법을 제안하게 됩니다. 어텐션 패턴이 고정되어 있다면 단순 신경망의 forward같은 가벼운 연산으로 다양한 분석이 가능합니다.
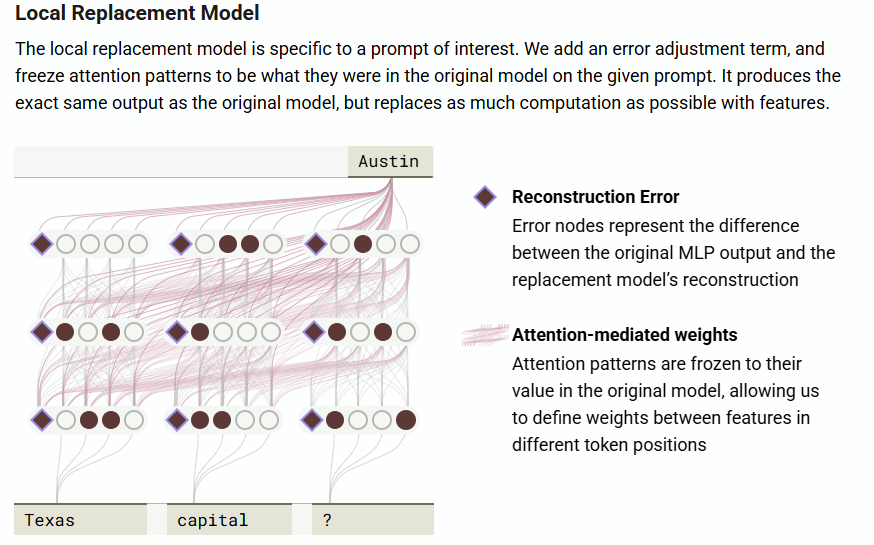
논문에서는 매우 다양한 데이터로 분석 결과를 도출했고, 이걸 시각화한 UI를 아예 아래 페이지에서 볼 수 있게 해놨습니다. 특히 attribution graph라는 시각화를 시도했는데, 영향력이 작은 feature나 연결부분을 제거하여 “레이어의 feature들 중 어떤 feature가 어떤 명령/추론에 해당하는지” 를 여러 화살표로 시각화했습니다.
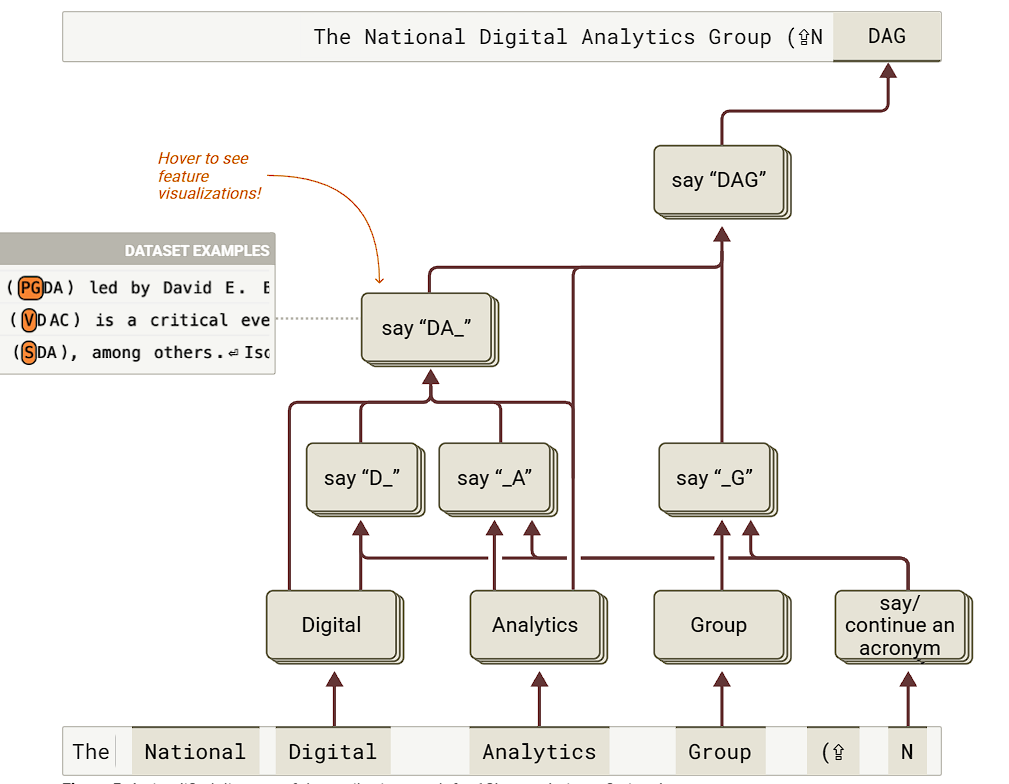
이 그래프를 보는 법은 다음과 같습니다.
- 모든 상호작용들은 입력된 텍스트 다음에 올 토큰을 추론하기 위함입니다.
- 네모 박스는 CLT feature들이 겹친것으로, 어떤 추론을 하는지로 생각해도 무방합니다.
- 화살표는 feature가 다른 feature에 영향을 끼치는 형태를
다만, Haiku 모델급에선 reconstruction error가 상당히 크게 발생해서 여러 특이한 어텐션 패턴을 재현하지는 못했습니다. 때문에 이런 경우를 아예 ‘induction head’라는 모듈로 정리하고자 했습니다.
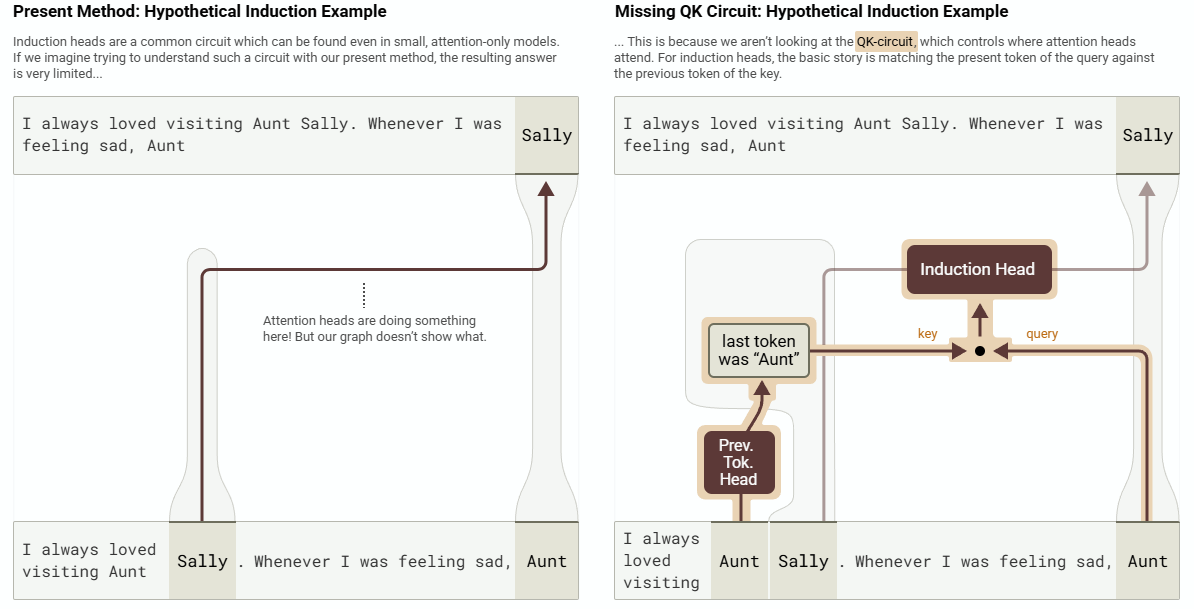
개인 의견 : SAE부터 시작해 여러 분석 방법을 쓰더라도 그 분석 내용을 보자면… 다소 자명해보이는 결론들이 도출되는것 같지만, 모두 혁신적인 아이디어를 통해 ‘transparent’하게 이해 가능한 도구를 만들어냈다는 점을 보면 큰 의의가 있습니다. 특히 이번 연구는 트랜스포머 구조에서 범용적으로 사용 가능한 ‘adapter’ 형태의 해석 도구 “CLT”를 내놓았다는 데 큰 의의가 있습니다.
다만, 1) CLT 학습에는 원본 모델 학습량의 50%정도가 필요하다는 점, 2) 어텐션이 만들어내는 특수한 패턴을 재현하기는 어렵다는 점 등을 볼 때, 어떤 특수한 패턴을 ‘저장된 state’로 도출해내는 과정에서 큰 실수가 발생할 수 있을 것으로 사료됩니다. 그래도 해석 연구에 있어서는 큰 진전이라고 생각합니다.
2503, Anthropic, Auditing language models for hidden objectives
2502, DeepSeek, Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
기존 문제: long context attention의 sparse 구현은 대부분 inference 단계에서만 적용되어, training-inference 간 mismatch가 누적되거나 학습 자체가 unstable한 문제가 있었습니다. 또한 sparse pattern이 hardware에 friendly하지 않으면 이론상의 speedup이 실제 wall-clock 개선으로 이어지지 못한다는 한계도 있었습니다.
논문의 접근: 세 가지 attention pathway를 병렬로 두고, 각 pathway가 서로 다른 granularity를 담당하도록 설계했습니다.
- Compression: 멀리 떨어진 토큰들을 block 단위로 압축한 coarse summary token을 만들어 attention 대상에 포함합니다.
- Selection: block-level importance score를 기반으로 중요한 block만 골라 dense attention 대상에 포함합니다.
- Sliding window: 가장 최근 토큰들에 대해 dense local attention을 수행합니다.
세 pathway의 결과를 학습 가능한 gate로 weighted sum 합니다. 이 구조는 학습 단계부터 end-to-end로 sparse하게 학습되기 때문에 training-inference mismatch가 발생하지 않습니다.
Hardware-aligned implementation: Triton 기반 GPU kernel을 작성하여, GQA 환경에서 KV가 head 그룹 내에서 공유된다는 점을 활용해 blockwise memory access를 최적화했습니다. 이론상 speedup을 실제 latency 개선으로 옮기는 것이 핵심 목표입니다.
실험 결과: 64k context length 기준 forward/backward에서 최대 9×, decoding에서 최대 11.6× speedup을 보고합니다. MMLU/GSM8K/code 등 short benchmark에서는 full attention 대비 성능 손실이 거의 없고, LongBench와 long-CoT 평가에서는 오히려 더 좋은 성능을 보입니다. 27B parameter model까지 학습 검증을 했습니다.
개인 의견:
2502, Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
“수학을 위한 특별한 tokenizer는 필요하지 않을 수도 있습니다.“
연관 트렌드 : Neuro-symbolic (딥러닝과 규칙기반을 적절하게 혼합하는 방법), LLM-friendly languages

기존 모델 : 문제를 특화 언어로 번역합니다. 이 과정을 formalization이라 부르는데, 비전 언어모델(VL) 없이도 기하학 문제를 텍스트 형태로 나타낼 수 있어 LLM의 힘을 활용하기 좋은 방법입니다. 다만 효율적인 특화 언어를 위해서는 최대 입력변수를 2개로 한정할 필요가 있어, 여러 개선안을 적용했습니다.
주요 성능 개선안
-
기존에 애매한 formalization 규칙을 일부 수정 (성능 대폭 개선)
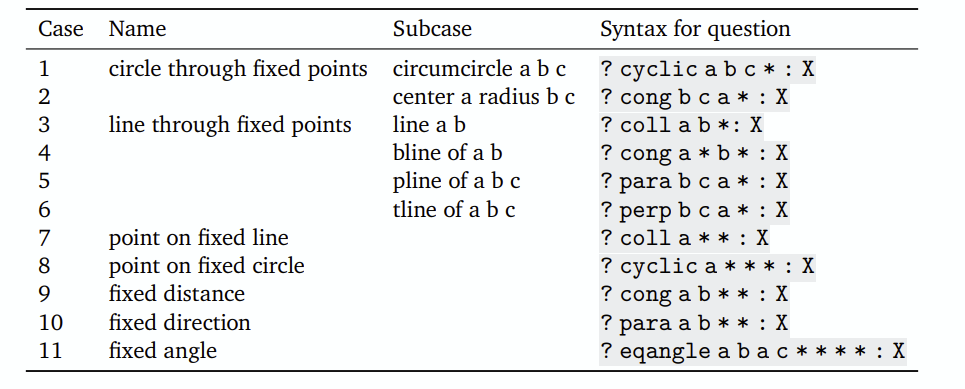
-
formulize된 수식들을 diagram 형태로 자동 변환하여 연산. 이 때 diagram은 주어진 constraint를 만족하는 coordinate가 무엇인지 유추하는 과정을 통해 생성하는데, SGD 이후 loss가 어느정도 감소하면 수치해석 방법으로 정확한 해를 도출.
-
어떤 교차점이 또 다른 초평면에 놓여 있을 때, 이를 cot 등의 연쇄과정 대신 cyclic한 탐색이 이루어지는지 검사
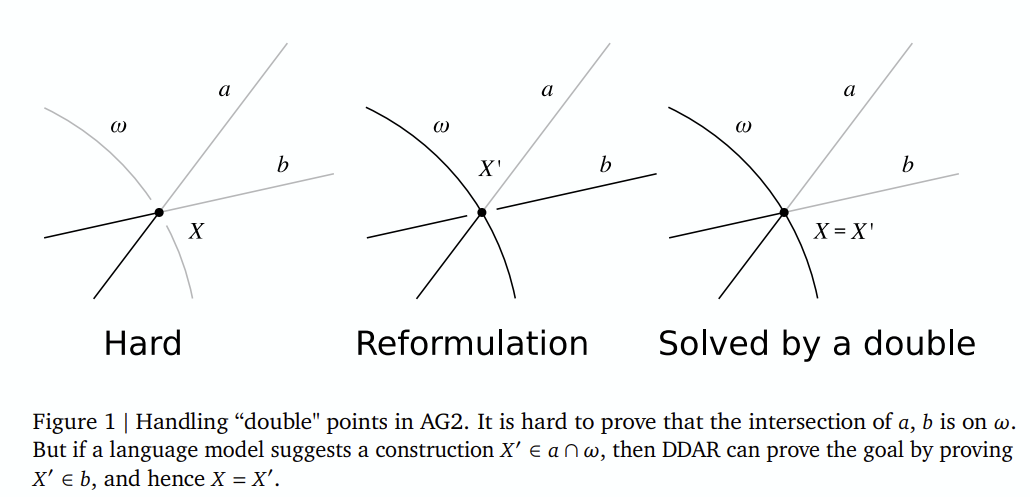
-
더 다양한 augmentation을 수행하여 synthetic data를 생산
부록에 실린 여러 실험가설
모델이 충분한 수의 토큰과 알고리즘으로 학습되었다면, 수학문제(특정 도메인) 특화 토크나이저가 유의미한 성능 향상을 가져오진 않는다.
-
2501, Sora : Video generation models as world simulators
Intro : OpenAI의 논문과 이를 리버싱 엔지니어링하여 분석한 논문이 있습니다. OpenAI의 논문은 너무 naive하고 overly simplify한 면이 있기 때문에, 후자를 참고했습니다. 아래 그림은 Sora를 이해하기 위한 기술 및 활용 논문 구성입니다.
이처럼 굉장히 많은 테크닉이 들어가기 때문에, 본 요약은 필수적인 구성요소로 생각되는 부분에 대해서만 작성되었습니다.
논문이 이끌어낸 직관 : 불과 4년 전만 하더라도, 언어 모델은 text-only environment에 존재하기 때문에 시각, 물리효과, agent간의 interaction 등 환경 요소를 추가해야 할 것이라는 주장이 제기되었었습니다(해당 논문), 그러나 본 논문에서는 Video model을 통해 real world environment에서 얻을 수 있는 정보를 학습할 수 있다고 주장합니다.
개략적인 구조
상세 구조
Multihead attention pooling : attention head별 다른 레벨의 weight decay를 적용하여 어떤 head가 잘 attend하는지 판단하도록 하고, pooling으로 정보를 취사선택합니다.
기존 문제 : AGI와 ASI라는 용어는 아직 그 기준이 모호한데다, 이를 달성하기 위한 조건에 대해 직관적이고 논리적인 서술은 그다지 주목받지 못했습니다.
논문이 이끌어낸 직관 : Diffusion transformer가 핵심 모델로 사용되었습니다.
Diffusion transformer learning with Masking
상세 설명 : Video frame → Visual representation → Spacetime latent patches → Diffusion transformer (denoising) → Decoded frame.
- Spatial-temporal-patch compression : 비디오는 프레임 진행에 따라 변화하는 부분과 변화하지 않는 부분이 명확하게 구분됩니다. 이를 활용하기 위해 3D convolution을 사용했습니다.
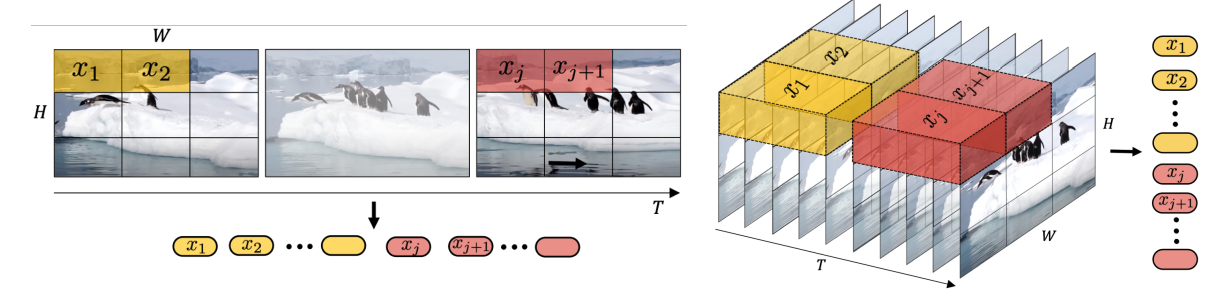
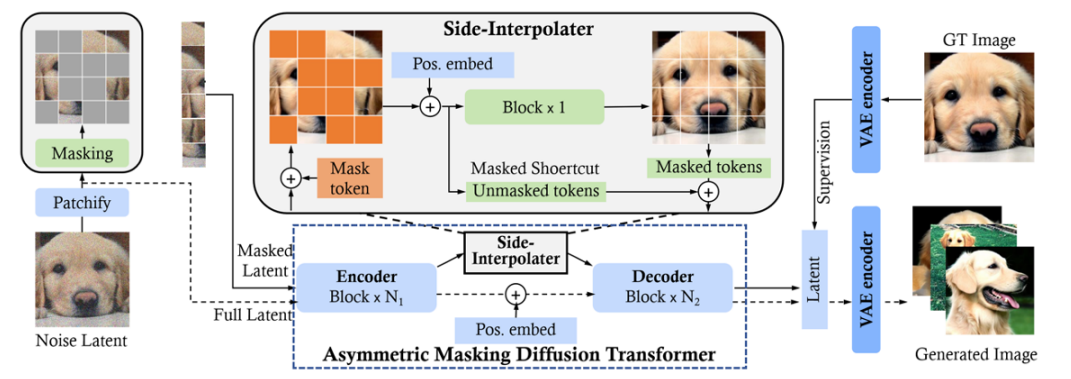
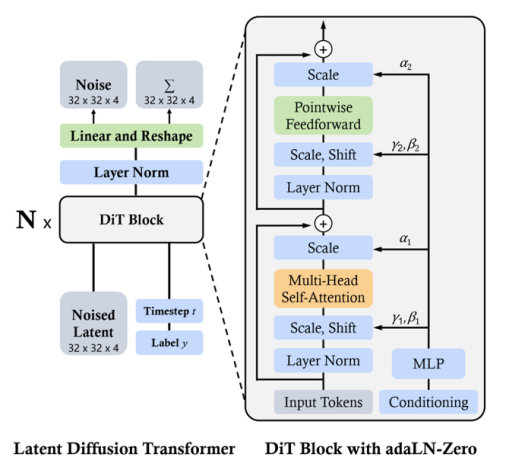
- Diffusion transformer : Diffusion 과정을 transformer를 통해 수행함으로써, Condition이나 Label을 자유롭게 페어링할 수 있게 했습니다.
개인 의견 :