Among the research papers published in the last three months, I picked out the ones that haven't yet hardened into industry standards but seem likely to become "the next direction" — or at least carry a lot of potential.
The three criteria I cared about:
- Is it intuitive? — Does the idea click in your head right away?
- Is it simple? — Is it easy to implement or extend?
- Is it realistic? — Does it feel like "someone could actually use this soon"?
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
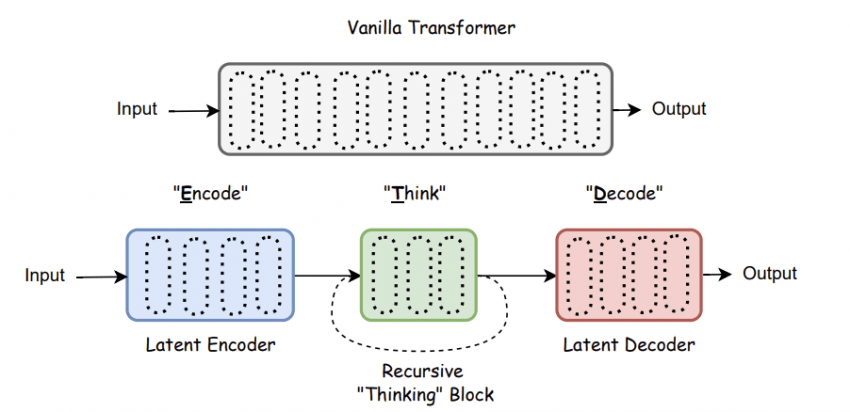
One-line summary: Instead of stretching out reasoning as a long stream of tokens, run the brain (intermediate layers) several times to think more deeply.
Analogy:
Typical LLM "reasoning" feels like talking to yourself at length (long chains) to solve a problem. The longer it goes, the more the words tangle up (long-form degradation), and the cost grows.
This work flips it around: instead of stretching the monologue, the same reasoning circuit is reused multiple times. It's closer to mulling something over a few extra times in your head rather than padding the explanation with words.
Why it matters:
- It can reduce the dependence on "reasoning data / chains" needed to build reasoning ability,
- It avoids the quality drop that comes from stretching out token sequences, and
- It lets the "more compute at test time = smarter model" direction be expressed more cleanly at the architectural level.
Realistic adoption:
Meta recently applied a similar idea in Olmo2, and it's encouraging that experiments are starting to follow the idea beyond the paper level.
Open risks:
- Repeating layers can ultimately add inference latency,
- And it still needs broader validation on which tasks actually benefit (math / coding / common sense / dialogue, etc.).
Auto-Compressing Networks
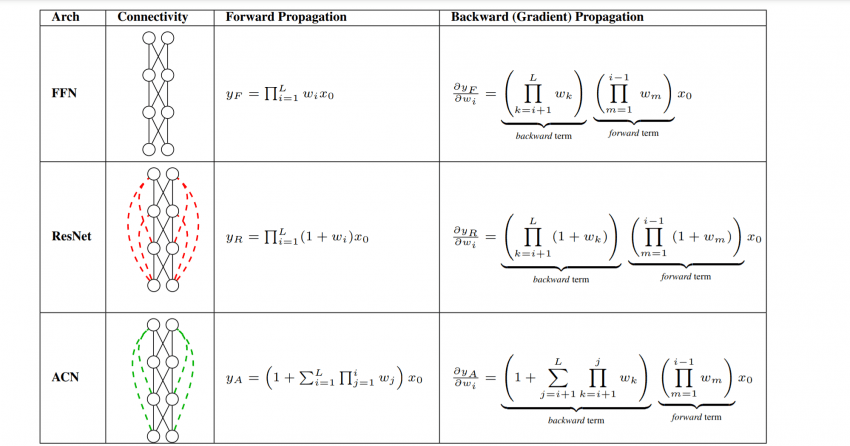
One-line summary: Instead of feeding the residual to "the next layer," route it directly to the final layer. Surprisingly, this trains well.
Analogy:
A residual connection is usually like a "side door (shortcut)" — it helps the gradient flow back through deep models.
The conventional approach is to attach a side door at every layer. This paper takes a bolder route — drop the per-layer side doors, and instead build a single express elevator from the first layer straight up to the top.
Why it matters:
- If a structure this simple still distributes the gradient well,
- it shakes the default assumption that "residual connections must exist at every layer."
- If it sticks, the conventions of model architecture design itself could shift.
Realistic adoption:
The idea is simple, so experiments and ports tend to spread quickly. "Even slightly better numbers" is enough for a lot of people to try it.
Open risks:
- Because it's so simple, it could turn out to be "a trick that only works under specific conditions" (certain normalizations / scalings / depths / data scales),
- and stability and optimization interactions in large LLMs need further validation.
Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
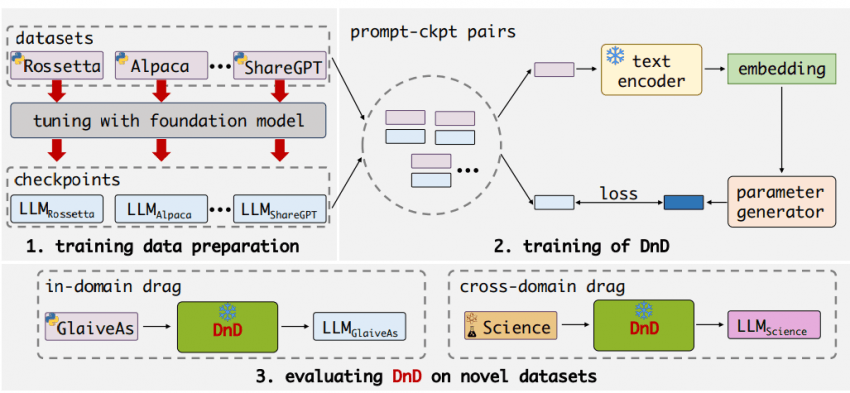
One-line summary: Instead of training a LoRA from data, build a model that, given a prompt, "generates" the LoRA adapter (weights). In some cases it even outperforms the trained LoRA.
Analogy:
Conventional LoRA is like "tutoring (training data) the student (model)." This work is closer to "skip the tutoring, look at the type of test, and synthesize the right problem-solving habits (adapter) on the spot." It solves the problem with design (generation) instead of training (learning).
Why it matters:
- It can drastically reduce fine-tuning bottlenecks (data prep, training cost, repeated experiments),
- and it makes flows like "companies offering fine-tuning as an API" much easier.
- Practical examples like Qwen Image-to-LoRA starting to appear is a fairly strong signal.
Realistic adoption:
If this really lands reliably, the frame "fine-tuning = training" gets shaken — which has a big industrial ripple effect, since the cost structure changes.
Open risks:
- Consistency / reproducibility of the generated adapters (does the same setup produce the same performance?),
- Long-term stability out-of-distribution,
- And from a safety angle, "unwanted capabilities" could be attached just as easily, so some control may be needed.
mHC: Manifold-Constrained Hyper-Connection
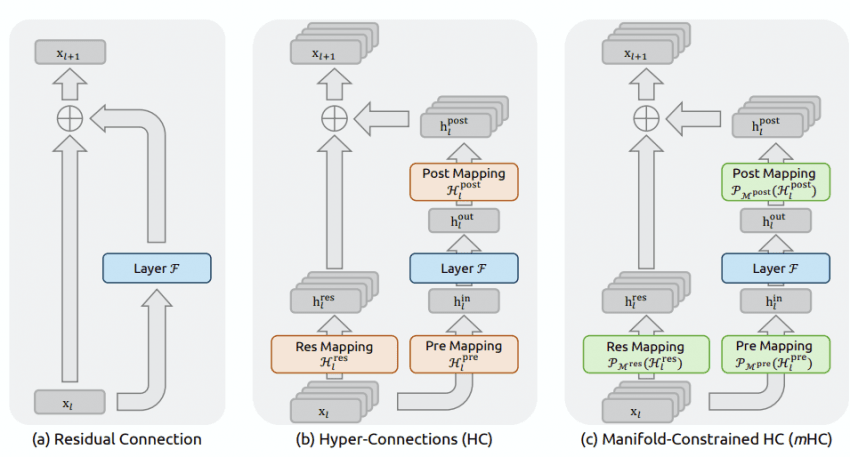
One-line summary: Split the representation carried by the residual into n parts so it's easier to handle in parallel, and push the parallel-compute ceiling further.
Analogy:
If the conventional residual is one "thick pipe," mHC feels like splitting that pipe into several smaller water lines. Then the water (information) can flow in parallel, making concurrent processing easier and reducing the chokepoints.
Why it matters:
The speed problem with today's large models is just as much "how well do we parallelize" as "how smart is the model." If approaches like mHC settle in, they can directly impact serving speed and cost — which matter especially for production LLMs.
Realistic adoption:
The point that "training stability is absurdly good, so it could be applied soon" is a really strong signal in this kind of work. In the field, "stable" is often a bigger reason for adoption than "slightly better."
Open risks:
- Parallelism doesn't end at theory — in practice it tangles with communication / memory / hardware layouts, and that's where performance is decided.
- If implementation complexity grows, "good but operationally awkward" can delay adoption.
WeDLM: Reconciling Diffusion Language Models with Standard Causal Attention for Fast Inference
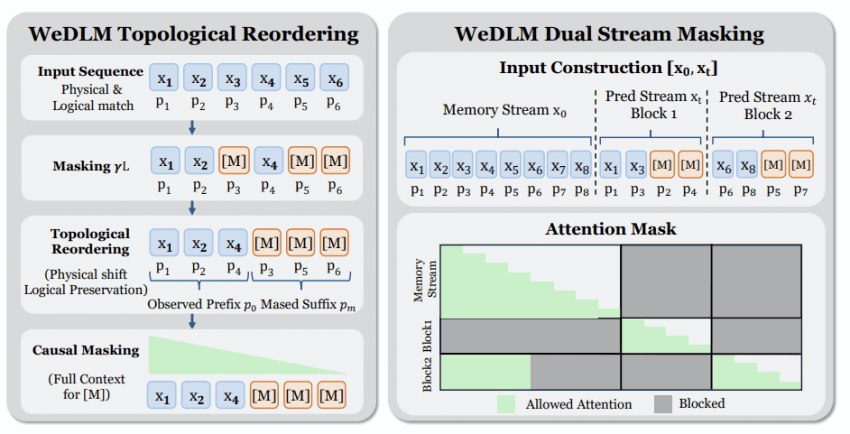
One-line summary: Instead of generating one token at a time (autoregressive), let existing LLMs generate via diffusion (progressive refinement) for faster inference. They report 3–10× speedups while preserving quality.
Analogy:
An autoregressive LLM writes like typing — one character / one word at a time, in order. Diffusion is a bit different: it sketches a rough, blurry draft first, then sweeps over it several times to sharpen it. When that works, the "advance one slot at a time, in order" constraint loosens, and you can push speed higher.
Why it matters:
- It's meaningful because it changes the generation method to attack the inference-speed bottleneck head-on, without throwing out the existing LLM structure (especially causal attention).
- For the open-source LLM ecosystem in particular, "serving speed" is competitive on par with "model quality," so the ripple could be large.
Realistic adoption:
Training cost was substantial, but if the report — speedup without quality loss — holds up, it's the kind of work where "teams will copy fast" follow.
Open risks:
- Diffusion generation can swing significantly in quality and speed depending on sampling schedule / step count,
- And whether quality holds up across specific tasks (long context, precise math / coding) needs more confirmation in general.
The overall trend I'm seeing
Today's "next-generation improvement" candidates seem to cluster into roughly five lanes:
- Smarter internal computation — don't stretch reasoning into long words; reuse layers (Recurrent Depth)
- Rethinking connections — reconsider residuals that we've been taking for granted (Auto-Compressing)
- From training to generation — from the era of training weights to the era of generating them (Prompt-to-Weights)
- Structural parallelism — solve parallelism / stability at the architecture level (mHC)
- A new generation paradigm — touch speed via diffusion instead of autoregression (WeDLM)